
随机森林R编程是决策树的集合。它构建并组合了多个决策树以获得更准确的预测。这是一种非线性分类算法。每个决策树模型在单独使用时都会使用。进行案例的错误估计, 该错误估计在构建树时不使用。这被称为以百分比表示的袋外误差估计。
他们叫随机因为他们在训练时会随机选择预测变量。他们叫森林因为它们采用多个树的输出来做出决定。随机森林胜过决策树, 因为作为委员会运作的大量不相关树(模型)将始终胜过各个组成模型。
理论
随机森林从观测值, 随机初始变量(列)中获取随机样本, 并尝试建立模型。随机森林算法如下:
- 绘制一个大小随机的引导样本ñ(随机选择ñ训练数据样本)。
- 从引导程序样本中增长决策树。在树的每个节点上, 随机选择d特征。
- 使用根据目标函数提供最佳拆分的特征(变量)拆分节点。例如, 通过最大化信息增益。
- 重复步骤1到步骤2, ķ次(k是要使用样本子集创建的树的数量)。
- 汇总每棵树对新数据点的预测, 以多数表决方式分配类别标签, 即选择最多树数选择的组, 然后为该组分配新数据点。
例子:
在训练数据中考虑一个包含三个水果的苹果, 橙子和樱桃组成的水果盒, 即n =3。我们预测该水果盒中的水果数量最多。使用训练数据的随机森林模型, 其中有许多树, k = 3。
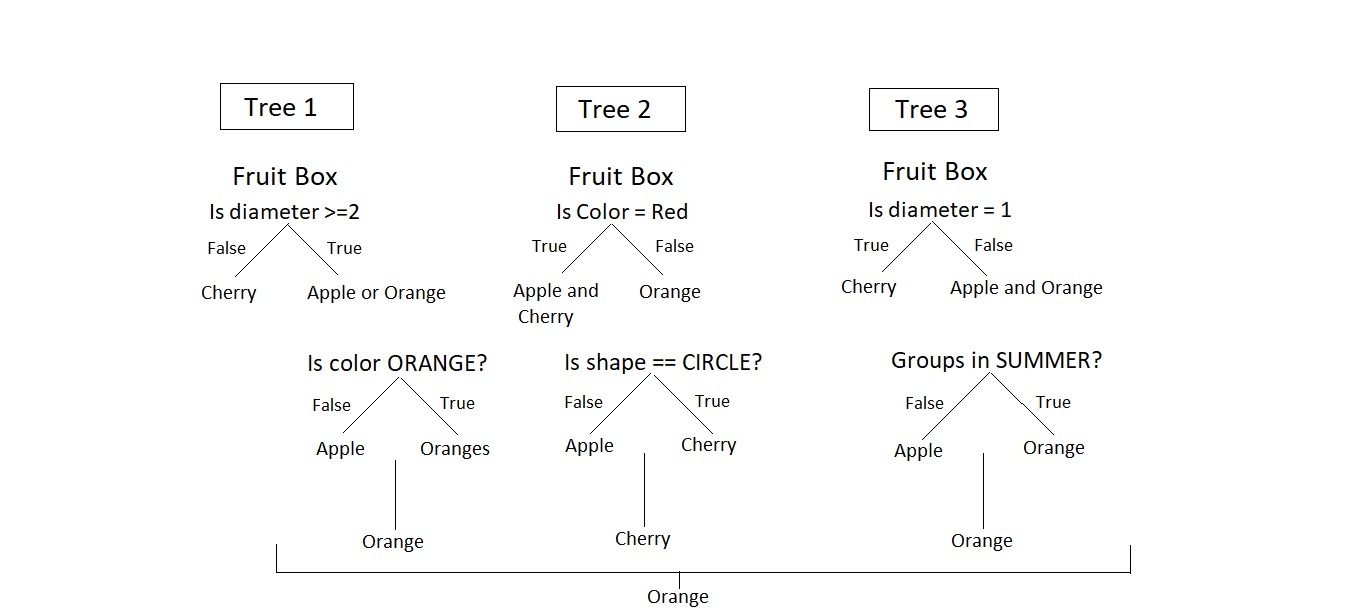
使用各种数据特征(即直径, 颜色, 形状和组)来判断模型。在橙, 爽快和橙中, 随机森林在果盒中选择橙的含量最高。
数据集
虹膜数据集包含来自3种鸢尾(鸢尾, 鸢尾, 杂色鸢尾)中的每种的50个样本, 以及英国统计学家和生物学家罗纳德·费舍尔(Ronald Fisher)在其1936年的论文中引入的多元数据集在分类学问题中使用多次测量。从每个样品中测量出四个特征, 即萼片和花瓣的长度和宽度, 并基于这四个特征的组合, Fisher开发了一个线性判别模型以区分物种。
# Loading data
data(iris)
# Structure
str (iris)
对数据集执行随机森林
在包含11个人和6个变量或属性的数据集上使用随机森林算法。
# Installing package
install.packages( "caTools" ) # For sampling the dataset
install.packages( "randomForest" ) # For implementing random forest algorithm
# Loading package
library(caTools)
library(randomForest)
# Splitting data in train and test data
split < - sample.split(iris, SplitRatio = 0.7 )
split
train < - subset(iris, split = = "TRUE" )
test < - subset(iris, split = = "FALSE" )
# Fitting Random Forest to the train dataset
set .seed( 120 ) # Setting seed
classifier_RF = randomForest(x = train[ - 5 ], y = train$Species, ntree = 500 )
classifier_RF
# Predicting the Test set results
y_pred = predict(classifier_RF, newdata = test[ - 5 ])
# Confusion Matrix
confusion_mtx = table(test[, 5 ], y_pred)
confusion_mtx
# Plotting model
plot(classifier_RF)
# Importance plot
importance(classifier_RF)
# Variable importance plot
varImpPlot(classifier_RF)输出如下:
模型classifier_RF:
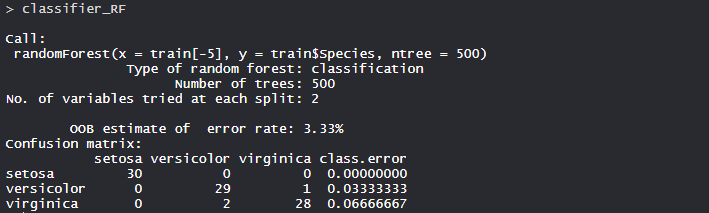
模型中的树数为500, 否。在每个分割处尝试的变量的平均值为2。setosa中的分类误差为0.000即0%, Versicolor为0.033即3.3%, virginica为0.066即6.6%。
混淆矩阵:

因此, 有20个Setosa被正确地分类为Setosa。在23种杂色中, 有20种杂色被正确分类为杂色, 3种被分类为维吉尼亚。 17个维吉尼亚州被正确分类为维吉尼亚州。
模型图:
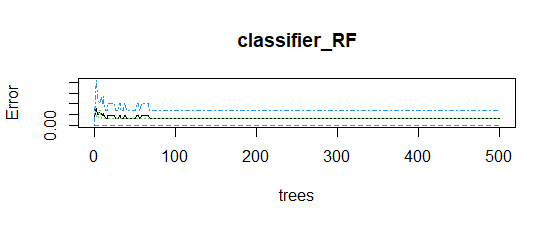
错误率随着树木数量的增加而稳定。
重要功能:
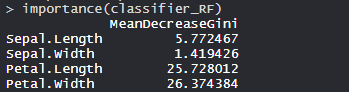
花瓣宽度是最重要的功能, 其次是Petal.Length, Sepal.Width和Sepal.Length。
重要功能图:

该图清楚地显示Petal.Width是最重要的特征或变量, 其后是Petal.Length, Sepal.Width和Sepal.Length。
因此, 随机森林是业界用于分类的强大算法。

