
使用 Python 中的 Scikit-learn 库构建语音情感识别系统,从人类语音语气中检测情感。
Python Scikit-learn制作语音情感识别器:随着用户体验的改善和语音用户界面 (VUI)的参与,情绪识别的重要性越来越受欢迎。开发基于语音的情感识别系统具有实际应用优势。然而,当系统在实际应用中使用时,这些好处在某种程度上被现实世界的背景噪声削弱了基于语音的情感识别性能。
Python如何制作语音情感识别器?语音情感识别(SER)是语音信号分析领域中最具挑战性的任务之一,它是一个试图从语音信号中推断情感的研究领域问题。
我们可以在哪里使用它?
尽管它不是那么受欢迎,但这些年来 SER 已经进入了很多领域,包括:
- 医疗领域:在通过移动平台对患者进行评估的远程医疗领域,医疗专业人员辨别患者实际感受的能力在康复过程中非常有用。
- 客户服务:在呼叫中心对话可用于分析呼叫服务员与客户的行为研究,这有助于提高服务质量。
- 推荐系统: Ç一个是推荐产品,基于他们对该产品的客户的情绪非常有用。
好了,理论讲完了,让我们开始吧!
相关: 如何在 Python 中使用 TensorFlow 执行语音性别识别。
Python语音情感识别器示例:所需的依赖项
首先,我们需要使用 pip 安装一些依赖项:
pip3 install librosa==0.6.3 numpy soundfile==0.9.0 sklearn pyaudio==0.2.11让我们导入它们:
import soundfile # to read audio file
import numpy as np
import librosa # to extract speech features
import glob
import os
import pickle # to save model after training
from sklearn.model_selection import train_test_split # for splitting training and testing
from sklearn.neural_network import MLPClassifier # multi-layer perceptron model
from sklearn.metrics import accuracy_score # to measure how good we are整个管道如下(与任何机器学习管道相同):
- 准备数据集:在这里,我们下载并转换数据集以适合提取。
- 加载数据集:这个过程是关于在 Python 中加载数据集,它涉及提取音频特征,例如从语音信号中获取不同的特征,如功率、音高和声道配置,我们将使用 librosa 库来完成。
- 训练模型:在我们准备并加载数据集后,我们只需在合适的sklearn模型上训练它。
- 测试模型:衡量我们的模型做得有多好。
首先,我们需要一个数据集来训练,幸运的是有RAVDESS 数据集,我已经下载并成功提取了它。之后我们需要降低所有音频文件的采样率,这样librosa会很高兴,我已经制作了一个脚本来这样做,如果你一步一步地跟随,你实际上不需要那个,因为我已经准备好了数据集(在此处下载)。
注意:如果你想按照建议将自己的音频样本转换为 16000Hz 采样率和单声道,则需要在你的机器上安装此 python 脚本和FFmpeg。
Python如何制作语音情感识别器?让我们创建处理提取特征的函数(以相对较低的数据速率将语音波形更改为参数表示形式):
def extract_feature(file_name, **kwargs):
"""
Extract feature from audio file `file_name`
Features supported:
- MFCC (mfcc)
- Chroma (chroma)
- MEL Spectrogram Frequency (mel)
- Contrast (contrast)
- Tonnetz (tonnetz)
e.g:
`features = extract_feature(path, mel=True, mfcc=True)`
"""
mfcc = kwargs.get("mfcc")
chroma = kwargs.get("chroma")
mel = kwargs.get("mel")
contrast = kwargs.get("contrast")
tonnetz = kwargs.get("tonnetz")
with soundfile.SoundFile(file_name) as sound_file:
X = sound_file.read(dtype="float32")
sample_rate = sound_file.samplerate
if chroma or contrast:
stft = np.abs(librosa.stft(X))
result = np.array([])
if mfcc:
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T, axis=0)
result = np.hstack((result, mfccs))
if chroma:
chroma = np.mean(librosa.feature.chroma_stft(S=stft, sr=sample_rate).T,axis=0)
result = np.hstack((result, chroma))
if mel:
mel = np.mean(librosa.feature.melspectrogram(X, sr=sample_rate).T,axis=0)
result = np.hstack((result, mel))
if contrast:
contrast = np.mean(librosa.feature.spectral_contrast(S=stft, sr=sample_rate).T,axis=0)
result = np.hstack((result, contrast))
if tonnetz:
tonnetz = np.mean(librosa.feature.tonnetz(y=librosa.effects.harmonic(X), sr=sample_rate).T,axis=0)
result = np.hstack((result, tonnetz))
return result我们将使用MFCC、Chroma和Mel 频率倒频谱作为语音特征,而不是原始波形,原始波形可能包含对分类没有帮助的不必要信息。
让我们编写函数来加载我们拥有的数据:
# all emotions on RAVDESS dataset
int2emotion = {
"01": "neutral",
"02": "calm",
"03": "happy",
"04": "sad",
"05": "angry",
"06": "fearful",
"07": "disgust",
"08": "surprised"
}
# we allow only these emotions ( feel free to tune this on your need )
AVAILABLE_EMOTIONS = {
"angry",
"sad",
"neutral",
"happy"
}
def load_data(test_size=0.2):
X, y = [], []
for file in glob.glob("data/Actor_*/*.wav"):
# get the base name of the audio file
basename = os.path.basename(file)
# get the emotion label
emotion = int2emotion[basename.split("-")[2]]
# we allow only AVAILABLE_EMOTIONS we set
if emotion not in AVAILABLE_EMOTIONS:
continue
# extract speech features
features = extract_feature(file, mfcc=True, chroma=True, mel=True)
# add to data
X.append(features)
y.append(emotion)
# split the data to training and testing and return it
return train_test_split(np.array(X), y, test_size=test_size, random_state=7)注意:同一目录下需要有一个名为“data”的文件夹(点此下载),否则无法运行。
Python Scikit-learn制作语音情感识别器:int2emotion字典包含此数据集上的可用情绪,而AVAILABLE_EMOTIONS是我们要分类的情绪,随意添加/删除你想要的任何情绪。
让我们实际加载它:
# load RAVDESS dataset, 75% training 25% testing
X_train, X_test, y_train, y_test = load_data(test_size=0.25)记录有关数据集的一些信息:
# print some details
# number of samples in training data
print("[+] Number of training samples:", X_train.shape[0])
# number of samples in testing data
print("[+] Number of testing samples:", X_test.shape[0])
# number of features used
# this is a vector of features extracted
# using extract_features() function
print("[+] Number of features:", X_train.shape[1])Python语音情感识别器示例:复制在我对 MLPClassifier执行网格搜索以获得可能的最佳超参数后,我想出了这些参数(到目前为止),让我们直接使用它们:
# best model, determined by a grid search
model_params = {
'alpha': 0.01,
'batch_size': 256,
'epsilon': 1e-08,
'hidden_layer_sizes': (300,),
'learning_rate': 'adaptive',
'max_iter': 500,
}因此,这基本上是一个全连接(密集)神经网络,其中一层包含 300 个单元、256 个批次大小、500 次迭代和自适应学习率(这不是最佳超参数,因此可以随意调整)。
现在让我们用这些参数初始化模型:
# initialize Multi Layer Perceptron classifier
# with best parameters ( so far )
model = MLPClassifier(**model_params)我们现在需要使用刚刚加载的数据集来训练模型:
# train the model
print("[*] Training the model...")
model.fit(X_train, y_train)完成需要几秒钟,然后我们需要计算准确度分数并打印它以衡量我们有多好:
# predict 25% of data to measure how good we are
y_pred = model.predict(X_test)
# calculate the accuracy
accuracy = accuracy_score(y_true=y_test, y_pred=y_pred)
print("Accuracy: {:.2f}%".format(accuracy*100))保存模型:
# now we save the model
# make result directory if doesn't exist yet
if not os.path.isdir("result"):
os.mkdir("result")
pickle.dump(model, open("result/mlp_classifier.model", "wb"))Python Scikit-learn制作语音情感识别器 - 这是我的输出结果的屏幕截图:
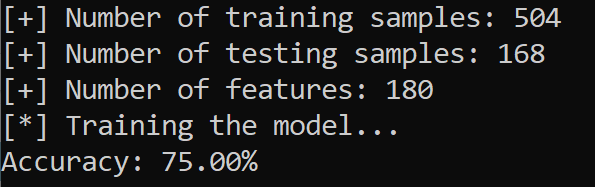
Python如何制作语音情感识别器?我们仅使用少量训练样本就在 4 种情绪上获得了 75% 的准确率,可以随意使用和合并其他数据集,例如Emo-DB和TESS,并根据你希望获得更好的性能调整模型(或使用其他模型)。
如果你想在你保存的模型上测试你的语音调谐,请前往此文件。
此处显示的所有代码都在此 GitHub 存储库中。

