
Spark Streaming使用教程
Spark Streaming 是 Spark API 的附加功能,用于实时流式传输和处理大规模数据。Spark Streaming 不是处理大量非结构化原始数据并在之后进行清理,而是执行近乎实时的数据处理和收集。
这个Spark Streaming初学者指南解释了 Spark Streaming 是什么、它是如何工作的,并提供了一个流数据的示例用例。
先决条件
- 安装和配置 Apache Spark(按照我们的指南:如何在 Ubuntu上安装 Spark,如何在 Windows 10 上安装 Spark)
- 为 Spark 设置的环境(我们将在 Jupyter 笔记本中使用 Pyspark)。
- 数据流(我们将使用 Twitter API)。
- Python 库tweepy、json和socket用于从 Twitter 流式传输数据(使用 pip 安装它们)。
Spark Streaming使用教程:什么是 Spark Streaming?
Spark Streaming 是一个 Spark 库,用于处理近乎连续的数据流。核心抽象是由 Spark DStream API 创建的Discretized Stream,用于将数据分批。DStream API 由 Spark RDD(弹性分布式数据集)提供支持,允许与其他 Apache Spark 模块(如 Spark SQL 和 MLlib)无缝集成。
企业在许多不同的用例中利用 Spark Streaming 的强大功能:
- 实时流 ETL –在存储之前清理和组合数据。
- 持续学习——用新信息不断更新机器学习模型。
- 事件触发——实时检测异常。
- 丰富数据——在存储之前向数据添加统计信息。
- 实时复杂会话– 对用户活动进行分组以进行分析。
流媒体方法允许更快的客户行为分析、更快的推荐系统和实时欺诈检测。对于工程师来说,在收集数据时可以看到来自物联网设备的任何类型的传感器异常。
注意:详细了解RDD 和 DataFrame 之间的区别。
Spark Streaming 的各个方面
Spark Streaming 本身支持批处理和流工作负载,这为数据馈送提供了令人兴奋的改进。这一独特的方面满足了现代数据流系统的以下要求:
- 动态负载平衡。由于数据分为微批次,瓶颈不再是问题。传统架构一次处理一条记录,一旦出现计算密集型分区,它就会阻止该节点上的所有其他数据。使用 Spark Streaming,任务在工作人员之间分配,根据可用资源的不同,一些处理时间较长的任务,一些处理较短的任务。
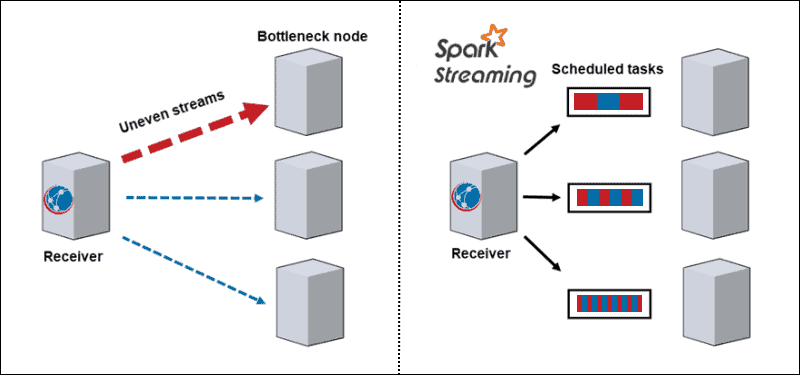
- 故障恢复。一个节点上的失败任务离散化并分配给其他工作人员。当工作节点执行计算时,落后者有时间恢复。
- 交互式分析。DStreams 是一系列 RDD。存储在工作内存中的批量流式数据以交互方式查询。
- 高级分析。DStreams 生成的 RDDs 转换成DataFrames,用 SQL 查询并扩展到库,如 MLlib,以创建机器学习模型并将它们应用于流数据。
- 改进的流性能。批量流式传输可提高吞吐量性能,利用低至几百毫秒的延迟。
Spark Streaming初学者指南:Spark Streaming的优缺点
每种技术,包括 Spark Streaming,都有其优点和缺点:
| 优点 | 缺点 |
| 为复杂任务提供出色的速度性能 | 内存消耗大 |
| 容错 | 难以使用、调试和学习 |
| 在云集群上轻松实现 | 没有很好的文档记录,学习资源稀缺 |
| 多语言支持 | 数据可视化差 |
| Cassandra 和 MongoDB 等大数据框架的集成 | 数据量小,速度慢 |
| 能够加入多种类型的数据库 | 很少有机器学习算法 |
Spark Streaming 是如何工作的?
Spark Streaming 处理大规模和复杂的近实时分析。分布式流处理管道经过三个步骤:
1.从直播源接收流数据。
2.并行处理集群上的数据。
3.将处理后的数据输出到系统中。
Spark Streaming用法指南:Spark Streaming架构
Spark Streaming 的核心架构是离散化的批处理流。不是一次通过流处理管道一条记录,而是动态分配和处理微批次。因此,数据根据可用资源和位置传输给工作人员。
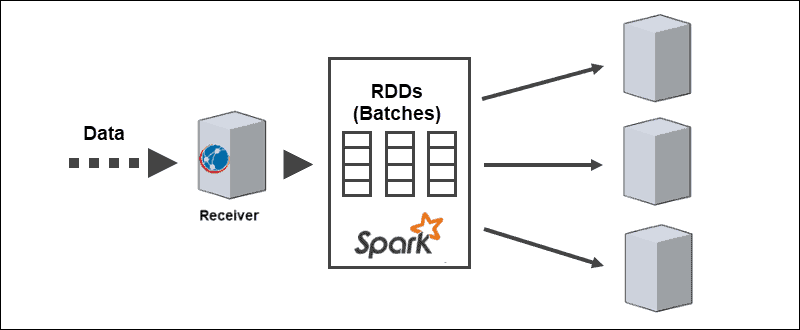
当数据到达时,接收者将其划分为 RDD 的分区。转换为 RDD 允许使用 Spark 代码和库处理批处理,因为 RDD 是 Spark 数据集的基本抽象。
Spark Streaming源
数据流需要从源接收的数据。Spark Streaming 将这些源分为两类:
- 基本来源。Streaming 核心 API 中直接可用的源,例如与HDFS兼容的套接字连接和文件系统
- 高级来源。源需要链接依赖项,并且在 Streaming 核心 API 中不可用,例如Kafka或 Kinesis。
每个输入 DStream 都连接到一个接收器。对于并行数据流,创建多个 DStream 也会生成多个接收器。
注意:确保分配足够的 CPU 内核或线程。接收器使用共享资源,但处理并行流数据也需要计算能力。
Spark Streaming使用教程:Spark Streaming操作
Spark Streaming 包括执行不同类型的操作:
1.转换操作修改从输入 DStreams 接收到的数据,类似于应用于 RDD 的那些。转换操作惰性求值,直到数据到达输出才执行。
2.输出操作将 DStreams 推送到外部系统,例如数据库或文件系统。转移到外部系统会触发转换操作。
注意:输出操作因编程语言而异。
3、DataFrame和SQL操作在将RDDs转换成DataFrames并注册为临时表进行查询时发生。
4. MLlib 操作用于执行机器学习算法,包括:
- 流式算法适用于实时数据,例如流式线性回归或流式 k 均值。
- 离线算法,用于使用历史数据离线学习模型并将该算法应用于在线流数据。
Spark Streaming示例
Streaming示例具有以下结构:
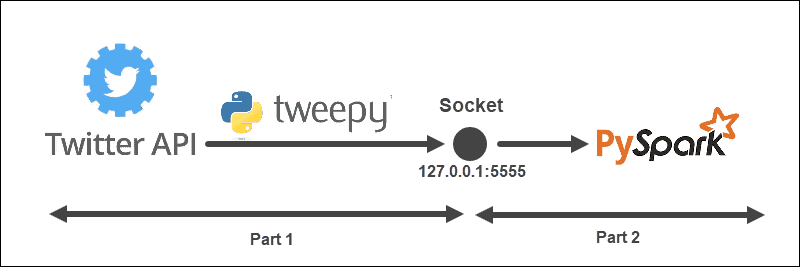
该架构分为两部分,从两个文件运行:
- 运行第一个文件以建立与 Twitter API 的连接并在 Twitter API 和 Spark 之间创建一个套接字。保持文件运行。
- 运行第二个文件以请求并开始流式传输数据,将处理后的推文打印到控制台。未处理的发送数据打印在第一个文件中。
Spark Streaming初学者指南:创建 Twitter 侦听器对象
所述TweetListener对象监听来自与Twitter的流的鸣叫StreamListener从tweepy。当通过套接字向服务器(本地)发出请求时,TweetListener侦听数据并提取推文信息(推文文本)。如果扩展 Tweet 对象可用,则 TweetListener 获取扩展字段,否则获取文本字段。最后,侦听器在每条推文的末尾添加__end。这一步后面会帮助我们过滤Spark中的数据流。
import tweepy
import json
from tweepy.streaming import StreamListener
class TweetListener(StreamListener):
# tweet object listens for the tweets
def __init__(self, csocket):
self.client_socket = csocket
def on_data(self, data):
try:
# Load data
msg = json.loads(data)
# Read extended Tweet if available
if "extended_tweet" in msg:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['extended_tweet']['full_text']+" __end")\
.encode('utf-8'))
print(msg['extended_tweet']['full_text'])
# Else read Tweet text
else:
# Add "__end" at the end of each Tweet
self.client_socket\
.send(str(msg['text']+"__end")\
.encode('utf-8'))
print(msg['text'])
return True
except BaseException as e:
print("error on_data: %s" % str(e))
return True
def on_error(self, status):
print(status)
return True如果连接中出现任何错误,控制台会打印信息。
Spark Streaming用法指南:收集 Twitter 开发人员凭据
Twitter开发人员门户包含用于与 Twitter 建立 API 连接的 OAuth 凭据。该信息位于应用程序密钥和令牌选项卡中。
收集数据:
1. 生成位于项目Consumer Keys部分的API key & Secret并保存信息:
该消费者密钥验证到Twitter你的身份,就像一个用户名。
2.从Authentication Tokens部分生成Access Token & Secret并保存信息:
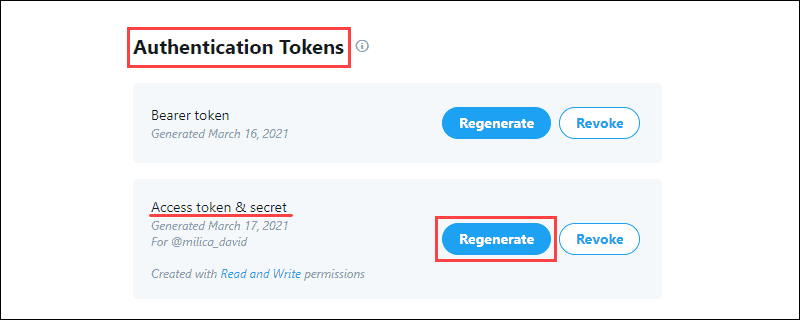
该认证令牌允许从Twitter拉动具体数据。
将数据从 Twitter API 发送到套接字
使用开发人员凭据,填写API_KEY、API_SECRET、ACCESS_TOKEN和ACCESS_SECRET以访问 Twitter API。
当客户端发出请求时,函数sendData运行 Twitter 流。首先验证流请求,然后创建一个侦听器对象,并根据关键字和语言过滤流数据。
例如:
from tweepy import Stream
from tweepy import OAuthHandler
API_KEY = "api_key"
API_SECRET = "api_secret"
ACCESS_TOKEN = "access_token"
ACCESS_SECRET = "access_secret"
def sendData(c_socket, keyword):
print("Start sending data from Twitter to socket")
# Authentication based on the developer credentials from twitter
auth = OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
# Send data from the Stream API
twitter_stream = Stream(auth, TweetListener(c_socket))
# Filter by keyword and language
twitter_stream.filter(track = keyword, languages=["en"])在服务器上创建侦听 TCP 套接字
第一个文件的最后一部分包括在本地服务器上创建一个侦听套接字。地址和端口被绑定并监听来自 Spark 客户端的连接。
例如:
import socket
if __name__ == "__main__":
# Create listening socket on server (local)
s = socket.socket()
# Host address and port
host = "127.0.0.1"
port = 5555
s.bind((host, port))
print("Socket is established")
# Server listens for connections
s.listen(4)
print("Socket is listening")
# Return the socket and the address of the client
c_socket, addr = s.accept()
print("Received request from: " + str(addr))
# Send data to client via socket for selected keyword
sendData(c_socket, keyword = ['covid'])一旦 Spark 客户端发出请求,客户端的套接字和地址就会打印到控制台。然后,根据选择的关键字过滤器将数据流发送到客户端。
此步骤结束第一个文件中的代码。运行它会打印以下信息:

保持文件运行并继续创建 Spark 客户端。
Spark Streaming初学者指南:创建 Spark DStream 接收器
在另一个文件中,以一秒的批处理间隔创建 Spark 上下文和本地流上下文。客户端从主机名和端口套接字读取。
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext(appName="tweetStream")
# Create a local StreamingContext with batch interval of 1 second
ssc = StreamingContext(sc, 1)
# Create a DStream that conencts to hostname:port
lines = ssc.socketTextStream("127.0.0.1", 5555)Spark Streaming使用教程:预处理数据
RDD 的预处理包括拆分接收到的数据行,其中__end出现并将文本转换为小写。前十个元素打印到控制台。
# Split Tweets
words = lines.flatMap(lambda s: s.lower().split("__end"))
# Print the first ten elements of each DStream RDD to the console
words.pprint()运行代码后,没有任何反应,因为评估是惰性的。计算在流上下文开始时开始。
Spark Streaming用法指南:开始流式处理上下文和计算
启动流上下文向主机发送请求。主机将 Twitter 收集到的数据发送回 Spark 客户端,客户端对数据进行预处理。然后控制台打印结果。
# Start computing
ssc.start()
# Wait for termination
ssc.awaitTermination()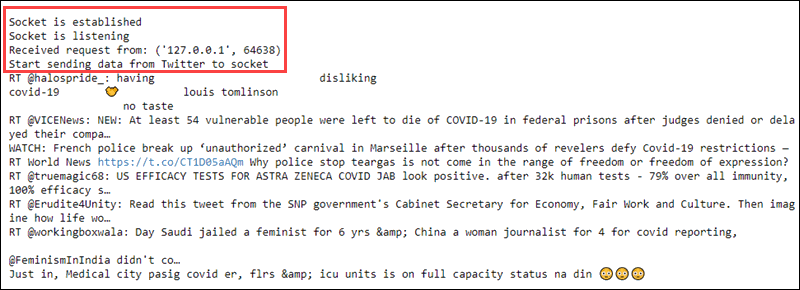
启动streaming上下文将接收到的请求打印到第一个文件并流式传输原始数据文本:
第二个文件每秒从套接字读取数据,并对数据进行预处理。在连接建立之前,前几行是空的:
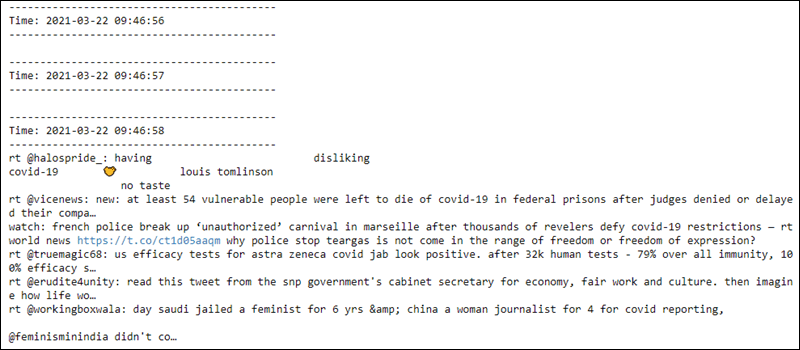
streaming上下文随时可以终止。
Spark Streaming初学者指南总结
Spark Streaming 是一种用于大数据收集和处理的工具。通过阅读本文,你了解了如何在使用其他 Spark API 时将数据转换为 RDD。

