
数据可视化是以图形格式表示数据。它通过以简单易懂的格式汇总和呈现大量数据来帮助人们了解数据的重要性, 并有助于清晰有效地传达信息。
用于分析和显示数据的不同类型的图表
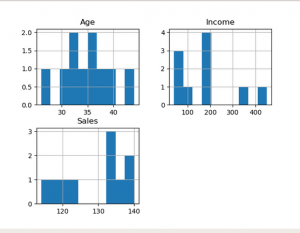
1.直方图:
直方图表示出现在特定值范围内并以连续和固定间隔排列的特定现象的发生频率。
在下面的代码中, 直方图被绘制为年龄, 收入, 销售。因此, 输出中的这些图显示了每个属性的每个唯一值的频率。
# import pandas and matplotlib
import pandas as pd
import matplotlib.pyplot as plt
# create 2D array of table given above
data = [[ 'E001' , 'M' , 34 , 123 , 'Normal' , 350 ], [ 'E002' , 'F' , 40 , 114 , 'Overweight' , 450 ], [ 'E003' , 'F' , 37 , 135 , 'Obesity' , 169 ], [ 'E004' , 'M' , 30 , 139 , 'Underweight' , 189 ], [ 'E005' , 'F' , 44 , 117 , 'Underweight' , 183 ], [ 'E006' , 'M' , 36 , 121 , 'Normal' , 80 ], [ 'E007' , 'M' , 32 , 133 , 'Obesity' , 166 ], [ 'E008' , 'F' , 26 , 140 , 'Normal' , 120 ], [ 'E009' , 'M' , 32 , 133 , 'Normal' , 75 ], [ 'E010' , 'M' , 36 , 133 , 'Underweight' , 40 ] ]
# dataframe created with
# the above data array
df = pd.DataFrame(data, columns = [ 'EMPID' , 'Gender' , 'Age' , 'Sales' , 'BMI' , 'Income' ] )
# create histogram for numeric data
df.hist()
# show plot
plt.show()输出:
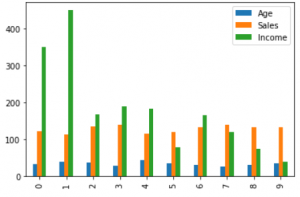
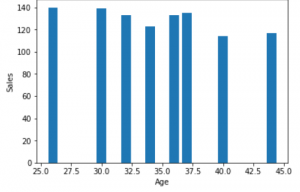
2.柱形图:
柱形图用于显示不同属性之间的比较, 也可以显示一段时间内各项的比较。
# Dataframe of previous code is used here
# Plot the bar chart for numeric values
# a comparison will be shown between
# all 3 age, income, sales
df.plot.bar()
# plot between 2 attributes
plt.bar(df[ 'Age' ], df[ 'Sales' ])
plt.xlabel( "Age" )
plt.ylabel( "Sales" )
plt.show()输出:
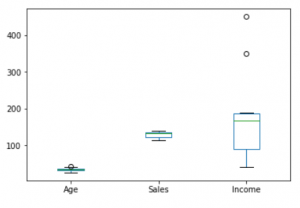
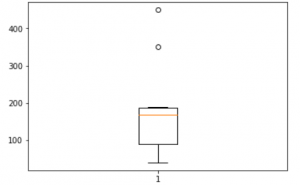
3.箱形图:
箱形图是基于
最小, 第一四分位数, 中位数, 第三四分位数和最大值
。术语"箱形图"来自以下事实:图形看起来像一个矩形, 其线条从顶部和底部延伸。由于线条的延长, 这种类型的图有时称为盒须图。有关分位数和中位数, 请参考此
分位数和中位数
.
# For each numeric attribute of dataframe
df.plot.box()
# individual attribute box plot
plt.boxplot(df[ 'Income' ])
plt.show()输出:
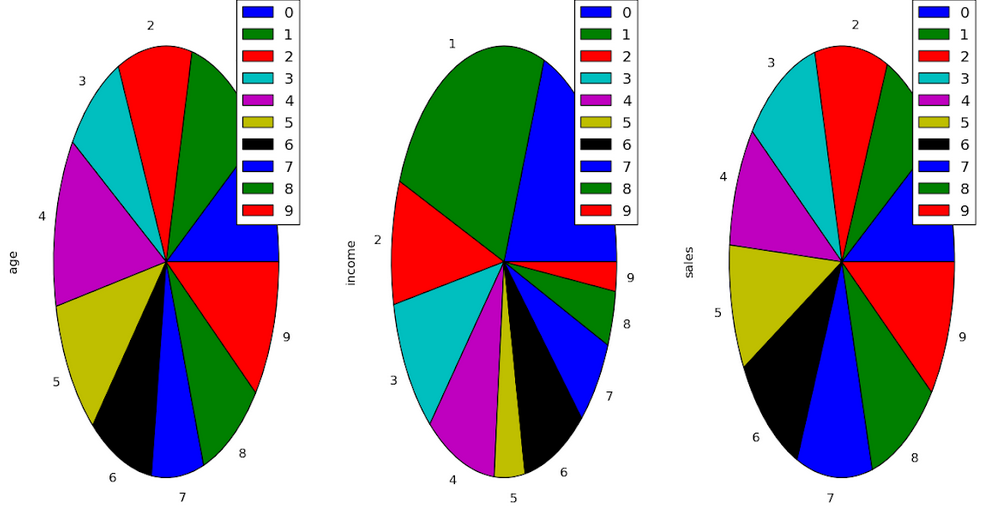
4.饼图:
饼形图显示了一个静态数字, 以及类别如何代表整个事物的组成部分。饼图以百分比表示数字, 所有细分的总和必须等于100%。
plt.pie(df[ 'Age' ], labels = { "A" , "B" , "C" , "D" , "E" , "F" , "G" , "H" , "I" , "J" }, autopct = '% 1.1f %%' , shadow = True )
plt.show()
plt.pie(df[ 'Income' ], labels = { "A" , "B" , "C" , "D" , "E" , "F" , "G" , "H" , "I" , "J" }, autopct = '% 1.1f %%' , shadow = True )
plt.show()
plt.pie(df[ 'Sales' ], labels = { "A" , "B" , "C" , "D" , "E" , "F" , "G" , "H" , "I" , "J" }, autopct = '% 1.1f %%' , shadow = True )
plt.show()输出:
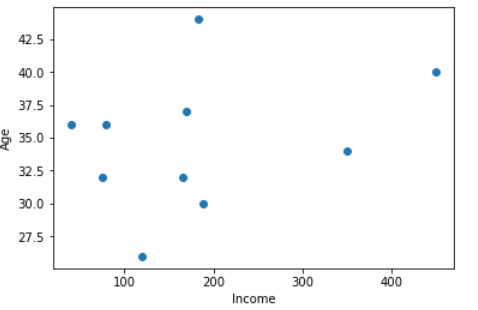
5.散点图:
散点图显示了两个不同变量之间的关系, 并且可以揭示分布趋势。当有许多不同的数据点, 并且你想突出显示数据集的相似性时, 应使用它。在寻找异常值和了解数据分布时, 这很有用。
# scatter plot between income and age
plt.scatter(df[ 'income' ], df[ 'age' ])
plt.show()
# scatter plot between income and sales
plt.scatter(df[ 'income' ], df[ 'sales' ])
plt.show()
# scatter plot between sales and age
plt.scatter(df[ 'sales' ], df[ 'age' ])
plt.show()输出:
注意怪胎!巩固你的基础Python编程基础课程和学习基础知识。
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。

