
在本教程中,我们将讨论 Python 网页抓取以及如何使用多个库(如 Beautiful Soup、Selenium 和其他一些魔法工具(如 PhantomJS)来抓取网页)。
在Python网页抓取教程中,你将学习如何抓取静态网页、动态页面(Ajax 加载的内容)、iframe、获取特定的 HTML 元素、如何处理 cookie、Python网页抓取代码示例等等。你还将了解抓取陷阱以及如何避免它们。
Python如何抓取网页?我们将在本教程中使用 Python 3.x,所以让我们开始吧。
Python网页爬虫教程目录
- 什么是网页抓取?
- 网页抓取的好处
- 安装Beautiful Soup
- 使用Beautiful Soup
- 处理 HTTP 异常
- 处理 URL 异常
- 使用 class 属性抓取 HTML 标签
- 使用 findAll 抓取 HTML 标签
- 使用 Beautiful Soup 找到第 n 个孩子
- 使用正则表达式查找标签
- 抓取 JavaScript
- 将 ChromeDriver 与 Selenium 结合使用
- 使用 Selenium+PhantomJS
- Selenium page_source
- 使用 Selenium 抓取 iframe 内容
- 使用 Beautiful Soup 抓取 iframe 内容
- 使用 (Selenium+ PhantomJS) 处理 Ajax 调用
- 使用 PhantomJS 等待 Ajax 调用完成
- 处理cookies
- 避免的陷阱
- 像人一样行动
- 标题调整
- JavaScript 和 cookie 处理
- 一切都与时间有关
- 常见表单安全功能
- 带有隐藏值的输入字段
- honeypot避免
- 人工清单
- 网页抓取 VS 网页抓取
什么是网页抓取?
网络抓取通常是从网络中提取数据的过程;你可以分析数据并提取有用的信息。
此外,你可以将抓取的数据存储在数据库或任何类型的表格格式(如 CSV、XLS 等)中,以便你可以轻松访问该信息。
抓取的数据可以传递给像NLTK这样的库进行进一步处理,以了解页面在说什么。
网页抓取的好处
你可能想知道为什么我应该抓取网络而我有谷歌?好吧,我们不会在这里重新发明轮子。它不仅仅用于创建搜索引擎。
你可以抓取竞争对手的网页并分析数据,然后查看竞争对手的客户对他们的反应满意的产品类型。所有这一切都是免费的。
一个像 Moz 这样成功的 SEO 工具,它可以抓取和抓取整个网络并为你处理数据,这样你就可以了解人们的兴趣以及如何与你所在领域的其他人竞争以获得领先地位。
这些只是一些简单的用途。抓取的数据意味着赚钱:)。
Python网页抓取教程:安装Beautiful Soup
我假设你有一些Python 基础知识,所以让我们安装我们的第一个 Python 抓取库,它是 Beautiful Soup。
要安装 Beautiful Soup,你可以使用 pip,也可以从源代码安装。
我将使用 pip 安装它,如下所示:
$ pip install beautifulsoup4要检查它是否已安装,请打开你的编辑器并键入以下内容:
from bs4 import BeautifulSoup然后运行它:
$ python myfile.py如果运行没有错误,则表示 Beautiful Soup 安装成功。现在,让我们看看如何使用Beautiful Soup。
使用Beautiful Soup
看看这个简单的Python网页抓取示例;我们将使用 Beautiful Soup 提取页面标题:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("https://www.python.org/")
res = BeautifulSoup(html.read(),"html5lib");
print(res.title)结果是:

我们使用 urlopen 库连接到我们想要的网页,然后我们使用 html.read() 方法读取返回的 HTML。
返回的 HTML 被转换为具有层次结构的 Beautiful Soup 对象。
这意味着如果你需要提取任何 HTML 元素,你只需要知道周围的标签即可获取它,我们将在后面看到。
处理 HTTP 异常
无论出于何种原因, urlopen 都可能返回错误。如果页面未找到,则可能是 404,如果存在内部服务器错误,则可能是 500,因此我们需要通过使用如下异常处理来避免脚本崩溃,如下Python网页抓取代码示例:
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
try:
html = urlopen("https://www.python.org/")
except HTTPError as e:
print(e)
else:
res = BeautifulSoup(html.read(),"html5lib")
print(res.title)太好了,如果服务器停机或你输入的域不正确怎么办?
处理 URL 异常
我们也需要处理这种异常。这个异常是 URLError,所以我们的代码会是这样的:
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://www.python.org/")
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(),"html5lib")
print(res.titles)好吧,我们需要检查的最后一件事是返回的标签,你可能输入了错误的标签或尝试抓取在抓取页面上找不到的标签,这将返回 None 对象,因此你需要检查 None 对象.
这可以使用一个简单的 if 语句来完成,如下Python网页抓取示例所示:
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://www.python.org/")
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(),"html5lib")
if res.title is None:
print("Tag not found")
else:
print(res.title)太好了,我们的刮板做得很好。现在我们可以抓取整个页面或抓取特定标签。
使用 class 属性抓取 HTML 标签
Python网页抓取教程:现在让我们尝试通过根据 CSS 类抓取一些 HTML 元素来有选择性。
Beautiful Soup 对象有一个名为 findAll 的函数,它根据元素的属性提取或过滤元素。
我们可以过滤所有类为“widget-title”的 h2 元素,如下所示:
tags = res.findAll("h2", {"class": "widget-title"})然后我们可以使用 for 循环来迭代它们并对它们做任何事情。
所以我们的代码会是这样的,如下Python网页抓取代码示例:
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://www.python.org/")
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(),"html5lib")
tags = res.findAll("h2", {"class": "widget-title"})
for tag in tags:
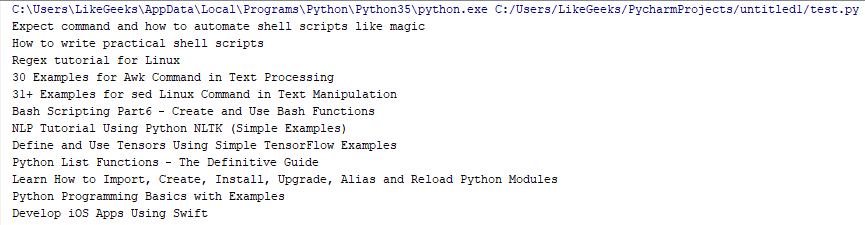
print(tag.getText())此代码返回所有 h2 标签,其类名为 widget-title,其中这些标签是主页帖子标题。
我们使用 getText 函数仅打印标签的内部内容,但如果你不使用 getText,你最终会得到包含所有内容的标签。
检查差异:
当我们使用 getText() 时:
而这不使用 getText():

使用 findAll 抓取 HTML 标签
我们看到了 findAll 函数如何按类过滤标签,但这不是全部。
要过滤标签列表,请将上面示例中突出显示的行替换为以下行:
tags = res.findAll("span", "a" "img")此代码从抓取的 HTML 中获取所有 span、anchor 和 image 标签。
此外,你可以提取具有以下类的标签:
tags = res.findAll("a", {"class": ["url", "readmorebtn"]})此代码提取所有具有“readmorebtn”和“url”类的锚标记。
你可以使用 text 参数根据内部文本本身过滤内容,如下所示:
tags = res.findAll(text="Python Programming Basics with Examples")findAll 函数返回与指定属性匹配的所有元素,但如果只想返回一个元素,则可以使用 limit 参数或使用 find 函数,该函数仅返回第一个元素。
使用 Beautiful Soup 找到第 n 个孩子
Beautiful Soup 对象具有许多强大的功能;你可以像这样直接获取子元素:
tags = res.span.findAll("a")此行将获取 Beautiful Soup 对象上的第一个 span 元素,然后抓取该 span 下的所有锚元素。
如果你需要得到第n个孩子怎么办?
你可以像这样使用 select 函数:
tag = res.find("nav", {"id": "site-navigation"}).select("a")[3]此行获取 ID 为“site-navigation”的导航元素,然后我们从该导航元素中获取第四个锚标记。
Beautiful Soup 是一个强大的库!!
使用正则表达式查找标签
在之前的教程中,我们讨论了正则表达式,我们看到了使用正则表达式识别常见模式(例如电子邮件、URL 等)的强大功能。
幸运的是,Beautiful Soup 有这个功能;你可以传递正则表达式模式以匹配特定标签。
想象一下,你想要抓取一些与特定模式匹配的链接,例如内部链接或特定外部链接,或者抓取位于特定路径中的一些图像。
正则表达式引擎使完成这些工作变得如此容易。
import re
tags = res.findAll("img", {"src": re.compile("\.\./uploads/photo_.*\.png")})这些行将抓取 ../uploads/ 上的所有 PNG 图像,并以 photo_ 开头。
这只是一个简单的示例,向你展示了正则表达式与 Beautiful Soup 相结合的强大功能。
Python网页抓取教程:抓取 JavaScript
假设你需要抓取的页面有另一个加载页面,它将你重定向到所需页面,并且 URL 没有更改,或者你抓取的页面的某些部分使用 Ajax 加载其内容。
我们的刮板不会加载这些内容,因为刮板不会运行所需的 JavaScript 来加载该内容。
你的浏览器运行 JavaScript 并正常加载任何内容,我们将使用我们的第二个抓取库(称为 Selenium)执行此操作。
Selenium 库不包括它的浏览器;你需要安装第三方浏览器(或 Web 驱动程序)才能工作。这除了浏览器本身。
你可以选择 Chrome、Firefox、Safari 或 Edge。
如果你安装了这些驱动程序中的任何一个,比如说 Chrome,它会打开一个浏览器实例并加载你的页面,然后你就可以抓取你的页面或与你的页面进行交互。
Python网页爬虫教程:将 ChromeDriver 与 Selenium 结合使用
首先,你应该像这样安装 selenium 库:
$ pip install selenium然后你应该从这里下载 Chrome 驱动程序并将其下载到你的系统路径。
现在你可以像这样加载你的页面,如下Python网页抓取示例:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.python.org/")
nav = browser.find_element_by_id("mainnav")
print(nav.text)输出如下所示:

很简单,对吧?
我们没有与页面元素进行交互,所以我们还没有看到 Selenium 的强大,等待它。
Python如何抓取网页?使用 Selenium+PhantomJS
你可能喜欢使用浏览器驱动程序,但还有更多的人喜欢在后台运行代码而看不到实际运行情况。
为此,有一个很棒的工具叫做 PhantomJS,它可以在不打开任何浏览器的情况下加载你的页面并运行你的代码。
PhantomJS 使你可以轻松地与抓取的页面 cookie 和 JavaScript 进行交互。
此外,你可以像 Beautiful Soup 一样使用它来抓取页面和这些页面中的元素。
从这里下载 PhantomJS并将其放在你的 PATH 中,以便我们可以将其用作 Selenium 的 Web 驱动程序。
现在,让我们使用 Selenium 和 PhantomJS 抓取网页,就像我们使用 Chrome 网络驱动程序一样。
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/")
print(browser.find_element_by_class_name("introduction").text)
browser.close()结果是:

惊人的!!它运作良好。
你可以通过多种方式访问元素:
browser.find_element_by_id("id")
browser.find_element_by_css_selector("#id")
browser.find_element_by_link_text("Click Here")
browser.find_element_by_name("Home")所有这些函数只返回一个元素;你可以使用这样的元素返回多个元素:
browser.find_elements_by_id("id")
browser.find_elements_by_css_selector("#id")
browser.find_elements_by_link_text("Click Here")
browser.find_elements_by_name("Home")Selenium page_source
你可以像这样使用 page_source 在 Selenium 返回的内容上使用 Beautiful Soup 的强大功能,如下Python网页抓取代码示例:
from selenium import webdriver
from bs4 import BeautifulSoup
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/")
page = BeautifulSoup(browser.page_source,"html5lib")
links = page.findAll("a")
for link in links:
print(link)
browser.close()
结果是:
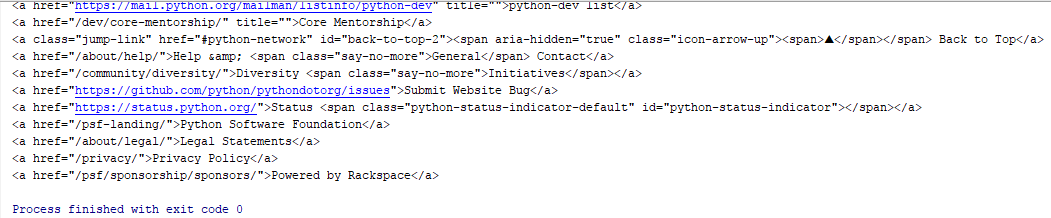
如你所见,PhantomJS 使抓取 HTML 元素变得非常容易。让我们看看更多。
使用 Selenium 抓取 iframe 内容
你抓取的页面可能包含一个包含数据的 iframe。
如果你尝试抓取包含 iframe 的页面,你将无法获得 iframe 内容;你需要抓取 iframe 源。
你可以使用 Selenium 切换到要抓取的框架来抓取 iframe。
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe")
iframe = browser.find_element_by_tag_name("iframe")
browser.switch_to.default_content()
browser.switch_to.frame(iframe)
iframe_source = browser.page_source
print(iframe_source) #returns iframe source
print(browser.current_url) #returns iframe URL结果是:
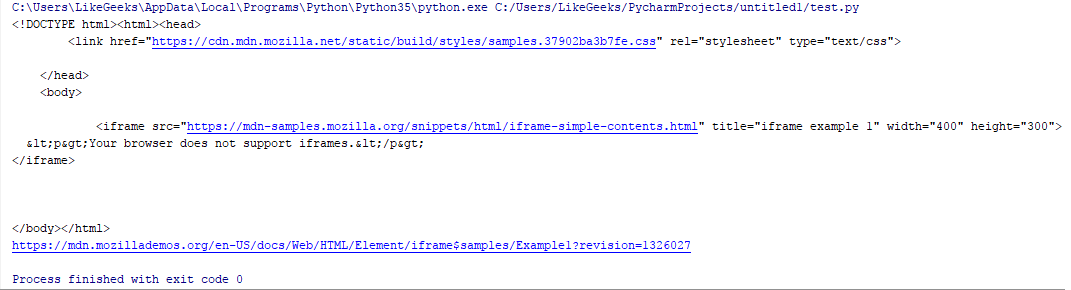
检查当前网址;它是 iframe URL,而不是原始页面。
Python如何抓取网页?使用 Beautiful Soup 抓取 iframe 内容
可以通过find函数获取iframe的URL;然后你可以废弃那个 URL。
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe")
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(), "html5lib")
tag = res.find("iframe")
print(tag['src']) #URl of iframe ready for scraping惊人的!!这里我们使用另一种技术,从页面中抓取 iframe 内容。
使用 (Selenium+ PhantomJS) 处理 Ajax 调用
在进行 Ajax 调用后,你可以使用 Selenium 来抓取内容。
就像单击一个按钮来获取你需要抓取的内容。检查以下Python网页抓取示例:
from selenium import webdriver
import time
browser = webdriver.PhantomJS()
browser.get("https://www.w3schools.com/xml/ajax_intro.asp")
browser.find_element_by_tag_name("button").click()
time.sleep(2) #Explicit wait
browser.get_screenshot_as_file("image.png")
browser.close()结果是:
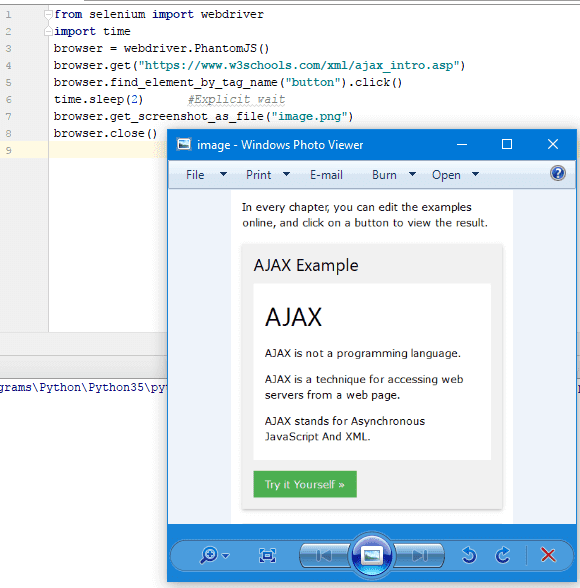
在这里,我们抓取一个包含按钮的页面,然后单击该按钮,这将调用 Ajax 并获取文本,然后我们保存该页面的屏幕截图。
这里有一件小事;这是关于等待时间。
我们知道页面加载不能超过 2 秒才能完全加载,但这不是一个好的解决方案,服务器可能需要更多时间,或者你的连接可能很慢,原因有很多。
使用 PhantomJS 等待 Ajax 调用完成
最好的解决方案是检查最终页面上是否存在 HTML 元素,如果存在,则表示 Ajax 调用已成功完成。
检查这个Python网页抓取代码示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.PhantomJS()
browser.get("https://resttesttest.com/")
browser.find_element_by_id("submitajax").click()
try:
element = WebDriverWait(browser, 10).until(EC.text_to_be_present_in_element((By.ID, "statuspre"),"HTTP 200 OK"))
finally:
browser.get_screenshot_as_file("image.png")
browser.close()结果是:
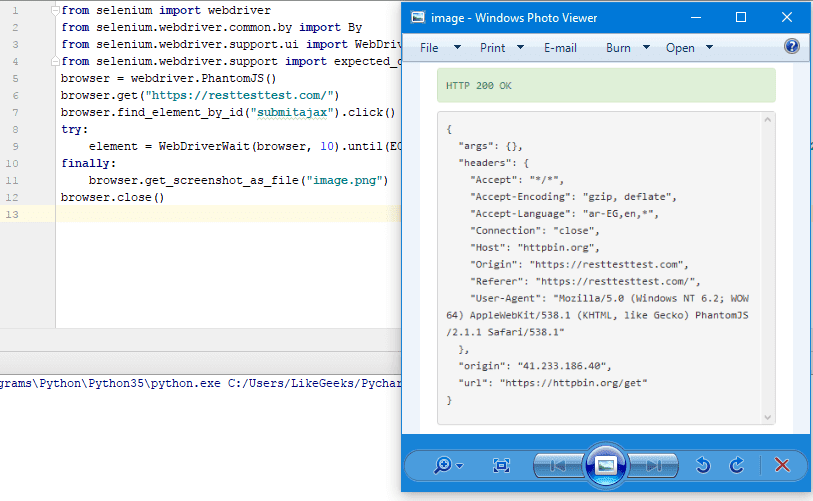
这里我们点击一个 Ajax 按钮,它进行 REST 调用并返回JSON结果。
我们检查 div 元素文本是否为“HTTP 200 OK”,超时 10 秒,然后我们将结果页面保存为图像,如图所示。
你可以检查许多内容,例如:
URL 更改使用
EC.url_changes()新打开的窗口使用
EC.new_window_is_opened()使用以下方法更改标题:
EC.title_is()如果你有任何页面重定向,你可以查看标题或 URL 是否有更改以进行检查。
有很多条件需要检查;我们只是举个例子来告诉你你有多少权力。
凉爽的!!
Python网页抓取教程:处理cookies
有时,当你编写抓取代码时,为你抓取的站点处理 cookie 非常重要。
也许你需要删除 cookie,或者你需要将其保存在一个文件中并用于以后的连接。
那里有很多场景,让我们看看如何处理 cookie。
要检索当前访问站点的 cookie,你可以像这样调用 get_cookies() 函数:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/")
print(browser.get_cookies())结果是:

要删除 cookie,你可以使用 delete_all_cookies() 函数,如下Python网页抓取代码示例所示:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/")
browser.delete_all_cookies()Python如何抓取网页?避免的陷阱
抓取网站时最令人失望的事情是在查看输出时看不到数据,即使它在浏览器中可见。或者网络服务器拒绝提交的听起来非常好的表单。或者更糟糕的是,你的 IP 因匿名原因被网站屏蔽。
我们将讨论在使用 Scrapy 时可能面临的最著名的障碍,认为这些信息很有用,因为它可以帮助你解决错误,甚至在你陷入困境之前预防问题。
像人一样行动
难以抓取的网站面临的基本挑战是,他们已经能够以各种方式(例如使用验证码)弄清楚如何区分真人和抓取者。
尽管这些网站使用了硬技术来检测抓取,但也有一些变化,你可以让你的脚本看起来更像一个人。
标题调整
设置标头的最佳方法之一是使用请求库。HTTP 标头是每次你尝试向 Web 服务器执行请求时服务器发送给你的一组属性。
大多数浏览器在初始化任何连接时使用接下来的七个字段:
Host https://www.google.com/
Connection keep-alive
Accept text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/
39.0.2171.95 Safari/537.36
Referrer https://www.google.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language en-US,en;q=0.8接下来,是通常的 Python 抓取工具库urllib使用的默认标头:
Accept-Encoding identity
User-Agent Python-urllib/3.4这两个标题是唯一真正重要的设置。因此,将它们保持为默认值将是一个好主意。
Python网页抓取示例:JavaScript 和 cookie 处理
解决许多抓取问题的重要方法之一是正确处理 cookie。使用 cookie 跟踪你在网站上的进度的网站也可能使用 cookie 来阻止具有异常行为的抓取工具(例如浏览过多页面或快速提交表单)并防止它们抓取网站。
如果你的浏览器 cookie 将你的身份传递给网站,那么解决方案,例如更改你的 IP 地址,甚至关闭并重新打开你与网站的连接,可能无用且浪费时间。
在抓取网站期间,cookie 很重要。有些网站每次都会要求提供新版本的 cookie,而不是要求再次重新登录。
万一你试图抓取单个或几个网站,你应该检查和测试这些网站的 cookie,并决定你需要处理哪个网站。
EditThisCookie 是最流行的 Chrome 扩展程序之一,可用于检查 cookie。
一切都与时间有关
Python网页爬虫教程:如果你是那种做任何事情都太快的人,那可能在抓取时不起作用。一组高度受保护的网站可能会禁止你提交表格、下载信息,甚至如果你比正常人更快地完成网站,则无法浏览该网站。有时候,要想走得快,就得慢下来。
为避免阻塞,你需要将请求和页面加载保持在最低限度。如果你有机会尝试将每个请求和下一个请求之间的时间延长几秒钟,这可能会解决你的问题,你可以在代码中添加额外的两行,如下所示:
import time
time.sleep(3)常见表单安全功能
如果你的代码试图创建大量用户帐户并向所有网站成员发送垃圾邮件,那么你就遇到了大问题。
处理帐户登录和创建的 Web 表单如果很容易成为随意抓取的目标,则对安全性构成高度威胁。因此,对于许多网站所有者来说,他们可以使用这些表格来限制抓取工具对其网站的访问。
Python如何抓取网页?带有隐藏值的输入字段
有时在 HTML 表单中,隐藏字段允许浏览器查看字段中的值,但用户看不到,除非用户查看网站的源代码。有时,这些隐藏字段可以防止垃圾邮件。
隐藏字段的用途之一是通过以下两种方法之一阻止网络抓取:
- 隐藏字段可以填充随机生成的变量,服务器希望将其发送到表单处理页面。
现在,如果在表单中找不到这个值,那么服务器可以假设表单提交不是主要来自网站页面,而是直接从抓取器发送到处理页面。
你可以通过先抓取表单页面,获取随机生成的变量值,最后从该点发送到处理页面来克服这种情况。 - 检查表单页面是否具有名称为用户名或电子邮件的隐藏字段,然后不健康的抓取代码可能会用任何数据填充该字段并尝试发送它,无论该字段是否对用户隐藏。在这种情况下,任何具有真实值或与预期值不同的隐藏字段都可能被忽略,甚至可能会禁止用户访问该网站。
例如,查看下面的 Facebook 登录页面。即使表单只有三个可见的字段,即用户名、密码和提交按钮,它也会通知后端服务器很多信息。
honeypot避免
在识别有用和无用信息时,CSS 使生活变得异常简单,有时这对网络爬虫来说可能是一个大问题。
当网站表单中的某个字段通过 CSS 标记为对用户隐藏时,那么几乎访问该网站的普通用户将无法填充该字段,因为它不会出现在浏览器中。
现在,如果表单填充了数据,那么很有可能它是由网络爬虫完成的,并且发送的表单将被阻止。
这也适用于网站上的链接、文件、图像和任何其他可以被爬虫读取的字段,但它被标记为对通过浏览器访问网站的普通用户隐藏。
如果你尝试访问网站上的隐藏链接,这将导致触发服务器端脚本以阻止你的 IP,你将退出该网站,或者该页面可以采取其他一些服务器操作以进一步停止使用权。
人工清单
Python网页抓取示例:如果你已经完成了之前的所有提示,但仍然被网站禁止,并且你没有理由为什么会发生这种情况,那么请尝试按照下一个清单来解决你的问题:
- JavaScript 问题:如果你收到来自Web 服务器的空白页面、意外数据(或与你在浏览器中看到的不一样)或缺少信息,很可能是由于在网站上执行 JavaScript 来构建网站页面。
- 请求正确发送:如果你尝试向网站提交表单或发布请求,请检查网站页面以确保你提交的所有内容都符合网站的要求且格式正确。
Chrome Inspector Panel 是一种工具,用于查看发送到网站的真实 POST 请求,以确保人工请求看起来与你的抓取工具尝试发送的请求相同。 - Cookies 问题:如果你尝试登录某个网站并且出现错误,例如登录时卡住或网站处于奇怪状态。
然后检查你的 cookie 并确保它们在每个页面之间正确传输,并针对每个请求发送到网站。 - HTTP 错误:如果你收到来自客户端的 HTTP 错误,例如 403 Forbidden 错误,这可能表明该网站已将你的 IP 地址标记为抓取工具,并且不会再接受来自你 IP 的任何请求。
一种解决方案是等待你的 IP 从列表中删除,或获取新 IP(例如移动到另一个位置)。
你可以按照以下几个提示再次避免阻塞:
- 正如我们之前提到的,确保你的抓取工具不会过快地浏览网站。你可以为刮板添加延迟并让它们在一夜之间运行。
- 更改你的 HTTP 标头。
- 像人类一样行事,不要点击或访问任何人类无法访问的内容。
- 如果你发现访问网站有困难,有时网站管理员会允许你使用你的抓取工具,因此请尝试发送电子邮件至webmaster@ <域名> 或admin@ <域名> 并征得他们的许可。
Python网页爬虫教程:网页抓取 VS 网页抓取
我们看到了如何解析网页;现在,有些人对网络抓取和网络爬行感到困惑。
正如我们以上的Python网页抓取教程所见,Web爬虫是关于解析网页并从中提取数据以用于任何目的。
Python如何抓取网页?网络爬行是关于收集你找到的每个链接并在没有规模的情况下爬行每个链接,这用于索引,就像谷歌和其他搜索引擎所做的那样。

