
有时在数据集中, 我们会遇到包含没有特定优先顺序的数字的列。列中的数据通常表示类别或类别的值, 并且在列中的数据经过标签编码时也是如此。这会混淆机器学习模型, 为避免这种情况, 列中的数据应进行一次热编码。
一种热编码–
它是指拆分包含数字的列分类数据到许多列, 具体取决于该列中存在的类别数量。每列包含对应于其放置在哪一列的" 0"或" 1"。
例如 :
考虑给出水果及其相应分类价值和价格的数据。
| 水果 | 水果的分类价值 | 价钱 |
|---|---|---|
| 苹果 | 1 | 5 |
| 芒果 | 2 | 10 |
| 苹果 | 1 | 15 |
| 橙子 | 3 | 20 |
对数据进行一次热编码后的输出如下所示:
| 苹果 | 芒果 | 橙子 | 价钱 |
|---|---|---|---|
| 1 | 0 | 0 | 5 |
| 0 | 1 | 0 | 10 |
| 1 | 0 | 0 | 15 |
| 0 | 0 | 1 | 20 |
以下是Python中的实现-
示例1:
下面的示例是区域的数据和客户的信用评分, 区域是一个分类值, 需要进行一次热编码。
# Program for demonstration of one hot encoding
# import libraries
import numpy as np
import pandas as pd
# import the data required
data = pd.read_csv(r "../../onehotenc_data.csv" )
print (data)输出如下:
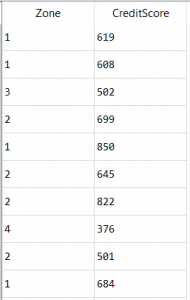
一个热编码区域列–
# importing one hot encoder from sklearn
# There are changes in OneHotEncoder class
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
# creating one hot encoder object with categorical feature 0
# indicating the first column
columnTransformer = ColumnTransformer([( 'encoder' , OneHotEncoder(), [ 0 ])], remainder = 'passthrough' )
data = np.array(columnTransformer.fit_transform(data), dtype = np. str )输出如下:
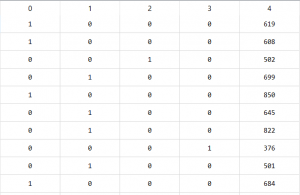
输出包含5列, 其中一列表示价格, 其余4列表示4个区域。
示例2:
一个热编码器仅采用数字分类值, 因此任何字符串类型的值都应在"一热"编码之前进行标签编码。
以下示例包含客户的地理位置和性别数据, 必须首先对其进行标签编码。
# importing libraries
import numpy as np
import pandas as pds
# After importing the required data
print (data)输出如下:
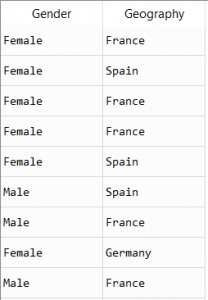
标签编码数据–
# label encoding the data
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data[ 'Gender' ] = le.fit_transform(data[ 'Gender' ])
data[ 'Geography' ] = le.fit_transform(data[ 'Geography' ])输出如下:
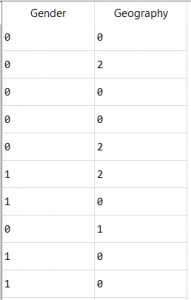
一本热门的性别和地理编码专栏–
# importing one hot encoder from sklearn
from sklearn.preprocessing import OneHotEncoder
# creating one hot encoder object by default
# entire data passed is one hot encoded
onehotencoder = OneHotEncoder()
data = np.array(columnTransformer.fit_transform(data), dtype = np. str )输出如下:
输出包含5列, 其中2列分别代表性别, 男性和女性, 其余3列分别代表法国, 德国和西班牙。
注意 :
- 一个热编码器不接受一维数组或熊猫序列, 输入应始终为二维。
- 传递给编码器的数据不应包含字符串。
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。

