
Hadoop Mapreduce工作原理介绍
MapReduce 是 Apache Hadoop 项目中的一个处理模块。Hadoop 是一个平台,旨在使用计算机网络来存储和处理数据来处理大数据。
Hadoop 如此吸引人的地方在于,负担得起的专用服务器足以运行集群。你可以使用低成本的消费硬件来处理你的数据。
Hadoop Mapreduce是如何工作的?Hadoop 具有高度可扩展性。你可以从低至一台机器开始,然后将你的集群扩展到无限数量的服务器。该软件库的两个主要默认组件是:
- MapReduce
- HDFS—— Hadoop分布式文件系统
如何理解Hadoop Mapreduce?在本文中,我们将讨论两个模块中的第一个。你将了解 MapReduce 是什么、它是如何工作的以及基本的 Hadoop MapReduce 术语。
注意:如果你想开始使用 Hadoop,请按照我们在 Ubuntu上安装 Hadoop的指南进行操作。
什么是 Hadoop MapReduce?
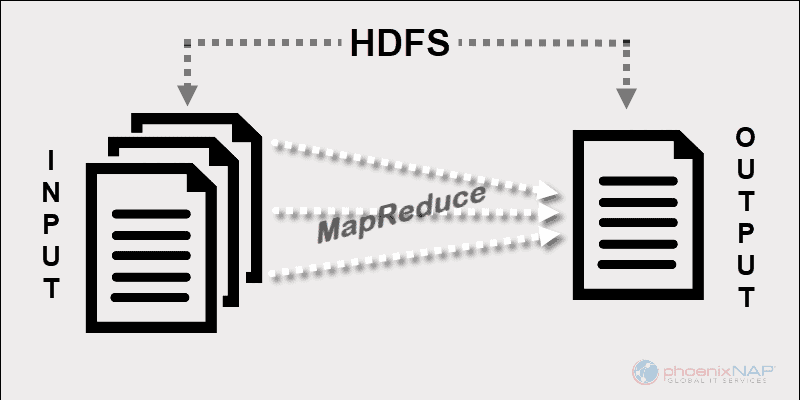
Hadoop MapReduce 的编程模型有助于处理存储在 HDFS 上的大数据。
MapReduce通过利用多台互联机器的资源,有效处理大量结构化和非结构化数据。
在Spark和其他现代框架之前,这个平台是分布式大数据处理领域的唯一参与者。
MapReduce 在 Hadoop 集群中的节点之间分配数据片段。目标是将数据集拆分为块,并使用算法同时处理这些块。多台机器上的并行处理大大提高了处理 PB 级数据的速度。
分布式数据处理应用
该框架允许编写用于分布式数据处理的应用程序。通常,Java 是大多数程序员使用的,因为Hadoop 是基于 Java 的。
但是,你可以使用其他语言(例如 Ruby 或 Python)编写 MapReduce 应用程序。无论开发人员使用何种语言,都无需担心运行 Hadoop 集群的硬件。
可扩展性
Hadoop 基础架构可以使用企业级服务器以及商品硬件。MapReduce 创建者考虑了可扩展性。如果添加更多机器,则无需重写应用程序。只需更改集群设置,MapReduce 就会继续工作而不会中断。
MapReduce 如此高效的原因在于它运行在与 HDFS 相同的节点上。该调度分配任务到数据已经驻留的节点。以这种方式操作会增加集群中的可用吞吐量。
注意:如果你准备好阅读有关 Hadoop 的深入文章,请参阅Hadoop 架构解释(附图表)。
MapReduce 的工作原理
Hadoop Mapreduce是如何工作的?从高层次来看,MapReduce 将输入数据分解成片段并将它们分布在不同的机器上。
输入片段由键值对组成。并行映射任务处理集群中机器上的分块数据。然后映射输出作为reduce阶段的输入。reduce 任务将结果组合成特定的键值对输出,并将数据写入 HDFS。
Hadoop Mapreduce工作原理介绍:Hadoop 分布式文件系统通常与 MapReduce 软件运行在同一组机器上。当框架在也存储数据的节点上执行作业时,完成任务的时间会显着减少。
Hadoop MapReduce 基本术语
正如我们上面提到的,MapReduce 是 Hadoop 环境中的一个处理层。MapReduce 处理与作业相关的任务。这个想法是通过将一个大的请求切成更小的单元来解决它。
作业跟踪器和任务跟踪器
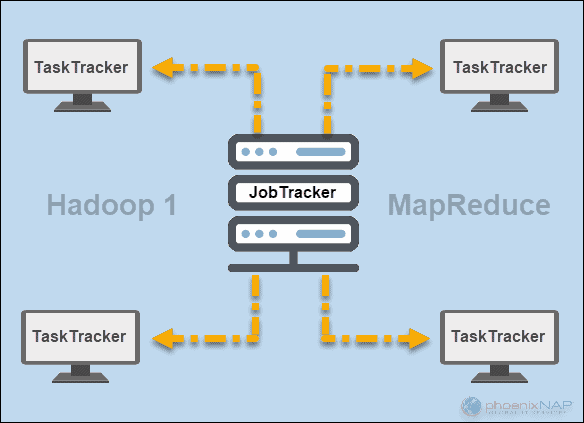
在 Hadoop(版本 1)的早期,JobTracker和TaskTracker守护进程在 MapReduce 中运行操作。当时,Hadoop 集群只能支持 MapReduce 应用程序。
一个JobTracker的控制集群应用程序的请求的计算资源的分配。由于它监视 MapReduce 的执行和状态,因此它驻留在主节点上。
一个TaskTracker共同处理来自JobTracker的附带的请求。所有任务跟踪器都分布在 Hadoop 集群中的从节点上。
Yarn
后来在 Hadoop 版本 2 及更高版本中,YARN 成为主要的资源和调度管理器。因此,名称为Yet Another Resource Manager。Yarn 还使用其他框架在 Hadoop 集群中进行分布式处理。
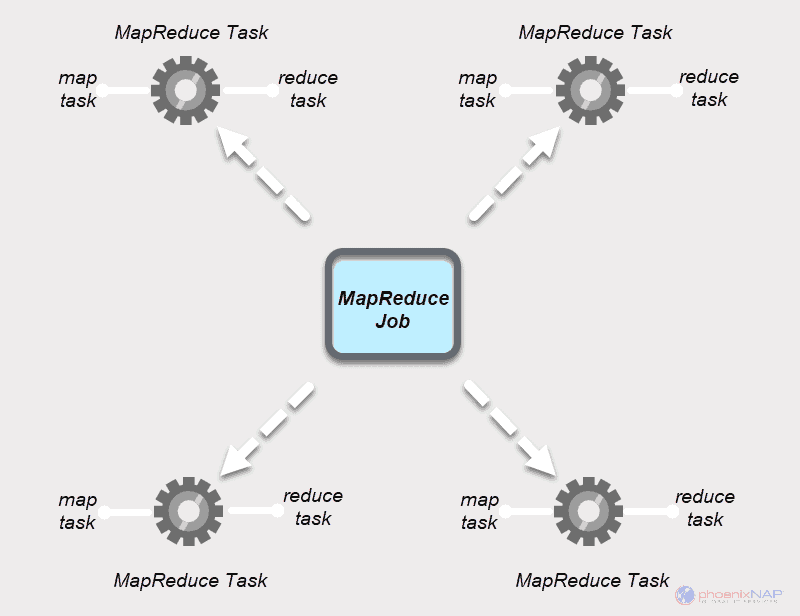
MapReduce 作业
一个MapReduce工作是在MapReduce的过程中工作的顶部单元。这是 Map 和 Reduce 进程需要完成的一项任务。一个作业在一组机器上被分成更小的任务,以便更快地执行。
任务应该足够大以证明任务处理时间是合理的。如果你将作业划分为异常小的段,则准备拆分和创建任务的总时间可能会超过生成实际作业输出所需的时间。
MapReduce 任务
MapReduce 作业有两种类型的任务。
一个映射的任务是MapReduce的应用程序的单个实例。这些任务确定要处理数据块中的哪些记录。输入数据在 Hadoop 集群中分配的计算资源上并行拆分和分析。MapReduce 作业的此步骤为缩减步骤准备 <key, value> 对输出。
甲Reduce任务处理映射任务的输出。与map阶段类似,所有reduce任务同时发生,独立工作。数据被聚合和组合以提供所需的输出。最终结果是一组简化的 <key, value> 对,MapReduce 默认将其存储在 HDFS 中。
注意: Reduce阶段并不总是必要的。有些MapReduce任务不需要结合map任务输出的数据。这些MapReduce应用程序被称为仅映射作业。
Map和Reduce阶段各有两个部分。
Map部分首先处理分配给各个映射任务的输入数据的分割。然后,映射函数以中间键-值对的形式创建输出。
Reduce阶段有一个洗牌和一个Reduce步骤。shuffle接受映射输出并创建相关键值-列表对的列表。然后,reduce将洗牌的结果聚合起来,生成MapReduce应用程序请求的最终输出。
Hadoop Map 和 Reduce 如何协同工作
Hadoop Mapreduce工作原理介绍:顾名思义,MapReduce在两个阶段处理输入数据——Map和Reduce。为了演示这一点,我们将使用一个简单的示例来计算每个文档中出现的单词的数量。
我们要查找的最终输出是:Apache、Hadoop、Class和Track在所有文档中总共出现了多少次。
Hadoop Mapreduce是如何工作的?出于演示的目的,示例环境由三个节点组成。输入包含分布在集群中的6个文档。这里我们简单点,但在实际情况中,没有限制。你可以拥有成千上万的服务器和数十亿的文档。
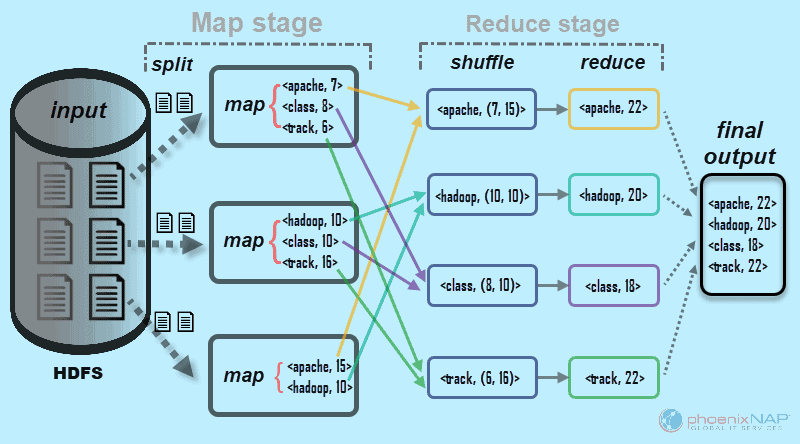
1.如何理解Hadoop Mapreduce?首先,在映射阶段,输入数据(六个文档)被分割并分布到集群(三个服务器)。在本例中,每个映射任务在包含两个文档的分割上工作。在映射过程中,节点之间没有通信。他们独立执行。
2.然后,map任务为每个单词创建一个<key,value>对。这些配对显示了一个单词出现的次数。一个字是一个键,一个值是它的计数。例如,一个文档包含我们正在查找的四个单词中的三个:Apache 7次,Class 8次,Track 6次。一个map任务输出的键值对如下所示:
- <apache, 7>
- <class, 8>
- <track, 6>
此过程在所有文档的所有节点上的并行任务中完成,并提供唯一的输出。
3.输入分割和映射完成后,对每个映射任务的输出进行洗牌。这是Reduce阶段的第一步。因为我们在寻找四个单词出现的频率,所以有四个并行的Reduce任务。reduce任务可以在与map任务相同的节点上运行,也可以在任何其他节点上运行。
shuffle步骤确保在reduce步骤中对Apache、Hadoop、Class和Track键进行排序。这个过程按键将值分组,键的形式为<key,value-list>对。
4.在Reduce阶段的reduce步骤中,四个任务中的每一个都处理一个<key, value-list>,以提供最终的键值对。reduce 任务也同时发生并独立工作。
在图中的示例中,reduce 任务获得以下单独的结果:
- <apache, 22>
- <hadoop, 20>
- <class, 18>
- <track, 22>
注意: MapReduce 过程不一定是连续的。Reduce 阶段不必等待所有 map 任务完成。一旦 map 输出可用,reduce 任务就可以开始了。
5.最后,Reduce 阶段的数据被分组为一个输出。MapReduce 现在向我们展示了Apache、Hadoop、Class和track在所有文档中出现的次数。默认情况下,聚合数据存储在 HDFS 中。
我们在这里使用的示例是一个基本示例。MapReduce 执行更复杂的任务。
一些用例包括:
- 将 Apache 日志转换为制表符分隔值 (TSV)。
- 确定博客数据中唯一 IP 地址的数量。
- 执行复杂的统计建模和分析。
- 使用不同的框架(例如 Mahout)运行机器学习算法。
Hadoop Mapreduce工作原理介绍:Hadoop 分区如何映射输入数据
分区器负责处理Map输出。一旦 MapReduce 将数据分成块并将它们分配给映射任务,框架就会对键值数据进行分区。此过程发生在生成最终映射器任务输出之前。
MapReduce 根据键对输出进行分区和排序。在这里,单个键的所有值都被分组,分区器创建一个包含与每个键关联的值的列表。通过将单个键的所有值发送到同一个减速器,分区器确保映射输出到减速器的平均分配。
注意: map 输出文件的数量取决于不同分区键的数量和配置的 reducer 数量。减速器的数量在减速器配置文件中定义。
如何理解Hadoop Mapreduce?默认分区器已针对许多用例进行了良好配置,但你可以重新配置 MapReduce 对数据进行分区的方式。
如果碰巧使用自定义分区器,请确保为每个减速器准备的数据大小大致相同。当你不均匀地对数据进行分区时,一项reduce 任务可能需要更长的时间才能完成。这会减慢整个 MapReduce 工作的速度。
结论
Hadoop Mapreduce是如何工作的?处理大数据的挑战在于,传统工具还没有准备好处理输入数据的数量和复杂性。这就是 Hadoop MapReduce 发挥作用的地方。
使用 MapReduce 的好处包括并行计算、错误处理、容错、日志记录和报告。本文提供了理解 MapReduce 的工作原理及其基本概念的起点。

