
Python TensorFlow实现语音性别识别:了解如何使用 Python 中的 Tensorflow 框架构建一个深度学习模型,该模型能够仅通过你的语气来检测和识别你的性别。
Python如何根据语音识别性别?语音性别识别是一种通过处理语音信号来确定说话者性别类别的技术,在本教程中,我们将尝试使用 Python 中的 TensorFlow 框架通过语音对性别进行分类。
性别识别可用于许多领域,包括自动语音识别,它可以帮助提高这些系统的性能。它还可以用于按性别对通话进行分类,或者你可以将其作为一项功能添加到能够区分说话者性别的虚拟助手中。
这是目录:
- 准备数据集
- 构建模型
- 训练模型
- 测试模型
- 用你自己的声音测试模型
准备数据集
我们不会使用原始音频数据,因为音频样本可以是任意长度,并且可能会出现噪声问题。因此,在将其输入神经网络之前,我们需要执行某种特征提取。
特征提取始终是任何语音分析任务的第一阶段,它基本上以任意长度的音频作为输入,输出一个适合分类的定长向量。特征提取方法的一些示例是MFCC和Mel Spectrogram。
我们将使用Mozilla 的 Common Voice Dataset,它是用户在Common Voice 网站上阅读的语音数据的语料库,其目的是实现自动语音识别的训练和测试。然而,在我查看了数据集之后,许多样本实际上都被标记在了流派列中。因此,我们可以提取这些标记样本并进行性别识别。
Python如何根据语音识别性别?这是我为性别识别准备数据集所做的工作:
- 首先,我只过滤了在流派字段中标记的样本。
- 之后,我平衡了数据集,使女性样本的数量等于男性样本的数量,这将有助于神经网络不会过度拟合特定的性别。
- 最后,我使用Mel Spectrogram提取技术
128从每个语音样本中获取长度向量。
你可以在此存储库中查看为本教程准备的数据集。
另外,我已经包括了脚本,负责准备和预处理的数据集(从.mp3进入.npy的情况下,你要对自己的运行文件)(虽然它可能不是必要的),你可以检查它在这里。
TensorFlow实现语音性别识别示例:首先,使用pip安装以下库:
pip3 install numpy pandas tqdm sklearn tensorflow pyaudio librosa接下来,打开一个新笔记本并导入我们需要的模块:
import pandas as pd
import numpy as np
import os
import tqdm
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard, EarlyStopping
from sklearn.model_selection import train_test_split现在要获取每个样本的性别,有一个 CSV 元数据文件(在此处查看)将每个音频样本的文件路径链接到其适当的性别:
df = pd.read_csv("balanced-all.csv")
df.head()这是它的样子:
filename gender
0 data/cv-other-train/sample-069205.npy female
1 data/cv-valid-train/sample-063134.npy female
2 data/cv-other-train/sample-080873.npy female
3 data/cv-other-train/sample-105595.npy female
4 data/cv-valid-train/sample-144613.npy female让我们看看数据帧是如何结束的:
df.tail()输出:
filename gender
66933 data/cv-valid-train/sample-171098.npy male
66934 data/cv-other-train/sample-022864.npy male
66935 data/cv-valid-train/sample-080933.npy male
66936 data/cv-other-train/sample-012026.npy male
66937 data/cv-other-train/sample-013841.npy male让我们看看每个性别的样本数量:
# get total samples
n_samples = len(df)
# get total male samples
n_male_samples = len(df[df['gender'] == 'male'])
# get total female samples
n_female_samples = len(df[df['gender'] == 'female'])
print("Total samples:", n_samples)
print("Total male samples:", n_male_samples)
print("Total female samples:", n_female_samples)输出:
Total samples: 66938
Total male samples: 33469
Total female samples: 33469完美,大量平衡的音频样本,下面的函数将所有文件加载到一个数组中,我们不需要任何生成机制,因为它适合内存(因为每个音频样本只是提取的特征,大小为1KB ):
label2int = {
"male": 1,
"female": 0
}
def load_data(vector_length=128):
"""A function to load gender recognition dataset from `data` folder
After the second run, this will load from results/features.npy and results/labels.npy files
as it is much faster!"""
# make sure results folder exists
if not os.path.isdir("results"):
os.mkdir("results")
# if features & labels already loaded individually and bundled, load them from there instead
if os.path.isfile("results/features.npy") and os.path.isfile("results/labels.npy"):
X = np.load("results/features.npy")
y = np.load("results/labels.npy")
return X, y
# read dataframe
df = pd.read_csv("balanced-all.csv")
# get total samples
n_samples = len(df)
# get total male samples
n_male_samples = len(df[df['gender'] == 'male'])
# get total female samples
n_female_samples = len(df[df['gender'] == 'female'])
print("Total samples:", n_samples)
print("Total male samples:", n_male_samples)
print("Total female samples:", n_female_samples)
# initialize an empty array for all audio features
X = np.zeros((n_samples, vector_length))
# initialize an empty array for all audio labels (1 for male and 0 for female)
y = np.zeros((n_samples, 1))
for i, (filename, gender) in tqdm.tqdm(enumerate(zip(df['filename'], df['gender'])), "Loading data", total=n_samples):
features = np.load(filename)
X[i] = features
y[i] = label2int[gender]
# save the audio features and labels into files
# so we won't load each one of them next run
np.save("results/features", X)
np.save("results/labels", y)
return X, y上述函数负责读取该 CSV 文件并将所有音频样本加载到单个数组中,这在你第一次运行时需要一些时间,但它会将捆绑的数组保存在results文件夹中,这将节省我们第二次的时间跑。
label2int字典只是将每个性别映射到一个整数值,我们需要在load_data()函数中将字符串标签转换为整数标签。
现在这是一个单一的数组,但我们需要将我们的数据集拆分为训练、测试和验证集,下面的函数就是这样做的:
def split_data(X, y, test_size=0.1, valid_size=0.1):
# split training set and testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=7)
# split training set and validation set
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=valid_size, random_state=7)
# return a dictionary of values
return {
"X_train": X_train,
"X_valid": X_valid,
"X_test": X_test,
"y_train": y_train,
"y_valid": y_valid,
"y_test": y_test
}我们正在使用sklearn的train_test_split()方便功能,它将打乱我们的数据集并将其拆分为训练集和测试集,然后我们在训练集上再次运行它以获得验证集。让我们使用这些函数:
# load the dataset
X, y = load_data()
# split the data into training, validation and testing sets
data = split_data(X, y, test_size=0.1, valid_size=0.1)现在这本data字典包含了我们拟合模型所需的一切,那么让我们构建模型吧!
构建模型
Python TensorFlow实现语音性别识别 - 在本教程中,我们将使用具有5 个隐藏层的深度前馈神经网络,它不是完美的架构,但到目前为止它已经完成了工作:
def create_model(vector_length=128):
"""5 hidden dense layers from 256 units to 64, not the best model."""
model = Sequential()
model.add(Dense(256, input_shape=(vector_length,)))
model.add(Dropout(0.3))
model.add(Dense(256, activation="relu"))
model.add(Dropout(0.3))
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.3))
model.add(Dense(128, activation="relu"))
model.add(Dropout(0.3))
model.add(Dense(64, activation="relu"))
model.add(Dropout(0.3))
# one output neuron with sigmoid activation function, 0 means female, 1 means male
model.add(Dense(1, activation="sigmoid"))
# using binary crossentropy as it's male/female classification (binary)
model.compile(loss="binary_crossentropy", metrics=["accuracy"], optimizer="adam")
# print summary of the model
model.summary()
return model我们在每个全连接层之后使用30% 的dropout 率,这种类型的正则化有望防止训练数据集上的过度拟合。
这里需要注意的重要一点是,我们在输出层使用了一个带有sigmoid 激活函数的单个输出单元(神经元),当音频的扬声器是男性时,模型将输出标量1(或接近它),并且当它接近0时为女性。
此外,我们使用二元交叉熵作为损失函数,因为当我们只有 2 个类要预测时,它是分类交叉熵的特例。让我们使用这个函数来构建我们的模型:
# construct the model
model = create_model()训练模型
Python如何根据语音识别性别?现在我们已经建立了模型,让我们使用之前加载的数据集来训练它:
# use tensorboard to view metrics
tensorboard = TensorBoard(log_dir="logs")
# define early stopping to stop training after 5 epochs of not improving
early_stopping = EarlyStopping(mode="min", patience=5, restore_best_weights=True)
batch_size = 64
epochs = 100
# train the model using the training set and validating using validation set
model.fit(data["X_train"], data["y_train"], epochs=epochs, batch_size=batch_size, validation_data=(data["X_valid"], data["y_valid"]),
callbacks=[tensorboard, early_stopping])我们定义了两个回调,它们将在每个 epoch 结束后执行:
- 第一个是张量板,我们将使用它来查看模型在训练过程中的损失和准确性。
- 第二个回调是提前停止,这将在模型停止改进时停止训练,我指定了5 的耐心,这意味着它将在5个未改进的 epoch后停止训练,设置
restore_best_weights为True将恢复期间记录的最佳权重训练并将它们分配给模型权重。
TensorFlow实现语音性别识别示例:让我们保存这个模型:
# save the model to a file
model.save("results/model.h5")这是我的输出:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 256) 33024
_________________________________________________________________
dropout (Dropout) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 256) 65792
_________________________________________________________________
dropout_1 (Dropout) (None, 256) 0
_________________________________________________________________
dense_2 (Dense) (None, 128) 32896
_________________________________________________________________
dropout_2 (Dropout) (None, 128) 0
_________________________________________________________________
dense_3 (Dense) (None, 128) 16512
_________________________________________________________________
dropout_3 (Dropout) (None, 128) 0
_________________________________________________________________
dense_4 (Dense) (None, 64) 8256
_________________________________________________________________
dropout_4 (Dropout) (None, 64) 0
_________________________________________________________________
dense_5 (Dense) (None, 1) 65
=================================================================
Total params: 156,545
Trainable params: 156,545
Non-trainable params: 0
_________________________________________________________________
Train on 54219 samples, validate on 6025 samples
Epoch 1/100
54219/54219 [==============================] - 8s 143us/sample - loss: 0.5514 - accuracy: 0.7651 - val_loss: 0.3807 - val_accuracy: 0.8508
Epoch 2/100
54219/54219 [==============================] - 5s 93us/sample - loss: 0.4159 - accuracy: 0.8326 - val_loss: 0.3464 - val_accuracy: 0.8536
Epoch 3/100
54219/54219 [==============================] - 5s 93us/sample - loss: 0.3860 - accuracy: 0.8466 - val_loss: 0.3112 - val_accuracy: 0.8744
<..SNIPPED..>
Epoch 16/100
54219/54219 [==============================] - 5s 96us/sample - loss: 0.2864 - accuracy: 0.8936 - val_loss: 0.2387 - val_accuracy: 0.9087
Epoch 17/100
54219/54219 [==============================] - 5s 95us/sample - loss: 0.2824 - accuracy: 0.8945 - val_loss: 0.2464 - val_accuracy: 0.9110
Epoch 18/100
54219/54219 [==============================] - 6s 103us/sample - loss: 0.2887 - accuracy: 0.8920 - val_loss: 0.2406 - val_accuracy: 0.9074
Epoch 19/100
54219/54219 [==============================] - 5s 95us/sample - loss: 0.2822 - accuracy: 0.8939 - val_loss: 0.2435 - val_accuracy: 0.9080
Epoch 20/100
54219/54219 [==============================] - 5s 96us/sample - loss: 0.2813 - accuracy: 0.8957 - val_loss: 0.2567 - val_accuracy: 0.8993
Epoch 21/100
54219/54219 [==============================] - 5s 89us/sample - loss: 0.2759 - accuracy: 0.8962 - val_loss: 0.2442 - val_accuracy: 0.9112
如你所见,模型训练在 epoch 21停止 并达到了大约0.2387损失和几乎91%验证准确性(这是在 epoch 16)。
测试模型
由于现在模型已经过训练并且权重是最优的,让我们使用我们之前创建的测试集来测试它:
# evaluating the model using the testing set
print(f"Evaluating the model using {len(data['X_test'])} samples...")
loss, accuracy = model.evaluate(data["X_test"], data["y_test"], verbose=0)
print(f"Loss: {loss:.4f}")
print(f"Accuracy: {accuracy*100:.2f}%")看一下这个:
Evaluating the model using 6694 samples...
Loss: 0.2405
Accuracy: 90.95%令人惊讶的是,我们已经达到91%了模型从未见过的样本的准确性!太棒了!
如果你打开 tensorboard(使用命令:)tensorboard --logdir="logs",你将看到与此类似的损失和准确度曲线:
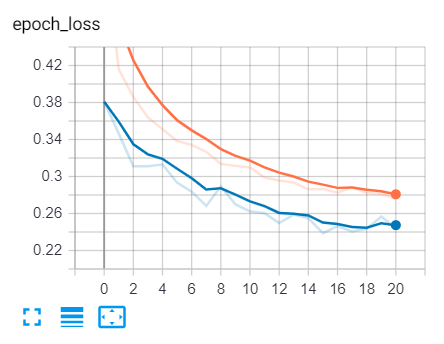
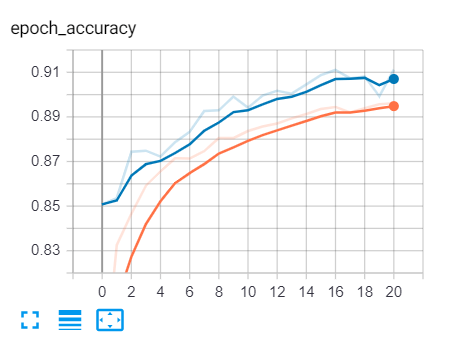
蓝色曲线是验证集,而橙色是训练集,你可以看到损失随着时间的推移在减少,准确度在增加,这正是我们所期望的!
用你自己的声音测试模型
Python TensorFlow实现语音性别识别:我知道这是令人兴奋的部分,我制作了一个脚本来记录你的声音,直到你停止说话(尽管你可以用任何语言说话)并将其保存到一个文件中,然后从该音频中提取特征并将其提供给模型检索结果:
import librosa
import numpy as np
def extract_feature(file_name, **kwargs):
"""
Extract feature from audio file `file_name`
Features supported:
- MFCC (mfcc)
- Chroma (chroma)
- MEL Spectrogram Frequency (mel)
- Contrast (contrast)
- Tonnetz (tonnetz)
e.g:
`features = extract_feature(path, mel=True, mfcc=True)`
"""
mfcc = kwargs.get("mfcc")
chroma = kwargs.get("chroma")
mel = kwargs.get("mel")
contrast = kwargs.get("contrast")
tonnetz = kwargs.get("tonnetz")
X, sample_rate = librosa.core.load(file_name)
if chroma or contrast:
stft = np.abs(librosa.stft(X))
result = np.array([])
if mfcc:
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result = np.hstack((result, mfccs))
if chroma:
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0)
result = np.hstack((result, chroma))
if mel:
mel = np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T,axis=0)
result = np.hstack((result, mel))
if contrast:
contrast = np.mean(librosa.feature.spectral_contrast(S=stft, sr=sample_rate).T,axis=0)
result = np.hstack((result, contrast))
if tonnetz:
tonnetz = np.mean(librosa.feature.tonnetz(y=librosa.effects.harmonic(X), sr=sample_rate).T,axis=0)
result = np.hstack((result, tonnetz))
return resultTensorFlow实现语音性别识别示例:上面的函数是负责加载音频文件并从中提取特征的函数,下面的代码行将使用argparse模块解析从命令行传递的音频文件路径并对其进行推断:
import argparse
parser = argparse.ArgumentParser(description="""Gender recognition script, this will load the model you trained,
and perform inference on a sample you provide (either using your voice or a file)""")
parser.add_argument("-f", "--file", help="The path to the file, preferred to be in WAV format")
args = parser.parse_args()
file = args.file
# construct the model
model = create_model()
# load the saved/trained weights
model.load_weights("results/model.h5")
if not file or not os.path.isfile(file):
# if file not provided, or it doesn't exist, use your voice
print("Please talk")
# put the file name here
file = "test.wav"
# record the file (start talking)
record_to_file(file)
# extract features and reshape it
features = extract_feature(file, mel=True).reshape(1, -1)
# predict the gender!
male_prob = model.predict(features)[0][0]
female_prob = 1 - male_prob
gender = "male" if male_prob > female_prob else "female"
# show the result!
print("Result:", gender)
print(f"Probabilities::: Male: {male_prob*100:.2f}% Female: {female_prob*100:.2f}%")如果你执行它,这将不起作用,因为没有定义record_to_file()方法(你可以在此处查看完整的脚本代码),但这有助于我解释代码。
Python如何根据语音识别性别?我们正在使用argparse模块来解析从命令行传递的文件路径,如果文件未传递(使用--file或-f参数),脚本将使用你的默认麦克风开始录音。
然后我们创建模型并加载我们之前训练的最佳权重,然后我们提取传递(或记录)的音频文件的特征,我们使用model.predict()来获得结果预测,这是一个例子:
$ python test.py --file "test-samples/16-122828-0002.wav"输出:
Result: female
Probabilities: Male: 20.77% Female: 79.23%事实上,从LibriSpeech 数据集中抓取的样本是女性!再次,在此处获取代码。
相关: 如何在 Python 中播放和录制音频
Python TensorFlow实现语音性别识别总结
现在你有很多选项可以进一步使模型更准确,一个是尝试提出另一种模型架构,你还可以使用卷积或循环网络并查看结果!我可以期望你达到的不仅仅是95%准确性,如果你这样做了,请不要犹豫,在下面的评论中与我们分享!
你也可以从 Kaggle下载原始数据集,并使用提供的函数使用另一种特征提取技术,例如MFCCextract_feature(),然后你可以比较结果。
整个教程材料都位于这个存储库中,请查看!

