
Python从URL中提取和提交Web表单教程:了解如何从网页中抓取表单,以及使用请求 html 和 Python 中的BeautifulSoup填充和提交它们。
网络抓取中最具挑战性的任务之一是能够自动登录并提取该网站上你帐户中的数据。在本教程中,你将学习如何从网页中提取所有表单以及使用requests_html和BeautifulSoup库填写和提交它们。
首先,让我们安装它们:
pip3 install requests_html bs4相关: 如何在Python 中使用 Selenium 自动登录。
从网页中提取表单
Python如何提取和提交Web表单?打开一个新文件,我称之为form_extractor.py:
from bs4 import BeautifulSoup
from requests_html import HTMLSession
from urllib.parse import urljoin如何使用Python提取和提交Web表单?首先,我们需要一种方法来确保在向目标网站发出请求后,我们正在存储该网站提供的 cookie,以便我们可以持久化会话:
# initialize an HTTP session
session = HTMLSession()现在该session变量是用于 cookie 持久性的可消耗会话,我们将在代码中的任何地方使用该变量。让我们编写一个函数,给定一个 URL,向该页面发出请求,并从中提取所有 HTML 表单标签,然后返回它们(作为列表):
def get_all_forms(url):
"""Returns all form tags found on a web page's `url` """
# GET request
res = session.get(url)
# for javascript driven website
# res.html.render()
soup = BeautifulSoup(res.html.html, "html.parser")
return soup.find_all("form")你可能注意到我注释掉了res.html.render()行,它基本上在尝试提取任何内容之前执行 Javascript,因为某些网站使用 Javascript 动态加载其内容,如果你觉得该网站使用 Javascript 加载,请取消注释形式。
Python从URL中提取和提交Web表单 - 因此,上述功能就可以从网页中提取各种形式,但我们需要一种方法来提取每个表格的详细信息,如输入,形式方法(GET,POST,DELETE等)和行动(目标URL表单提交)下面的函数是这样做的:
def get_form_details(form):
"""Returns the HTML details of a form,
including action, method and list of form controls (inputs, etc)"""
details = {}
# get the form action (requested URL)
action = form.attrs.get("action").lower()
# get the form method (POST, GET, DELETE, etc)
# if not specified, GET is the default in HTML
method = form.attrs.get("method", "get").lower()
# get all form inputs
inputs = []
for input_tag in form.find_all("input"):
# get type of input form control
input_type = input_tag.attrs.get("type", "text")
# get name attribute
input_name = input_tag.attrs.get("name")
# get the default value of that input tag
input_value =input_tag.attrs.get("value", "")
# add everything to that list
inputs.append({"type": input_type, "name": input_name, "value": input_value})
# put everything to the resulting dictionary
details["action"] = action
details["method"] = method
details["inputs"] = inputs
return details现在让我们在深入提交表单之前尝试这些功能:
url = "https://wikipedia.org"
# get all form tags
forms = get_all_forms(url)
# iteratte over forms
for i, form in enumerate(forms, start=1):
form_details = get_form_details(form)
print("="*50, f"form #{i}", "="*50)
print(form_details)我使用enumerate()只是为了计算提取的形式,这是Wikipedia主页的输出:
================================================== form #1 ==================================================
{'action': '//www.wikipedia.org/search-redirect.php',
'inputs': [{'name': 'family', 'type': 'hidden', 'value': 'wikipedia'},
{'name': 'language', 'type': 'hidden', 'value': 'en'},
{'name': 'search', 'type': 'search', 'value': ''},
{'name': 'go', 'type': 'hidden', 'value': 'Go'}],
'method': 'get'}如你所见,如果你尝试使用浏览器进入该页面,你将看到一个简单的 Wikipedia 搜索框,这就是我们在此处只看到一个表单的原因。
还学习: 如何在 Python 中从网页下载所有图像。
提交 Web 表单
Python如何提取和提交Web表单?你还可以注意到,之前提取的大多数输入字段都有hidden类型,我们对此不感兴趣。相反,我们需要填写名称为"search"和类型为"search" 的输入,这实际上是普通用户唯一可见的字段。更一般地说,我们寻找任何没有对用户隐藏的输入字段。
首先,因为它是一个单一的形式,让我们把它变成一个变量:
# get the first form
first_form = get_all_forms(url)[0]让我们再次解析之前看到的所有表单细节:
# extract all form details
form_details = get_form_details(first_form)现在,为了使我们的代码尽可能灵活(我们可以在其中运行任何网站),让我们提示脚本用户我们要在每个非隐藏输入字段上提交的实际值:
# the data body we want to submit
data = {}
for input_tag in form_details["inputs"]:
if input_tag["type"] == "hidden":
# if it's hidden, use the default value
data[input_tag["name"]] = input_tag["value"]
elif input_tag["type"] != "submit":
# all others except submit, prompt the user to set it
value = input(f"Enter the value of the field '{input_tag['name']}' (type: {input_tag['type']}): ")
data[input_tag["name"]] = value所以上面的代码将使用隐藏字段的默认值(例如CSRF token)并提示用户输入其他输入字段(例如搜索、电子邮件、文本等等)。
Python从URL中提取和提交Web表单:让我们看看我们如何根据方法提交它:
# join the url with the action (form request URL)
url = urljoin(url, form_details["action"])
if form_details["method"] == "post":
res = session.post(url, data=data)
elif form_details["method"] == "get":
res = session.get(url, params=data)我只使用GET或POST在这里,但你可以将其扩展到其他 HTTP 方法,例如PUT和DELETE(分别使用session.put()和session.delete()方法)。
好的,现在我们有res包含 HTTP 响应的变量,它应该包含服务器在表单提交后发送的网页,让我们确保它工作,下面的代码准备网页的 HTML 内容以将其保存在我们的本地计算机上:
# the below code is only for replacing relative URLs to absolute ones
soup = BeautifulSoup(res.content, "html.parser")
for link in soup.find_all("link"):
try:
link.attrs["href"] = urljoin(url, link.attrs["href"])
except:
pass
for script in soup.find_all("script"):
try:
script.attrs["src"] = urljoin(url, script.attrs["src"])
except:
pass
for img in soup.find_all("img"):
try:
img.attrs["src"] = urljoin(url, img.attrs["src"])
except:
pass
for a in soup.find_all("a"):
try:
a.attrs["href"] = urljoin(url, a.attrs["href"])
except:
pass
# write the page content to a file
open("page.html", "w").write(str(soup))所有这些都是用绝对 URL(例如https://www.wikipedia.org/wiki/Programming_language)替换相对 URL(例如/ wiki/Programming_language ), 以便我们可以在我们的计算机本地正确浏览页面。我已将所有内容保存到本地文件中"page.html",让我们在浏览器中打开它:
import webbrowser
# open the page on the default browser
webbrowser.open("page.html") 好了,代码完成了,下面是我的执行方式:
{'action': '//www.wikipedia.org/search-redirect.php',
'inputs': [{'name': 'family', 'type': 'hidden', 'value': 'wikipedia'},
{'name': 'language', 'type': 'hidden', 'value': 'en'},
{'name': 'search', 'type': 'search', 'value': ''},
{'name': 'go', 'type': 'hidden', 'value': 'Go'}],
'method': 'get'}
Enter the value of the field 'search' (type: search): python programming language这与在 Web 浏览器中手动填写表单基本相同:
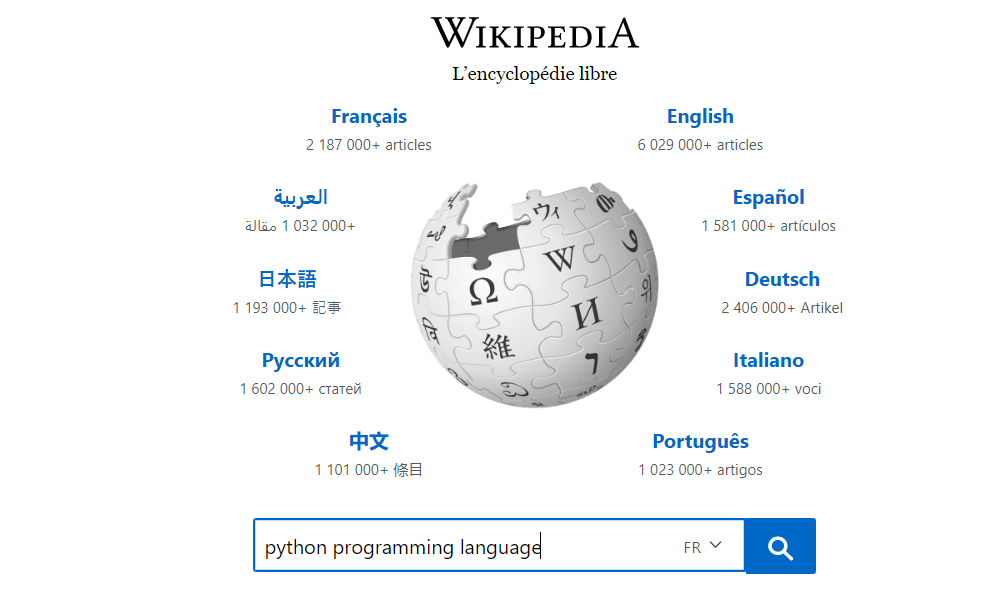
如何使用Python提取和提交Web表单?在我的代码执行中按 Enter 键后,这将提交表单,在本地保存结果页面并在默认 Web 浏览器中自动打开它:
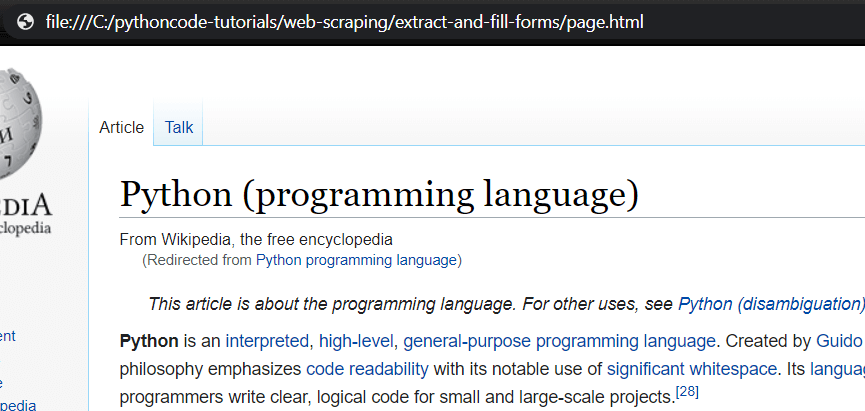
Python是这样看到结果的,所以我们成功自动提交了搜索表单,并在Python的帮助下加载了结果页面!
Python从URL中提取和提交Web表单总结
好吧,就是这样。在本教程中,我们在维基百科上进行了搜索,但如前所述,你可以在任何你想要的表单上使用它,尤其是登录表单,你可以在其中登录并继续提取需要用户身份验证的数据。
Python如何提取和提交Web表单?看看如何扩展它。例如,你可以尝试为所有表单创建一个提交器(因为我们在这里只使用了第一个表单),或者你可以创建一个复杂的爬虫来提取所有网站链接并尝试查找特定网站的所有表单。但是,请记住,如果你在短时间内请求大量页面,网站可能会禁止你的 IP 地址。在这种情况下,你可以减慢你的爬虫速度或使用代理。
此外,你可以通过使用 Selenium 自动登录来扩展此代码,请查看本教程以了解如何执行此操作!

