
本文带你了解如何使用 PyMuPDF 库通过 Python 突出显示、加框、下划线、删除线和编辑 PDF 文件中的文本,包括详细的Python突出显示和编辑PDF文本示例。
突出显示或注释 PDF 文件中的文本是阅读和保留关键信息的绝佳策略。这种技术有助于将重要信息立即引起读者的注意。毫无疑问,以黄色突出显示的文本可能会首先引起你的注意。
编辑 PDF 文件可让你隐藏敏感信息,同时保持文档的格式。这会在共享之前保留私人和机密信息。此外,它还进一步提高了组织在处理敏感信息时的完整性和可信度。
在本教程中,你将学习如何使用 Python 编辑、加框或突出显示 PDF 文件中的文本。
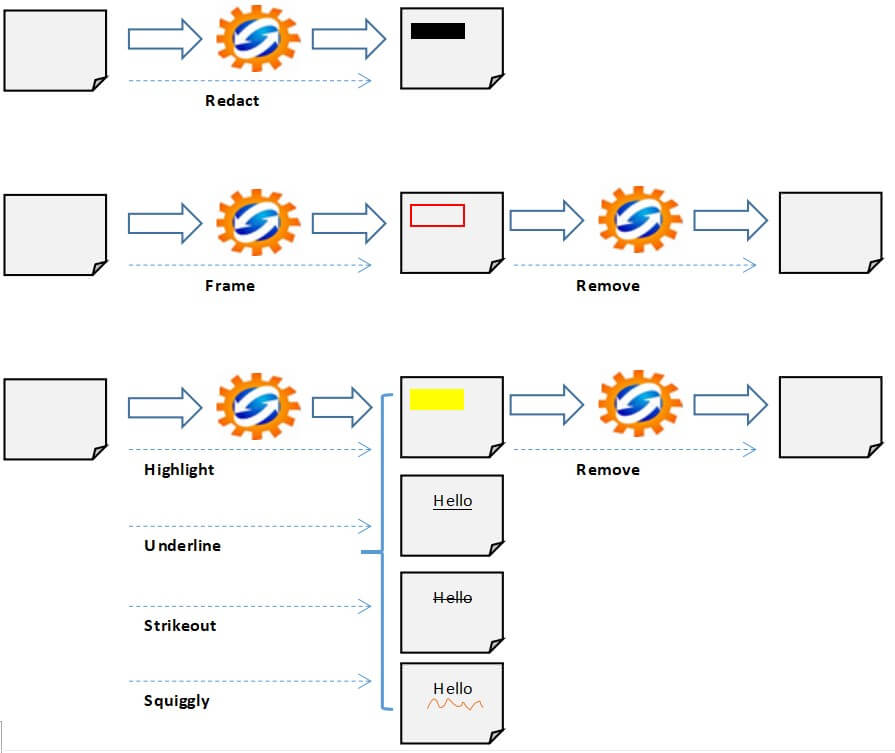
Python如何突出显示和编辑PDF文本?在本指南中,我们将使用PyMuPDF 库,这是一个高度通用的、可定制的 PDF、XPS 和电子书解释器解决方案,可在广泛的应用程序中用作 PDF 渲染器、查看器或工具包。
本教程的目标是开发一个基于命令行的轻量级实用程序,用于编辑、加框或突出显示包含在一个 PDF 文件或包含一组 PDF 文件的文件夹中的文本。此外,它还可以让你从 PDF 文件或 PDF 文件集合中删除突出显示。
让我们安装要求:
$ pip install PyMuPDF==1.18.9打开一个新的 Python 文件,让我们开始吧:
# Import Libraries
from typing import Tuple
from io import BytesIO
import os
import argparse
import re
import fitz
def extract_info(input_file: str):
"""
Extracts file info
"""
# Open the PDF
pdfDoc = fitz.open(input_file)
output = {
"File": input_file, "Encrypted": ("True" if pdfDoc.isEncrypted else "False")
}
# If PDF is encrypted the file metadata cannot be extracted
if not pdfDoc.isEncrypted:
for key, value in pdfDoc.metadata.items():
output[key] = value
# To Display File Info
print("## File Information ##################################################")
print("\n".join("{}:{}".format(i, j) for i, j in output.items()))
print("######################################################################")
return True, outputextract_info()功能收集了PDF文件的元数据,可以提取的属性format,title,author,subject,keywords,creator,producer,creation date,modification date,trapped,encryption,和页数。值得注意的是,当你针对加密的 PDF 文件时,无法提取这些属性。
def search_for_text(lines, search_str):
"""
Search for the search string within the document lines
"""
for line in lines:
# Find all matches within one line
results = re.findall(search_str, line, re.IGNORECASE)
# In case multiple matches within one line
for result in results:
yield result这对使用文档线内的字符串函数的搜索re.findall()功能,re.IGNORECASE是忽略的情况,而搜索。
def redact_matching_data(page, matched_values):
"""
Redacts matching values
"""
matches_found = 0
# Loop throughout matching values
for val in matched_values:
matches_found += 1
matching_val_area = page.searchFor(val)
# Redact matching values
[page.addRedactAnnot(area, text=" ", fill=(0, 0, 0))
for area in matching_val_area]
# Apply the redaction
page.apply_redactions()
return matches_found该函数执行以下操作:
- 遍历我们正在搜索的搜索字符串的匹配值。
- 编辑匹配的值。
- 在所选页面上应用修订。
你可以使用方法fill上的参数更改编校的颜色page.addRedactAnnot(),将其设置为(0, 0, 0)将导致黑色编校。这些是范围从 0 到 1 的RGB 值。例如,(1, 0, 0)将导致红色编辑等。
def frame_matching_data(page, matched_values):
"""
frames matching values
"""
matches_found = 0
# Loop throughout matching values
for val in matched_values:
matches_found += 1
matching_val_area = page.searchFor(val)
for area in matching_val_area:
if isinstance(area, fitz.fitz.Rect):
# Draw a rectangle around matched values
annot = page.addRectAnnot(area)
# , fill = fitz.utils.getColor('black')
annot.setColors(stroke=fitz.utils.getColor('red'))
# If you want to remove matched data
#page.addFreetextAnnot(area, ' ')
annot.update()
return matches_found该frame_matching_data()函数在匹配值周围绘制一个红色矩形(框)。
接下来,让我们定义一个函数来突出显示文本:
def highlight_matching_data(page, matched_values, type):
"""
Highlight matching values
"""
matches_found = 0
# Loop throughout matching values
for val in matched_values:
matches_found += 1
matching_val_area = page.searchFor(val)
# print("matching_val_area",matching_val_area)
highlight = None
if type == 'Highlight':
highlight = page.addHighlightAnnot(matching_val_area)
elif type == 'Squiggly':
highlight = page.addSquigglyAnnot(matching_val_area)
elif type == 'Underline':
highlight = page.addUnderlineAnnot(matching_val_area)
elif type == 'Strikeout':
highlight = page.addStrikeoutAnnot(matching_val_area)
else:
highlight = page.addHighlightAnnot(matching_val_area)
# To change the highlight colar
# highlight.setColors({"stroke":(0,0,1),"fill":(0.75,0.8,0.95) })
# highlight.setColors(stroke = fitz.utils.getColor('white'), fill = fitz.utils.getColor('red'))
# highlight.setColors(colors= fitz.utils.getColor('red'))
highlight.update()
return matches_found上述函数根据作为参数输入的突出显示类型对匹配值应用适当的突出显示模式。
Python如何突出显示和编辑PDF文本?你始终可以使用highlight.setColors()注释中所示的方法更改突出显示的颜色。
def process_data(input_file: str, output_file: str, search_str: str, pages: Tuple = None, action: str = 'Highlight'):
"""
Process the pages of the PDF File
"""
# Open the PDF
pdfDoc = fitz.open(input_file)
# Save the generated PDF to memory buffer
output_buffer = BytesIO()
total_matches = 0
# Iterate through pages
for pg in range(pdfDoc.pageCount):
# If required for specific pages
if pages:
if str(pg) not in pages:
continue
# Select the page
page = pdfDoc[pg]
# Get Matching Data
# Split page by lines
page_lines = page.getText("text").split('\n')
matched_values = search_for_text(page_lines, search_str)
if matched_values:
if action == 'Redact':
matches_found = redact_matching_data(page, matched_values)
elif action == 'Frame':
matches_found = frame_matching_data(page, matched_values)
elif action in ('Highlight', 'Squiggly', 'Underline', 'Strikeout'):
matches_found = highlight_matching_data(
page, matched_values, action)
else:
matches_found = highlight_matching_data(
page, matched_values, 'Highlight')
total_matches += matches_found
print(f"{total_matches} Match(es) Found of Search String {search_str} In Input File: {input_file}")
# Save to output
pdfDoc.save(output_buffer)
pdfDoc.close()
# Save the output buffer to the output file
with open(output_file, mode='wb') as f:
f.write(output_buffer.getbuffer())该process_data()函数的主要目的如下:
- 打开输入文件。
- 创建用于临时存储输出文件的内存缓冲区。
- 初始化一个变量,用于存储我们正在搜索的字符串的匹配总数。
- 遍历输入文件的选定页面并将当前页面拆分为行。
- 在页面中搜索字符串。
- 应用相应的动作(即
"Redact","Frame","Highlight"等等) - 显示一条消息,表明搜索过程的状态。
- 保存并关闭输入文件。
- 将内存缓冲区保存到输出文件。
它接受几个参数:
input_file:要处理的 PDF 文件的路径。output_file:处理后生成的PDF文件的路径。search_str: 要搜索的字符串。pages:处理 PDF 文件时要考虑的页面。action:对 PDF 文件执行的操作。
接下来,让我们编写一个函数来删除突出显示,以防万一:
def remove_highlght(input_file: str, output_file: str, pages: Tuple = None):
# Open the PDF
pdfDoc = fitz.open(input_file)
# Save the generated PDF to memory buffer
output_buffer = BytesIO()
# Initialize a counter for annotations
annot_found = 0
# Iterate through pages
for pg in range(pdfDoc.pageCount):
# If required for specific pages
if pages:
if str(pg) not in pages:
continue
# Select the page
page = pdfDoc[pg]
annot = page.firstAnnot
while annot:
annot_found += 1
page.deleteAnnot(annot)
annot = annot.next
if annot_found >= 0:
print(f"Annotation(s) Found In The Input File: {input_file}")
# Save to output
pdfDoc.save(output_buffer)
pdfDoc.close()
# Save the output buffer to the output file
with open(output_file, mode='wb') as f:
f.write(output_buffer.getbuffer())Python突出显示和编辑PDF文本示例:该remove_highlight()函数的目的是从 PDF 文件中删除突出显示(而不是编辑)。它执行以下操作:
- 打开输入文件。
- 创建用于临时存储输出文件的内存缓冲区。
- 遍历输入文件的整个页面并检查是否找到注释。
- 删除这些注释。
- 显示一条消息,表明此进程的状态。
- 关闭输入文件。
- 将内存缓冲区保存到输出文件。
现在让我们制作一个包装函数,它使用以前的函数根据动作调用适当的函数:
def process_file(**kwargs):
"""
To process one single file
Redact, Frame, Highlight... one PDF File
Remove Highlights from a single PDF File
"""
input_file = kwargs.get('input_file')
output_file = kwargs.get('output_file')
if output_file is None:
output_file = input_file
search_str = kwargs.get('search_str')
pages = kwargs.get('pages')
# Redact, Frame, Highlight, Squiggly, Underline, Strikeout, Remove
action = kwargs.get('action')
if action == "Remove":
# Remove the Highlights except Redactions
remove_highlght(input_file=input_file,
output_file=output_file, pages=pages)
else:
process_data(input_file=input_file, output_file=output_file,
search_str=search_str, pages=pages, action=action)上行动能"Redact","Frame","Highlight","Squiggly","Underline","Strikeout",和"Remove"。
让我们定义相同的函数,但使用包含多个 PDF 文件的文件夹:
def process_folder(**kwargs):
"""
Redact, Frame, Highlight... all PDF Files within a specified path
Remove Highlights from all PDF Files within a specified path
"""
input_folder = kwargs.get('input_folder')
search_str = kwargs.get('search_str')
# Run in recursive mode
recursive = kwargs.get('recursive')
#Redact, Frame, Highlight, Squiggly, Underline, Strikeout, Remove
action = kwargs.get('action')
pages = kwargs.get('pages')
# Loop though the files within the input folder.
for foldername, dirs, filenames in os.walk(input_folder):
for filename in filenames:
# Check if pdf file
if not filename.endswith('.pdf'):
continue
# PDF File found
inp_pdf_file = os.path.join(foldername, filename)
print("Processing file =", inp_pdf_file)
process_file(input_file=inp_pdf_file, output_file=None,
search_str=search_str, action=action, pages=pages)
if not recursive:
break此功能旨在处理包含在特定文件夹中的 PDF 文件。
它根据参数 recursive 的值递归或不递归地遍历指定文件夹的文件,并逐个处理这些文件。
它接受以下参数:
input_folder:包含要处理的 PDF 文件的文件夹的路径。search_str:要搜索以进行操作的文本。recursive:是否通过遍历子文件夹递归地运行此过程。action:要在前面提到的列表中执行的操作。pages: 要考虑的页面。
Python如何突出显示和编辑PDF文本?在我们编写主要代码之前,让我们创建一个用于解析命令行参数的函数:
def is_valid_path(path):
"""
Validates the path inputted and checks whether it is a file path or a folder path
"""
if not path:
raise ValueError(f"Invalid Path")
if os.path.isfile(path):
return path
elif os.path.isdir(path):
return path
else:
raise ValueError(f"Invalid Path {path}")
def parse_args():
"""Get user command line parameters"""
parser = argparse.ArgumentParser(description="Available Options")
parser.add_argument('-i', '--input_path', dest='input_path', type=is_valid_path,
required=True, help="Enter the path of the file or the folder to process")
parser.add_argument('-a', '--action', dest='action', choices=['Redact', 'Frame', 'Highlight', 'Squiggly', 'Underline', 'Strikeout', 'Remove'], type=str,
default='Highlight', help="Choose whether to Redact or to Frame or to Highlight or to Squiggly or to Underline or to Strikeout or to Remove")
parser.add_argument('-p', '--pages', dest='pages', type=tuple,
help="Enter the pages to consider e.g.: [2,4]")
action = parser.parse_known_args()[0].action
if action != 'Remove':
parser.add_argument('-s', '--search_str', dest='search_str' # lambda x: os.path.has_valid_dir_syntax(x)
, type=str, required=True, help="Enter a valid search string")
path = parser.parse_known_args()[0].input_path
if os.path.isfile(path):
parser.add_argument('-o', '--output_file', dest='output_file', type=str # lambda x: os.path.has_valid_dir_syntax(x)
, help="Enter a valid output file")
if os.path.isdir(path):
parser.add_argument('-r', '--recursive', dest='recursive', default=False, type=lambda x: (
str(x).lower() in ['true', '1', 'yes']), help="Process Recursively or Non-Recursively")
args = vars(parser.parse_args())
# To Display The Command Line Arguments
print("## Command Arguments #################################################")
print("\n".join("{}:{}".format(i, j) for i, j in args.items()))
print("######################################################################")
return args最后,让我们编写主要代码:
if __name__ == '__main__':
# Parsing command line arguments entered by user
args = parse_args()
# If File Path
if os.path.isfile(args['input_path']):
# Extracting File Info
extract_info(input_file=args['input_path'])
# Process a file
process_file(
input_file=args['input_path'], output_file=args['output_file'],
search_str=args['search_str'] if 'search_str' in (args.keys()) else None,
pages=args['pages'], action=args['action']
)
# If Folder Path
elif os.path.isdir(args['input_path']):
# Process a folder
process_folder(
input_folder=args['input_path'],
search_str=args['search_str'] if 'search_str' in (args.keys()) else None,
action=args['action'], pages=args['pages'], recursive=args['recursive']
)现在让我们测试我们的程序:
$ python pdf_highlighter.py --help输出:
usage: pdf_highlighter.py [-h] -i INPUT_PATH [-a {Redact,Frame,Highlight,Squiggly,Underline,Strikeout,Remove}] [-p PAGES]
Available Options
optional arguments:
-h, --help show this help message and exit
-i INPUT_PATH, --input_path INPUT_PATH
Enter the path of the file or the folder to process
-a {Redact,Frame,Highlight,Squiggly,Underline,Strikeout,Remove}, --action {Redact,Frame,Highlight,Squiggly,Underline,Strikeout,Remove}
Choose whether to Redact or to Frame or to Highlight or to Squiggly or to Underline or to Strikeout or to Remove
-p PAGES, --pages PAGES
Enter the pages to consider e.g.: [2,4]在探索我们的测试场景之前,让我澄清几点:
- 为避免遇到
PermissionError,请在运行此实用程序之前关闭输入的 PDF 文件。 - 要处理的输入 PDF 文件不能是扫描的 PDF 文件。
- 搜索字符串符合使用 Python 内置re模块的正则表达式规则。例如,将搜索字符串设置为同时
"organi[sz]e"匹配“organise”和“organize”。
作为演示示例,让我们突出显示BERT 论文中的“BERT”一词:
$ python pdf_highlighter.py -i bert-paper.pdf -a Highlight -s "BERT"输出:
## Command Arguments #################################################
input_path:bert-paper.pdf
action:Highlight
pages:None
search_str:BERT
output_file:None
######################################################################
## File Information ##################################################
File:bert-paper.pdf
Encrypted:False
format:PDF 1.5
title:
author:
subject:
keywords:
creator:LaTeX with hyperref package
producer:pdfTeX-1.40.17
creationDate:D:20190528000751Z
modDate:D:20190528000751Z
trapped:
encryption:None
######################################################################
121 Match(es) Found of Search String BERT In Input File: bert-paper.pdfPython突出显示和编辑PDF文本示例:如你所见,突出显示了 121 个匹配项,你可以使用其他突出显示选项,例如下划线、框架等。这是生成的PDF:

$ python pdf_highlighter.py -i bert-paper.pdf -a Remove生成的 PDF 将删除突出显示。
结论
我邀请你尝试其他操作,因为我发现使用 Python 自动执行这些操作非常有趣。
Python如何突出显示和编辑PDF文本?如果要突出显示多个 PDF 文件中的文本,你可以指定-i参数的文件夹或将 pdf 文件合并在一起并运行代码以生成包含要突出显示的所有文本的单个 PDF。
我希望你喜欢这篇文章并发现它很有趣。在此处查看完整代码。
其他相关处理PDF教程:
- 如何在 Python 中为 PDF 文件添加水印。
- 如何在 Python 中从 PDF 中提取图像。
- 如何在 Python 中提取所有 PDF 链接。
- 如何在 Python 中从 PDF 中提取表格。
- 如何在 Python 中将 PDF 转换为图像。

