
介绍
Apache Storm与Spark有什么不同?Apache Storm 和 Spark 是用于处理实时数据流的大数据处理平台。这两种技术的核心区别在于它们处理数据的方式。Storm 并行化任务计算,而 Spark 并行化数据计算。但是,API 之间还存在其他基本差异。
Apache Storm与Spark哪个更好?本文提供了 Apache Storm 与 Spark Streaming 的深入比较。
Storm 与 Spark:定义
Apache Storm是一个实时流处理框架。所述三叉戟抽象层提供与Storm备选接口,添加实时分析操作。
另一方面,Apache Spark是用于大规模数据的通用分析框架。在星火流API可用于在接近实时的数据流,旁边的框架内与其他分析工具。
Apache Storm与Spark有哪些区别
Storm 和 Spark 都是具有类似意图的免费使用和开源 Apache 项目。下表概述了两种技术之间的主要区别:
| Storm | Spark | |
|---|---|---|
| 编程语言 | 多语言集成 | 支持 Python、R、Java、Scala |
| 加工模型 | 通过 Trident 提供微批处理的流处理 | 可通过 Streaming 使用微批处理进行批处理 |
| 原语 | 元组流 元组批处理 分区 | 数据流 |
| 可靠性 | 恰好一次(三叉戟) 至少一次 最多一次 | 正好一次 |
| 容错 | 由主管进程自动重启 | Worker 通过资源管理器重启 |
| 状态管理 | 通过三叉戟支持 | 通过流媒体支持 |
| 便于使用 | 更难操作和部署 | 更易于管理和部署 |
Apache Storm与Spark有什么不同:编程语言
与其他编程语言集成的可用性是在 Storm 和 Spark 之间进行选择时的首要因素之一,也是这两种技术之间的主要区别之一。
Storm
Storm 具有多语言功能,几乎可用于任何编程语言。用于流式处理和处理的 Trident API 兼容:
- Java
- Clojure
- Scala
Spark
Spark 为以下语言提供高级流 API:
- Java
- Scala
- Python
某些高级功能(例如来自自定义源的流式传输)对 Python 不可用。但是,来自高级外部源(例如 Kafka 或 Kinesis)的流式传输适用于所有三种语言。
加工模型
Apache Storm与Spark有哪些区别?处理模型定义了如何实现数据流。信息以下列方式之一处理:
- 一次记录一张。
- 在离散批次中。
Storm
核心Storm的处理模型直接对元组流进行操作,一次一条记录,使其成为一种合适的实时流技术。Trident API 添加了使用微批次的选项。
Spark
Spark 处理模型将数据分成批次,在进一步处理之前对记录进行分组。Spark Streaming API 提供了将数据拆分为微批次的选项。
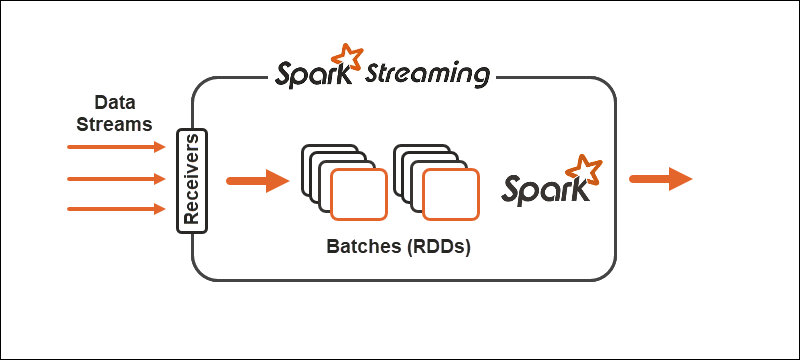
原语
原语代表了两种技术的基本构建块以及对数据执行转换操作的方式。
Storm
Core Storm 操作元组流,而 Trident 操作元组批次和分区。Trident API 以类似于Hadoop的高级抽象的类似方式处理集合。Storm的主要原语是:
- Spouts 产生来自源的实时流。
- Bolts 执行数据处理并保持持久性的。
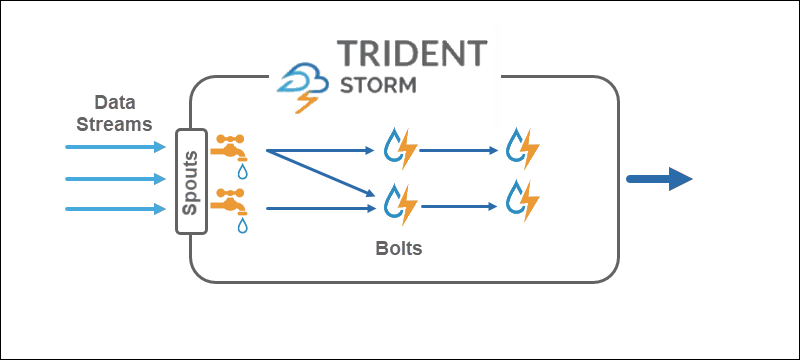
在 Trident 拓扑中,操作分组为Bolts 。分组依据、联接、聚合、运行函数和过滤器可用于隔离的批次和不同的集合。聚合持久存储在由HDFS支持的内存中或其他一些存储中,如Cassandra。
Spark
使用 Spark Streaming,连续的数据流分为离散流(DStreams),即一系列弹性分布式数据库(RDD)。
Spark 允许在原语上使用两种通用类型的运算符:
1.流转换运算符,其中一个 DStream 转换为另一个 DStream。
2.输出操作符帮助将信息写入外部系统。
注意:查看RDD API的Spark DataFrame扩展以提高效率。
可靠性
可靠性是指数据交付的保证。在处理数据流可靠性时,有三种可能的保证:
- 至少一次。数据交付一次,也有可能多次交付。
- 最多一次。数据只传递一次,任何重复都会丢弃。存在数据未到达的可能性。
- 正好一次。数据一次交付,没有任何损失或重复。尽管很难实现,但保证选项最适合数据流。
Storm
Storm 在数据流可靠性方面非常灵活。在其核心,至少一次和至多一次选项是可能的。与 Trident API 一起,所有三种配置都可用。
Spark
Apache Storm与Spark有哪些区别?Spark 试图通过专注于一次性数据流配置来采取最佳路线。如果工人或驱动程序失败,则至少应用一次语义。
容错
容错定义了流技术在发生故障时的行为。Spark 和 Storm 都具有相似级别的容错能力。
Spark
在 worker 失败的情况下,Spark 通过资源管理器重新启动 worker,例如YARN。驱动程序故障使用数据检查点进行恢复。
Storm
如果 Storm 或 Trident 中的进程失败,则监督进程会自动处理重新启动。ZooKeeper在状态恢复和管理中起着至关重要的作用。
状态管理
Spark Streaming 和 Storm Trident 都内置了状态管理技术。状态跟踪有助于实现容错以及精确一次交付保证。
Apache Storm与Spark有什么不同:易于使用和开发
易于使用和开发取决于该技术的文档化程度以及操作流的容易程度。
Spark
Spark 更容易部署和开发这两种技术。Streaming 有很好的文档记录并部署在 Spark 集群上。流作业可与批处理作业互换。
注意:查看我们关于在 Bare Metal Cloud上自动部署 Spark Cluster 的四步教程。
Storm
Storm 的配置和开发有点棘手,因为它包含对 ZooKeeper 集群的依赖。使用 Storm 的优势在于多语言特性。
Apache Storm与Spark哪个更好?
Storm 和 Spark 之间的选择取决于项目以及可用的技术。主要因素之一是编程语言和数据交付可靠性的保证。
虽然两种数据流和处理之间存在差异,但最好的方法是测试这两种技术,看看哪种技术最适合你和手头的数据流。
结论
Apache Storm与Spark有哪些区别?带有 Trident API 的 Apache Storm 和 Spark Streaming API 是类似的技术。这篇文章提供了 Storm 与 Spark 的正面比较,因此你可以做出明智的决定。
此外,请考虑你希望如何存储流数据以及你将需要的服务器资源类型。在我们的文章中阅读有关 Cassandra 与 MongoDB 的比较,以了解哪种数据库适合你:Cassandra 与 MongoDB - 有何不同?

