
在本指南中,我将向你展示使用Python合并CSV的操作:将多个CSV文件合并为单个文件的几种方法(它同样适用于文本文件和其他文件)。
最后,用几行代码,你将能够Python合并CSV,并组合数百个文件与加载的数据完全控制-你可以转换所有CSV文件到Pandas DataFrame,然后标记将要进入CSV文件的每一行。
- 相关文章推荐:Python批量合并CSV:如何合并多个CSV文件?
待合并CSV文件例子:
- data_201901.csv
- data_201902.csv
- data_201903.csv
Python合并CSV期望输出:
- merged.csv
使用Python合并CSV文件的详细步骤(合并多个)
注意: 我们假设所有文件都有相同数量的列和相同的信息。
步骤1:导入模块,设置工作目录
首先,我们将加载程序所需的模块,并选择工作文件夹:
import os, glob
import pandas as pd
path = "/home/user/data/"第二步:按模式匹配CSV文件
下一步是收集所有需要合并的CSV文件。这将通过以下方式完成:
all_files = glob.glob(os.path.join(path, "data_*.csv"))使用data_*.csv匹配文件:
- 以data_开始
- 文件扩展名为.csv
你可以根据自己的需要定制选择,记住要使用正则表达式匹配。
第三步:合并列表中的所有文件并导出为CSV文件
最后一步是将所有选中的文件加载到一个DataFrame中,如果需要,将其转换回csv格式:
df_merged = (pd.read_csv(f, sep=',') for f in all_files)
df_merged = pd.concat(df_from_each_file, ignore_index=True)
df_merged.to_csv( "merged.csv")注意,你可以通过:sep=','来改变分隔符,或者改变要加载的标题和行
你可以在这里找到更多关于转换DataFrame到CSV文件的信息:panda .DataFrame.to_csv
完整代码
下面你可以找到Python合并CSV的完整代码,可以用于合并多个CSV文件。
import os, glob
import pandas as pd
path = "/home/user/data/"
all_files = glob.glob(os.path.join(path, "data_*.csv"))
df_from_each_file = (pd.read_csv(f, sep=',') for f in all_files)
df_merged = pd.concat(df_from_each_file, ignore_index=True)
df_merged.to_csv( "merged.csv")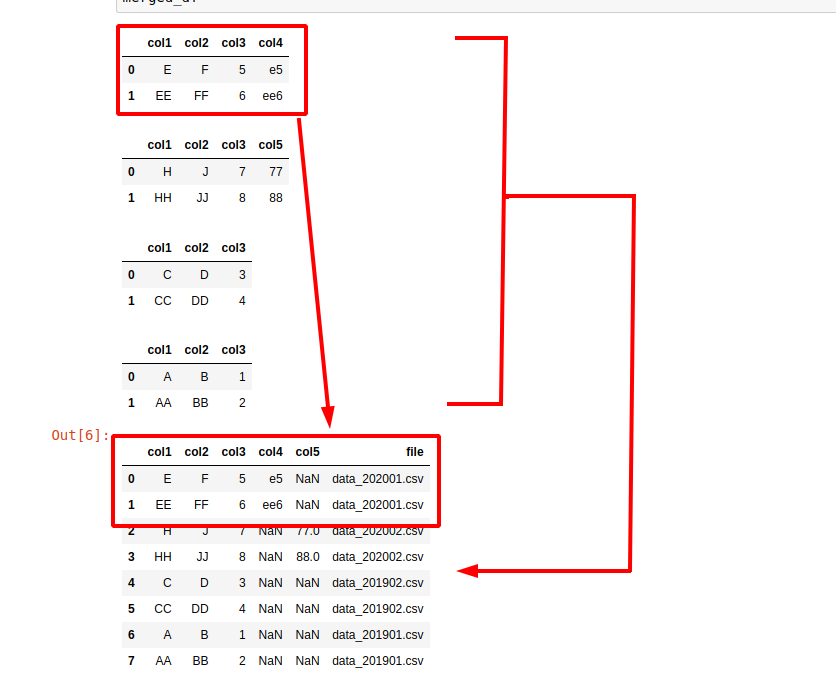
使用Python和trace合并多个CSV(相同的)文件的步骤
现在,假设你想要将多个CSV文件合并到一个数据帧中,但又想有一个列,表示行来自哪个文件。例如:
| ROW | COL | COL2 | FILE |
|---|---|---|---|
| 1 | A | B | data_201901.csv |
| 2 | C | D | data_201902.csv |
这可以通过上面的代码的小改变非常容易实现,下面是Python合并CSV的代码:
import os, glob
import pandas as pd
path = "/home/user/data/"
all_files = glob.glob(os.path.join(path, "*.csv"))
all_df = []
for f in all_files:
df = pd.read_csv(f, sep=',')
df['file'] = f.split('/')[-1]
all_df.append(df)
merged_df = pd.concat(all_df, ignore_index=True, sort=True)在本例中,我们遍历所有选定的文件,然后提取文件名并创建包含该文件名的列。
当列不同时,组合多个CSV文件
有时,CSV文件会因为某些列而不同,或者它们可能相同,只是顺序错误。在这个例子中,你可以找到下面实现Python合并CSV的代码,其中不需要有相同结构的CSV文件:
import os, glob
import pandas as pd
path = "/home/user/data/"
all_files = glob.glob(os.path.join(path, "*.csv"))
all_df = []
for f in all_files:
df = pd.read_csv(f, sep=',')
f['file'] = f.split('/')[-1]
all_df.append(df)
merged_df = pd.concat(all_df, ignore_index=True, , sort=True)Pandas将通过以下方法对齐数据:pd.concat。在缺少列的情况下,给定CSV文件的行将包含NaN值:
| ROW | COL | COL2 | COL_201901 | FILE |
|---|---|---|---|---|
| 1 | A | B | AA | data_201901.csv |
| 2 | C | D | NaN | data_201902.csv |
如果你需要比较两个csv文件与Python和熊猫的差异,你可以检查:Python Pandas基于一个列比较两个csv文件
更多关于Pandas concat: panda .concat
Windows/Linux:合并多个文件
除了使用Python合并CSV,你还可以使用不同操作系统提供的命令实现CSV文件合并,下面介绍CSV文件合并在Linux和Windows上的两种实现。
Linux
更多细节你可以检查: 如何在Linux Mint合并多个CSV文件
有时候,使用操作系统自带的工具或者庞大的文件就足够了。使用python连接多个大文件可能很有挑战性。在这种情况下,Linux可以使用:
sed 1d data_*.csv > merged.csv在本例中,我们在当前文件夹中工作,方法是匹配所有以data_开头的文件。这一点很重要,因为如果你想执行如下操作:
sed 1d *.csv > merged.csv你还将尝试合并新输出文件,这可能会导致问题。另一个重要的注意事项是,这将跳过每个文件的第一行或头。为了包含头文件,你可以这样做:
sed -n 1p data_1.csv > merged.csv
sed 1d data_*.csv >> merged.csv如果上面的命令对您不起作用,那么您可以尝试使用下面两个命令。第一个会合并所有csv文件,但如果文件结束时没有换行就会有问题:
head -n 1 1.csv > combined.out && tail -n+2 -q *.csv >> merged.out第二个将合并文件,并在末尾添加新行:
head -n 1 1.csv > combined.out
for f in *.csv; do tail -n 2 "$f"; printf "\n"; done >> merged.outWindows
与此对应的Windows将是:
C:\> copy data_*.csv merged.csv 或者
type data_*.csv > merged.csv 如何合并两个或多个CSV文件为一个文件?以上就是Python合并CSV的详细操作步骤了,其中又分为使用Python合并CSV和使用操作系统的命令合并CSV文件,希望可以帮到你,如果发现问题或错误,请在下方评论。

