
Python如何提取所有网站链接?本文教你使用Python中的requests、requests_html和beautiful soup构建一个爬虫来提取所有网站内部和外部链接。
提取网页的所有链接是网络爬虫的常见任务,构建高级爬虫来抓取某个网站的每个页面以提取数据很有用,也可用于 SEO 诊断过程甚至信息收集阶段进行渗透测试人员。在本教程中,你将学习如何仅使用Requests 和 BeautifulSoup库从零开始在 Python 中构建链接提取器工具。
如何在Python中提取所有网站链接?让我们安装依赖项:
pip3 install requests bs4 colorama我们将使用请求作出HTTP请求方便,BeautifulSoup解析HTML和彩色光的改变文字颜色。
Python提取所有网站链接示例代码开始:打开一个新的 Python 文件并继续,让我们导入我们需要的模块:
import requests
from urllib.parse import urlparse, urljoin
from bs4 import BeautifulSoup
import colorama我们将使用colorama只是为了在打印时使用不同的颜色,以区分内部和外部链接:
# init the colorama module
colorama.init()
GREEN = colorama.Fore.GREEN
GRAY = colorama.Fore.LIGHTBLACK_EX
RESET = colorama.Fore.RESET
YELLOW = colorama.Fore.YELLOW我们需要两个全局变量,一个用于网站的所有内部链接,另一个用于所有外部链接:
# initialize the set of links (unique links)
internal_urls = set()
external_urls = set()- 内部链接是链接到同一网站其他页面的 URL。
- 外部链接是链接到其他网站的 URL。
由于并非所有锚标签(a标签)中的链接 都有效(我已经对此进行了试验),有些是指向网站部分的链接,有些是 javascript,所以让我们编写一个函数来验证 URL:
def is_valid(url):
"""
Checks whether `url` is a valid URL.
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)这将确保URL 中存在正确的方案(协议,例如http或https)和域名。
Python如何提取所有网站链接?现在让我们构建一个函数来返回网页的所有有效 URL:
def get_all_website_links(url):
"""
Returns all URLs that is found on `url` in which it belongs to the same website
"""
# all URLs of `url`
urls = set()
# domain name of the URL without the protocol
domain_name = urlparse(url).netloc
soup = BeautifulSoup(requests.get(url).content, "html.parser")首先,我初始化了urls集变量,我在这里使用了 Python 集,因为我们不想要冗余链接。
其次,我已经从 URL 中提取了域名,我们需要它来检查我们抓取的链接是外部链接还是内部链接。
如何在Python中提取所有网站链接?第三,我已经下载了网页的 HTML 内容并用一个soup对象包装它以简化 HTML 解析。
让我们所有的HTML一个标签(锚标签包含网页的所有链接):
for a_tag in soup.findAll("a"):
href = a_tag.attrs.get("href")
if href == "" or href is None:
# href empty tag
continue复制所以我们得到href属性并检查那里是否有东西。否则,我们就继续下一个链接。
由于并非所有链接都是绝对链接,因此我们需要将相对 URL 与其域名连接起来(例如,当href为"/search"且url为"google.com" 时,结果将为"google.com/search"):
# join the URL if it's relative (not absolute link)
href = urljoin(url, href)Python提取所有网站链接示例 - 现在我们需要从 URL 中删除HTTP GET参数,因为这会导致集合中的冗余,下面的代码处理:
parsed_href = urlparse(href)
# remove URL GET parameters, URL fragments, etc.
href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path让我们完成这个功能:
if not is_valid(href):
# not a valid URL
continue
if href in internal_urls:
# already in the set
continue
if domain_name not in href:
# external link
if href not in external_urls:
print(f"{GRAY}[!] External link: {href}{RESET}")
external_urls.add(href)
continue
print(f"{GREEN}[*] Internal link: {href}{RESET}")
urls.add(href)
internal_urls.add(href)
return urlsPython如何提取所有网站链接?我们在这里所做的只是检查:
- 如果 URL 无效,请继续下一个链接。
- 如果 URL 已经在internal_urls 中,我们也不需要它。
- 如果 URL 是外部链接,则将其打印为灰色并将其添加到我们的全局external_urls集中并继续下一个链接。
最后,经过所有检查,该 URL 将是一个内部链接,我们将其打印并添加到我们的urls和internal_urls集合中。
上面的函数只会抓取一个特定页面的链接,如果我们想提取整个网站的所有链接怎么办?我们开工吧:
# number of urls visited so far will be stored here
total_urls_visited = 0
def crawl(url, max_urls=30):
"""
Crawls a web page and extracts all links.
You'll find all links in `external_urls` and `internal_urls` global set variables.
params:
max_urls (int): number of max urls to crawl, default is 30.
"""
global total_urls_visited
total_urls_visited += 1
print(f"{YELLOW}[*] Crawling: {url}{RESET}")
links = get_all_website_links(url)
for link in links:
if total_urls_visited > max_urls:
break
crawl(link, max_urls=max_urls)该函数抓取网站,即获取第一页的所有链接,然后递归调用自身以跟踪之前提取的所有链接。但是,这可能会导致一些问题,该程序将卡在大型网站(有很多链接)上,例如google.com,因此,我添加了一个max_urls参数以在我们检查到一定数量的 URL 时退出.
Python提取所有网站链接示例介绍:好的,让我们测试一下,确保你在你有权访问的网站上使用它,否则我对你造成的任何伤害概不负责。
if __name__ == "__main__":
crawl("https://www.thepythoncode.com")
print("[+] Total Internal links:", len(internal_urls))
print("[+] Total External links:", len(external_urls))
print("[+] Total URLs:", len(external_urls) + len(internal_urls))
print("[+] Total crawled URLs:", max_urls)如何在Python中提取所有网站链接?我正在这个网站上测试。但是,我强烈建议你不要这样做,这会导致大量请求并挤满 Web 服务器,并且可能会阻止你的 IP 地址。
这是输出的一部分:
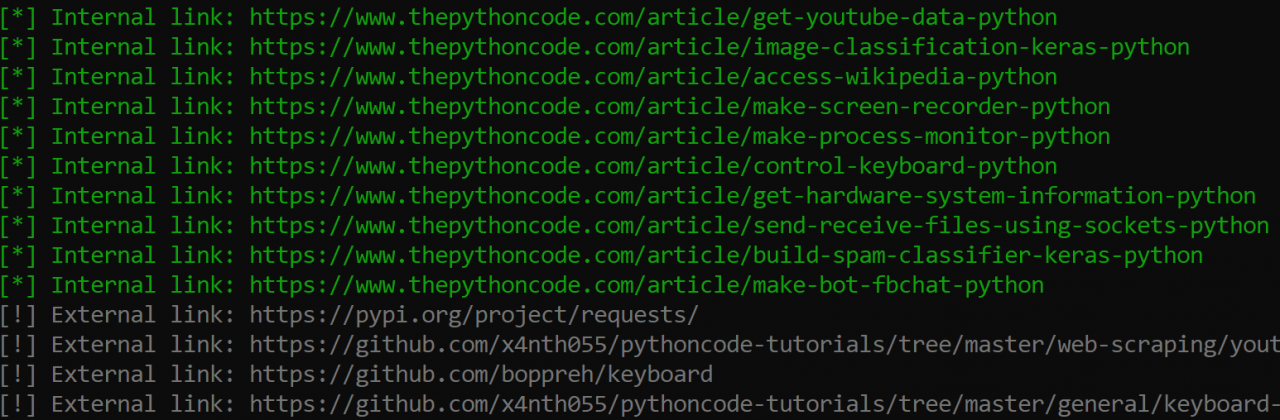
抓取完成后,它将打印提取和抓取的总链接:
[+] Total Internal links: 90
[+] Total External links: 137
[+] Total URLs: 227
[+] Total crawled URLs: 30很棒,对吧?我希望本教程对你有所帮助,以激发你使用 Python 构建此类工具。
Python如何提取所有网站链接?有一些网站使用 JavaScript 加载大部分内容,因此,我们需要使用requests_html库,这使我们能够使用Chromium执行 Javascript ,我已经为此编写了一个脚本,只需添加几行(如requests_html 与requests非常相似),请在此处查看。
短时间内多次请求同一个网站可能会导致该网站屏蔽你的IP地址,在这种情况下,你需要为此使用代理服务器。
如果你对抓取图像感兴趣,请查看本教程:如何使用 Python 从网页下载所有图像,或者如果你想提取 HTML 表格,请查看本教程。
我稍微编辑了代码,因此你将能够将输出 URL 保存在文件中,还可以从命令行参数传递 URL,检查完整代码。
想了解有关网页抓取的更多信息?
最后,如果你想更多地使用不同的 Python 库进行网络抓取,而不仅仅是 BeautifulSoup,以下课程肯定对你很有价值:
- 使用 Scrapy Splash Selenium 使用 Python 进行现代网页抓取。
- Python 2021 中的 Web 抓取和 API 基础知识。

