
Spark DataFrame创建教程介绍
学习如何创建Spark DataFrame是 Spark 环境中的第一个实际步骤之一。Spark DataFrames 有助于提供数据结构和其他数据操作功能的视图。根据数据源和文件的数据存储格式,存在不同的方法。
本文介绍了如何使用 PySpark 在 Python 中手动创建 Spark DataFrame,包括相关的Spark DataFrame创建示例。
先决条件
- 安装并配置了Python 3。
- 安装并配置了PySpark。
- 一个Python开发环境,准备测试代码示例(我们使用的是Jupyter笔记本电脑)。
创建 Spark DataFrame 的方法
如何创建Spark DataFrame?在 Spark 中手动创建 DataFrame 有以下三种方式:
1.创建一个列表,并使用解析它为DataFrametoDataFrame()从方法SparkSession。
2. 使用toDF()方法将 RDD 转换为 DataFrame 。
3.SparkSession直接将文件作为DataFrame导入。
这些示例使用示例数据和 RDD 进行演示,尽管一般原则适用于类似的数据结构。
注意: Spark 还提供了一个 Streaming API,用于近乎实时地流式传输数据。按照我们的动手指南试用 API:Spark Streaming Guide for Beginners。
Spark DataFrame创建教程:从数据列表创建 DataFrame
要从数据列表创建 Spark DataFrame:
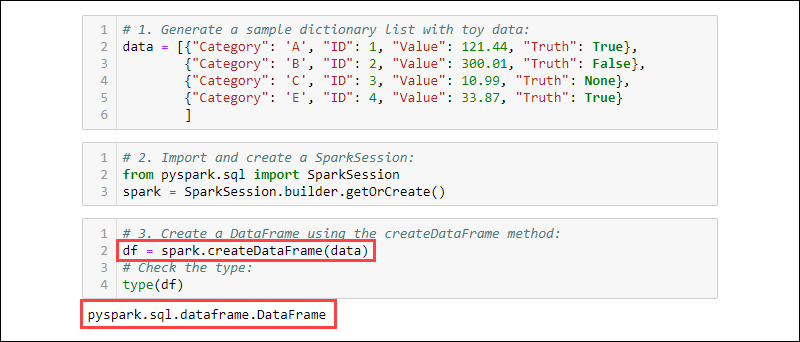
1. 用数据生成样本字典列表:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. 导入并创建一个SparkSession:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
3. 使用该createDataFrame方法创建一个DataFrame 。检查数据类型以确认变量是 DataFrame:
df = spark.createDataFrame(data)
type(df)
从 RDD 创建 DataFrame
如何创建Spark DataFrame?在 Spark 中工作时的一个典型事件是从现有 RDD 创建一个 DataFrame。创建一个示例 RDD,然后将其转换为 DataFrame。
1. Spark DataFrame创建示例 - 制作一个包含玩具数据的字典列表:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
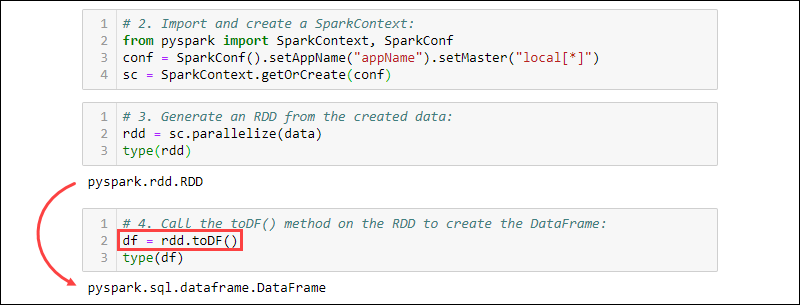
2. 导入并创建一个SparkContext:
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("projectName").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
3. 从创建的数据生成 RDD。检查类型以确认对象是 RDD:
rdd = sc.parallelize(data)
type(rdd)
4.调用toDF()RDD上的方法创建DataFrame。测试对象类型以确认:
df = rdd.toDF()
type(df)
从数据源创建 DataFrame
如何创建Spark DataFrame?Spark 可以处理大量外部数据源来构建 DataFrame。从文件读取的一般语法是:
spark.read.format('<data source>').load('<file path/file name>')数据源名称和路径都是 String 类型。特定数据源还具有将文件作为 DataFrame 导入的替代语法。
从 CSV 文件创建
通过直接读取 CSV 文件来创建 Spark DataFrame:
df = spark.read.csv('<file name>.csv')通过提供路径列表将多个 CSV 文件读入一个 DataFrame:
df = spark.read.csv(['<file name 1>.csv', '<file name 2>.csv', '<file name 3>.csv'])默认情况下,Spark 为每列添加一个标题。如果 CSV 文件具有要包含的标题,请option在导入时添加该方法:
df = spark.read.csv('<file name>.csv').option('header', 'true')单个选项通过一个接一个地调用来堆叠。或者,options在导入过程中需要更多选项时使用该方法:
df = spark.read.csv('<file name>.csv').options(header = True)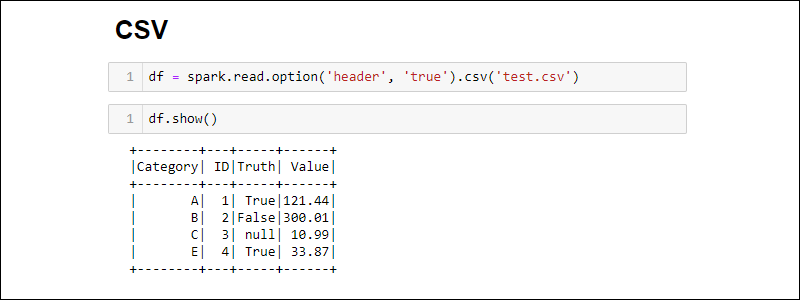
请注意,使用 optionvs.时的语法是不同的options。
从 TXT 文件创建
Spark DataFrame创建示例:从文本文件创建一个 DataFrame :
df = spark.read.text('<file name>.txt')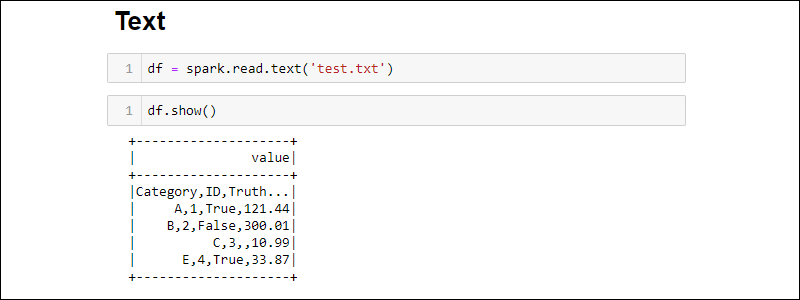
该csv方法是另一种从txt文件类型读取到 DataFrame 的方法。例如:
df = spark.read.option('header', 'true').csv('<file name>.txt')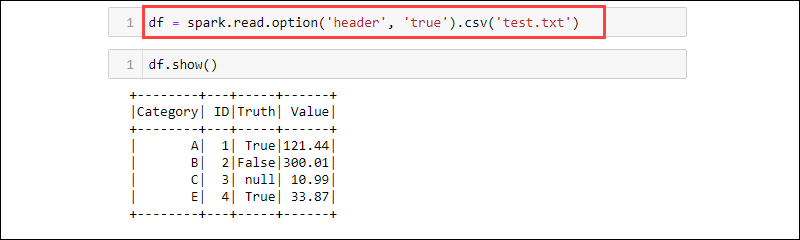
CSV 是一种文本格式,其中分隔符是逗号 (,),因此该函数能够从文本文件中读取数据。
Spark DataFrame创建教程:从 JSON 文件创建
通过运行以下命令从 JSON 文件创建 Spark DataFrame:
df = spark.read.json('<file name>.json')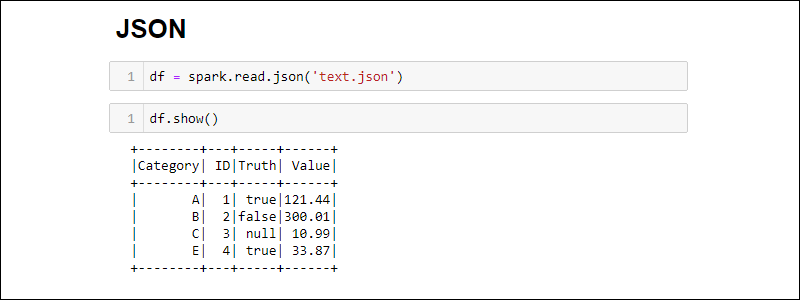
从 XML 文件创建
默认情况下,XML 文件兼容性不可用。安装依赖项以从 XML 源创建 DataFrame。
1. 下载Spark XML 依赖项。将.jar文件保存在 Spark jar 文件夹中。
2. 通过运行将 XML 文件读入 DataFrame:
df = spark.read\
.format('com.databricks.spark.xml')\
.option('rowTag', 'row')\
.load('test.xml')
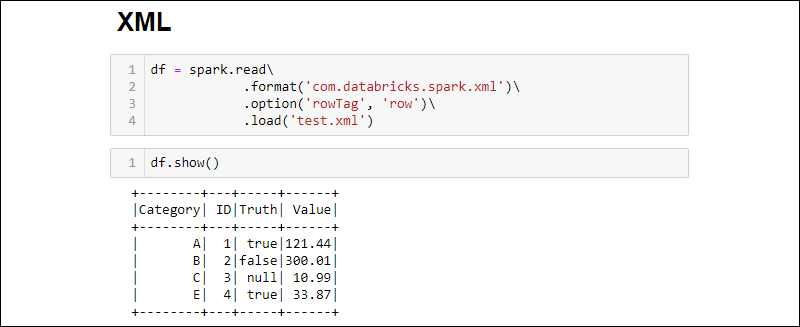
rowTag如果XML文件中的每一行都有不同的标签,请更改该选项。
从 RDBMS 数据库创建 DataFrame
如何创建Spark DataFrame?从RDBMS读取需要驱动程序连接器。该示例介绍了如何从 MySQL 数据库连接和提取数据。类似的步骤适用于其他数据库类型。
1. 下载MySQL Java Driver 连接器。将.jar文件保存在 Spark jar 文件夹中。
2. 运行SQL 服务器并建立连接。
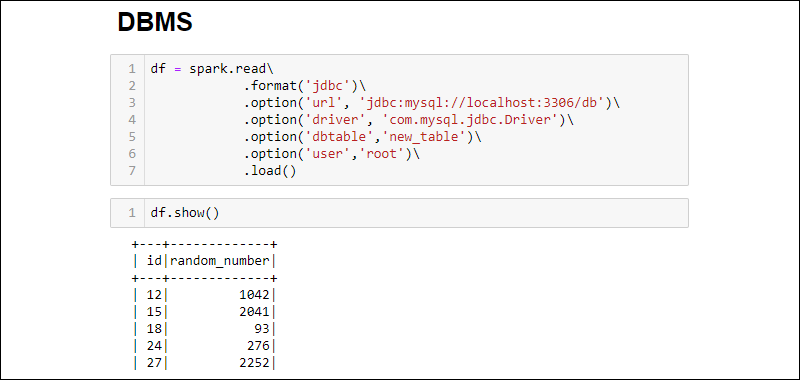
3. 建立连接并将整个 MySQL数据库表提取到一个 DataFrame 中:
df = spark.read\
.format('jdbc')\
.option('url', 'jdbc:mysql://localhost:3306/db')\
.option('driver', 'com.mysql.jdbc.Driver')\
.option('dbtable','new_table')\
.option('user','root')\
.load()
注意:需要创建数据库吗?按照我们的教程:如何在 Workbench 中创建 MySQL 数据库。
Spark DataFrame创建示例添加的选项如下:
- 该URL是
localhost:3306如果服务器在本地运行。否则,获取你的数据库服务器的 URL 。 - 数据库名称扩展 URL 以访问服务器上的特定数据库。例如,如果一个数据库被命名
db并且服务器在本地运行,则用于建立连接的完整 URL 是jdbc:mysql://localhost:3306/db. - 表名确保整个数据库表被拉入DataFrame。使用
.option('query', '<query>')而不是.option('dbtable', '<table name>')运行特定查询而不是选择整个表。 - 使用数据库的用户名和密码建立连接。在没有密码的情况下运行时,省略指定的选项。
Spark DataFrame创建教程总结
如何创建Spark DataFrame?有多种方法可以创建 Spark DataFrame。方法因数据源和格式而异。使用不同的文件格式并与其他 Python 库结合进行数据操作,例如Python Pandas 库。
接下来,按照我们的教程之一学习如何处理 Python 中的缺失数据:在 Python 中处理缺失数据:原因和解决方案。

