
在本教程中,你将全面介绍 Python k-最近邻算法 (kNN算法) 。kNN 算法是最著名的机器学习算法之一,绝对是你机器学习工具箱中的必备品。Python 是机器学习的首选编程语言,所以有什么比 Python 著名的软件包NumPy和scikit-learn更好的发现 kNN 的方法了!
如何理解k-最近邻算法?下面,你将在理论和实践中探索 kNN 算法以及kNN工作原理。虽然许多教程跳过了理论部分,只关注库的使用,但你不希望依赖自动化包来进行机器学习。了解机器学习算法的机制以了解它们的潜力和局限性非常重要。
同时,了解如何在实践中使用算法也很重要。考虑到这一点,在本教程的第二部分,你将重点介绍 kNN 在 Python 库 scikit-learn 中的使用,以及将性能提升到最大的高级技巧。
在本教程中,你将学习如何:
- 直观地和数学地解释kNN 算法
- Python如何实现k-最近邻算法?
- 使用NumPy从头开始在 Python 中实现 kNN
- 通过scikit-learn在 Python 中使用 kNN
- 使用以下方法调整kNN 的超参数
GridSearchCV - 添加装袋到k近邻有更好的表现
免费奖励: 单击此处获取免费的 NumPy 资源指南,该指南为你提供了用于提高 NumPy 技能的最佳教程、视频和书籍。
机器学习基础
为了让你参与进来,有必要退后一步,对机器学习进行总体快速调查。在本节中,你将了解机器学习背后的基本思想,并了解 kNN 算法与其他机器学习工具的关系。
kNN工作原理:机器学习的一般思想是获得一个模型,从任何主题的历史数据中学习趋势,并能够在未来在可比数据上重现这些趋势。这是一个概述基本机器学习过程的图表:
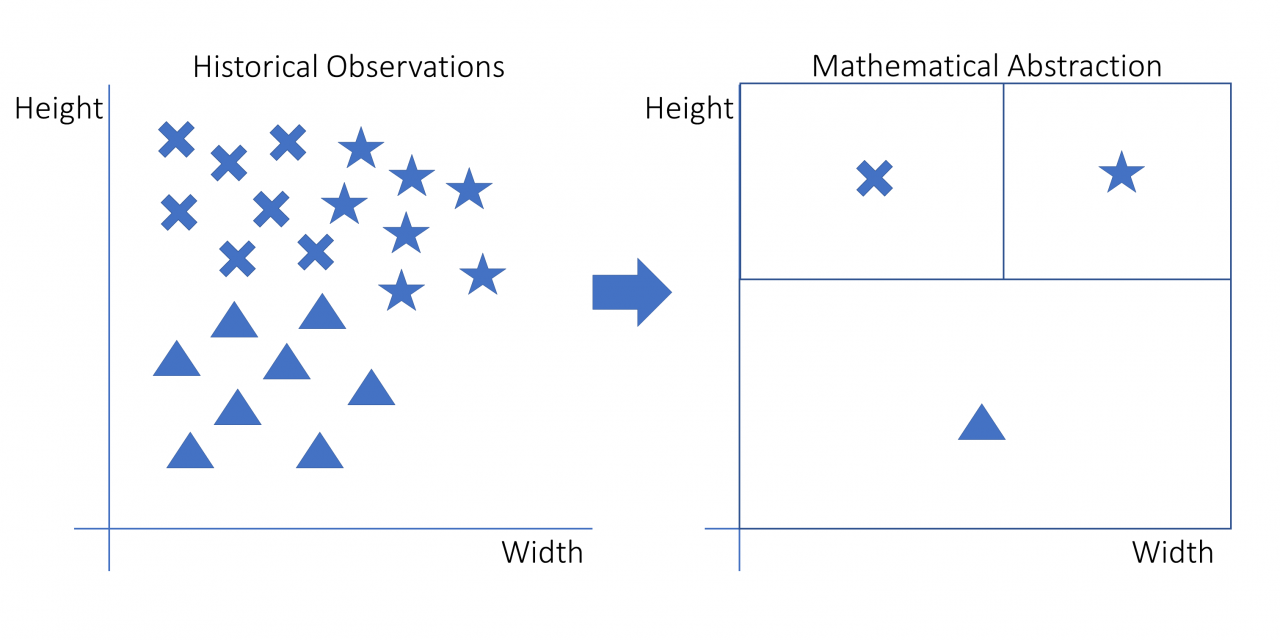
该图是拟合历史数据的机器学习模型的直观表示。左侧是具有三个变量的原始观测值:高度、宽度和形状。形状是星形、十字形和三角形。
这些形状位于图形的不同区域。在右侧,你会看到这些原始观察结果是如何转化为决策规则的。对于新的观察,你需要知道宽度和高度以确定它落在哪个正方形。反过来,它落入的正方形定义了它最有可能具有的形状。
许多不同的模型可用于此任务。甲模型是可以用来描述数据点的数学公式。一个例子是线性模型,它使用由公式定义的线性函数y = ax + b。
如果你估计或拟合模型,你可以使用某种算法找到固定参数的最佳值。在线性模型中,参数是a和b。幸运的是,你不必发明这样的估计算法即可开始。它们已经被伟大的数学家发现了。
一旦模型被估计出来,它就会变成一个数学公式,你可以在其中填写自变量的值以对目标变量进行预测。从高层的角度来看,就是这样!
kNN的区别特征
现在你了解了机器学习背后的基本思想,下一步是了解为什么有这么多模型可用。你刚刚看到的线性模型称为线性回归。
线性回归在某些情况下有效,但并不总是能做出非常精确的预测。这就是为什么数学家想出了许多你可以使用的替代机器学习模型。k-最近邻算法就是其中之一。
所有这些模型都有其特点。如果你从事机器学习,你应该对所有这些都有深刻的理解,这样你才能在正确的情况下使用正确的模型。要了解为什么以及何时使用 kNN,你接下来将了解 kNN 与其他机器学习模型的比较。
kNN 是一种有监督的机器学习算法
的机器学习算法的第一确定属性是之间的分裂监督和无监督模式。监督模型和无监督模型之间的区别在于问题陈述。
在监督模型中,你同时拥有两种类型的变量:
- 甲目标变量,其也被称为从属变量或
y变量。 - 自变量,也称为
x变量或解释变量。
目标变量是你要预测的变量。这取决于自变量,它不是你提前知道的。自变量是你提前知道的变量。你可以将它们代入方程以预测目标变量。这样一来,就比较像y = ax + bcase了。
在你之前看到的图表和本节的以下图表中,目标变量是数据点的形状,自变量是高度和宽度。你可以在下图中看到监督学习背后的想法:
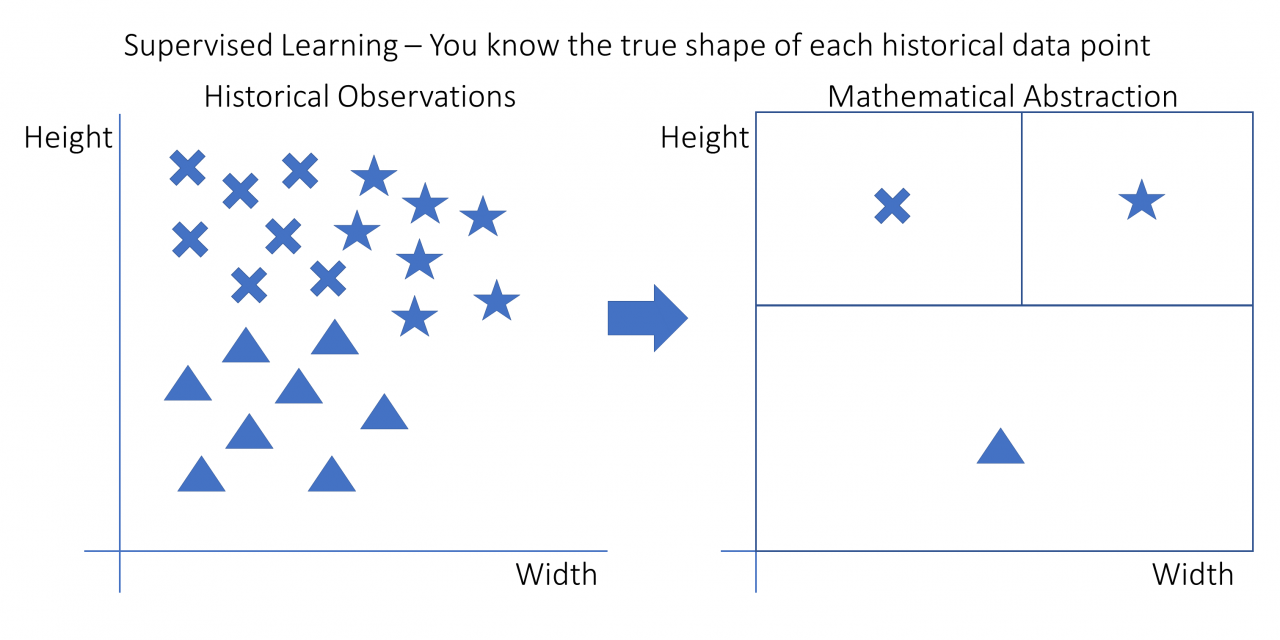
Python k-最近邻算法:在这个图中,每个数据点都有一个高度、一个宽度和一个形状。有十字形、星形和三角形。右边是机器学习模型可能已经学到的决策规则。
在这种情况下,用十字标记的观测值高但不宽。星星又高又宽。三角形很短,但可以宽也可以窄。从本质上讲,该模型已经学习了一个决策规则,仅根据其高度和宽度来确定观察结果是否更有可能是十字形、星形或三角形。
Python如何实现k-最近邻算法?在无监督模型中,目标变量和自变量之间没有分裂。无监督学习试图通过评估数据点的相似性来对数据点进行分组。
正如你在示例中看到的那样,你永远无法确定分组的数据点从根本上属于一起,但只要分组有意义,它在实践中就非常有价值。你可以在下图中看到无监督学习背后的想法:
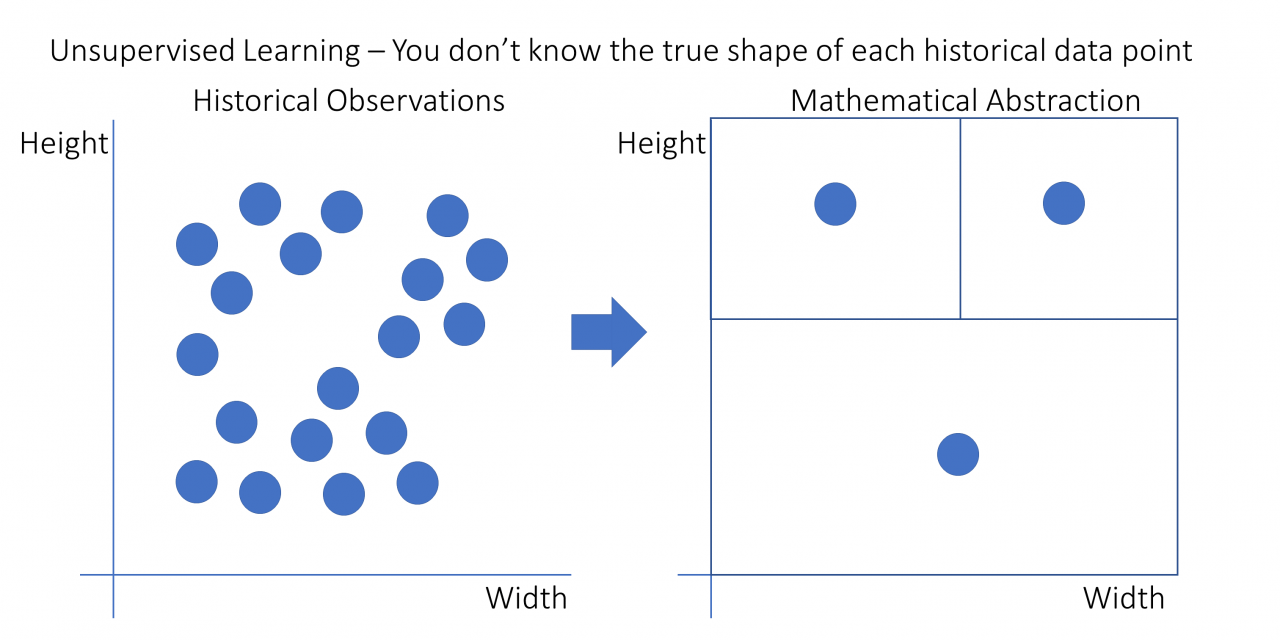
在此图中,观测值不再具有不同的形状。他们都是圈子。然而,它们仍然可以根据点之间的距离分为三组。在这个特定的例子中,有三组点可以根据它们之间的空白空间分开。
kNN 算法是一种有监督的机器学习模型。这意味着它使用一个或多个自变量来预测目标变量。
要了解有关无监督机器学习模型的更多信息,请查看Python 中的 K-Means 聚类:实用指南。
kNN工作原理:kNN 是一种非线性学习算法
在机器学习算法中产生巨大差异的第二个属性是模型是否可以估计非线性关系。
线性模型是使用线或超平面进行预测的模型。在图像中,模型被描绘为在点之间绘制的线。该模型y = ax + b是线性模型的经典示例。你可以在以下示意图中看到线性模型如何拟合示例数据:
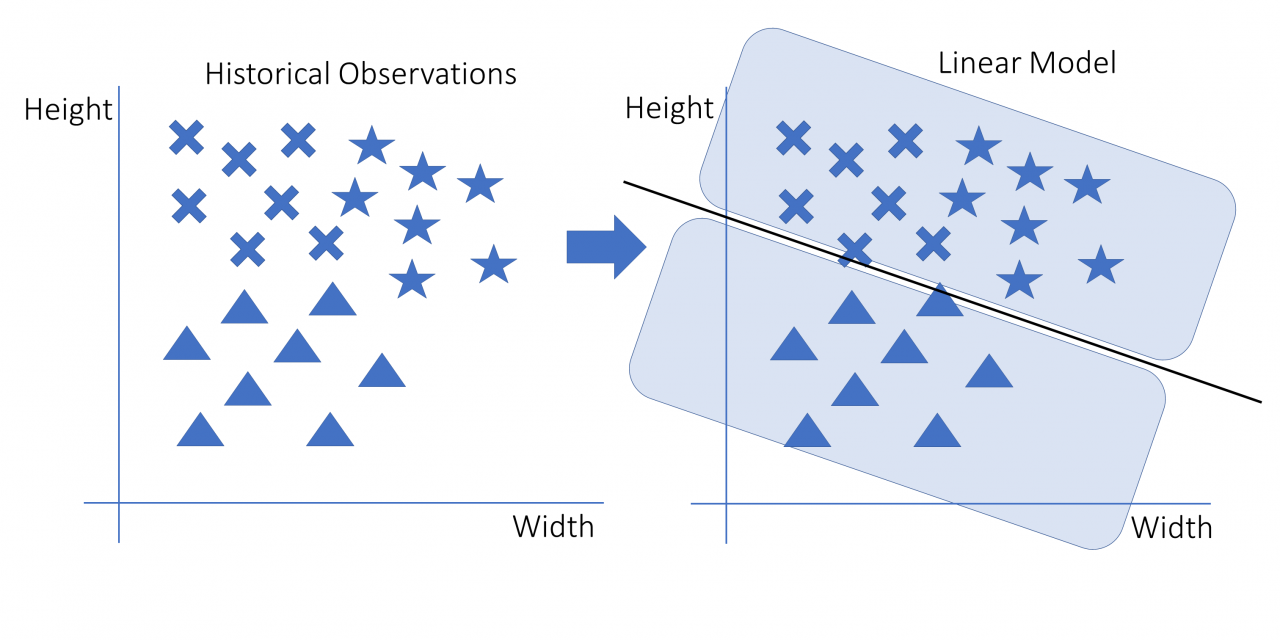
在这张图片中,数据点在左侧用星形、三角形和十字形表示。右边是一个线性模型,可以将三角形与非三角形分开。决定是一条线。线上方的每个点都是非三角形,线下方的所有点都是三角形。
如果你想向之前的图形添加另一个自变量,你需要将其绘制为一个附加维度,从而创建一个包含其中形状的立方体。然而,一条线无法将一个立方体切成两部分。线的多维对应物是超平面。因此,线性模型由超平面表示,在二维空间的情况下,它恰好是一条线。
非线性模型是使用除线以外的任何方法来分离案例的模型。一个众所周知的例子是决策树,它基本上是一长串 if ... else 语句。在非线性图中,if ... else 语句将允许你绘制正方形或你想绘制的任何其他形式。下图描述了应用于示例数据的非线性模型:
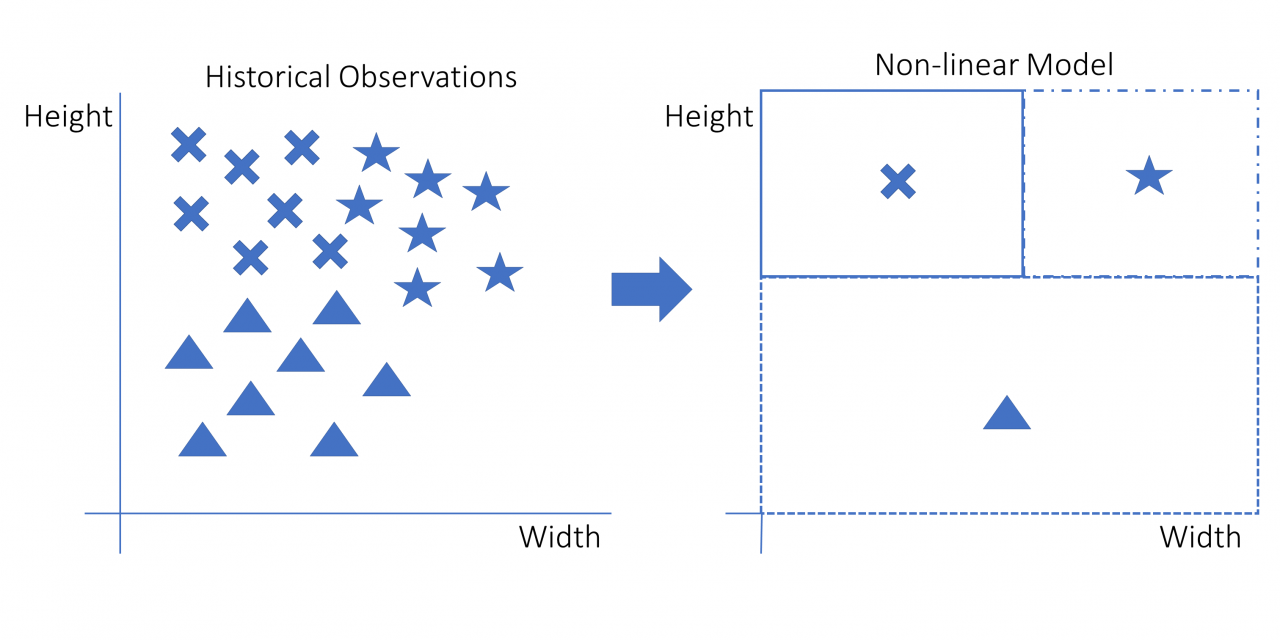
该图显示了决策如何是非线性的。决策规则由三个方格组成。新数据点所在的框将定义其预测形状。请注意,不可能使用一条线立即拟合它:需要两条线。这个模型可以用 if ... else 语句重新创建,如下所示:
- 如果数据点的高度很低,那么它就是一个三角形。
- 否则,如果数据点的宽度很低,那么它就是一个十字。
- 否则,如果以上都不是真的,那么它就是一颗星星。
kNN 是非线性模型的一个例子。在本教程的后面,你将回到计算模型的确切方式。
kNN 是分类和回归的监督学习器
如何理解k-最近邻算法?监督机器学习算法可以根据它们可以预测的目标变量的类型分为两组:
- 分类是具有分类目标变量的预测任务。分类模型学习如何对任何新观察进行分类。这个指定的类可以是对的也可以是错的,不能介于两者之间。分类的一个经典示例是iris dataset,你可以在其中使用植物的物理测量来预测它们的种类。一种可用于分类的著名算法是逻辑回归。
- 回归是一个预测任务,其中目标变量是numeric。一个著名的回归例子是Kaggle 上的住房价格挑战赛。在这场机器学习竞赛中,参赛者试图根据众多自变量来预测房屋的销售价格。
在下图中,你可以使用前面的示例了解回归和分类的样子:
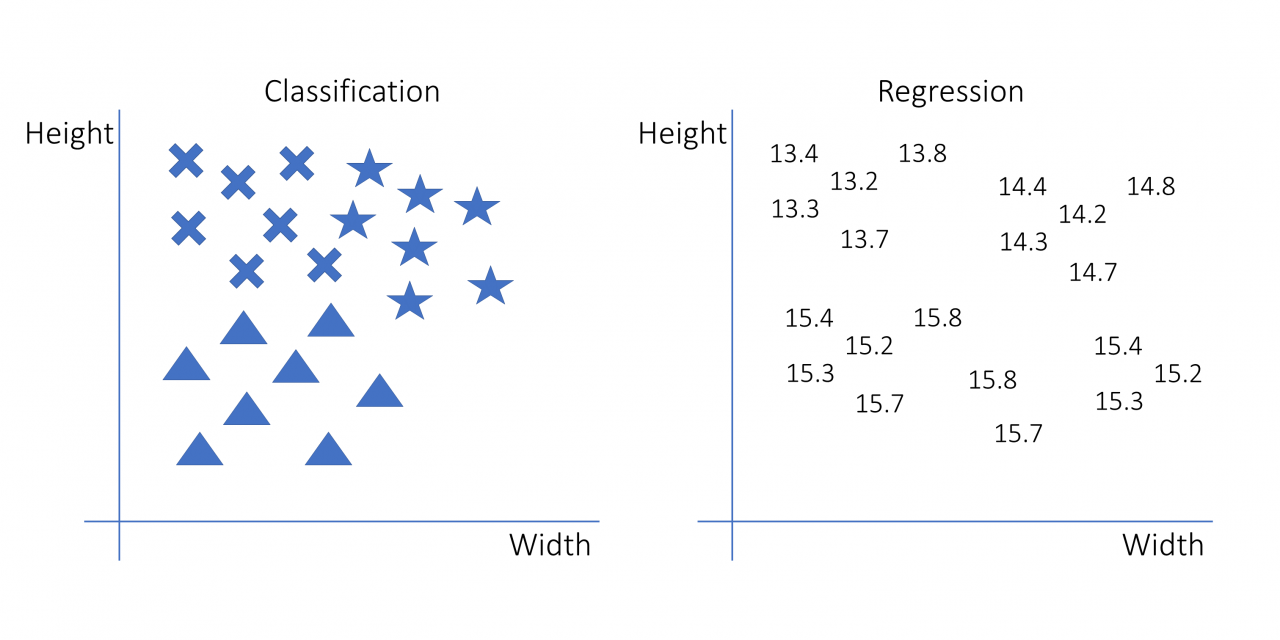
此图像的左侧部分是分类。目标变量是观察的形状,它是一个分类变量。正确的部分是回归。目标变量是数字。这两个示例的决策规则可能完全相同,但它们的解释不同。
对于单个预测,分类有对有错,而回归在连续尺度上有误差。使用数字误差度量更实用,因此许多分类模型不仅可以预测类别,还可以预测属于任一类别的概率。
有的模型只能做回归,有的只能做分类,有的两者都可以。kNN 算法无缝适应分类和回归。你将在本教程的下一部分中准确了解它的工作原理。
kNN 快速且可解释
作为表征机器学习模型的最终标准,你需要考虑模型复杂度。机器学习,尤其是人工智能,目前正在蓬勃发展,并被用于许多复杂的任务,例如理解文本、图像和语音,或用于自动驾驶汽车。
神经网络等更高级和复杂的模型可能可以学习 k-最近邻模型可以学习的任何东西。毕竟,那些高级模型是非常强大的学习者。但是,请注意,这种复杂性也有其代价。为了使模型符合你的预测,你通常会在开发上花费更多时间。
你还需要更多的数据来拟合更复杂的模型,而数据并不总是可用的。最后但并非最不重要的是,更复杂的模型对我们人类来说更难以解释,有时这种解释可能非常有价值。
这就是 kNN 模型的力量所在。它允许用户理解和解释模型内部发生的事情,并且开发速度非常快。这使得 kNN 成为许多不需要高度复杂技术的机器学习用例的绝佳模型。
Python k-最近邻算法的缺点
坦率地说 kNN 算法的缺点也是公平的。如前所述,kNN 的真正缺点是它能够适应自变量和因变量之间高度复杂的关系。kNN 不太可能在计算机视觉和自然语言处理等高级任务上表现良好。
你可以尝试尽可能地提高 kNN 的性能,可能是通过添加机器学习中的其他技术。在本教程的最后一部分,你将了解一种称为bagging的技术,这是一种提高预测性能的方法。但是,在某个复杂点上,kNN 可能会不如其他模型有效,无论其调整方式如何。
使用 kNN 预测海蛞蝓的年龄
为了继续编码部分,你将查看本教程其余部分的示例数据集 - 鲍鱼数据集。该数据集包含大量鲍鱼的年龄测量值。仅供参考,这是鲍鱼的样子:

鲍鱼是一种看起来有点像贻贝的小海螺。如果你想了解更多关于它们的信息,你可以查看鲍鱼维基百科页面以获取更多信息。
鲍鱼问题陈述
鲍鱼的年龄可以通过切开鲍鱼的外壳并计算外壳上的环数来确定。在鲍鱼数据集中,你可以找到大量鲍鱼的年龄测量值以及许多其他物理测量值。
该项目的目标是开发一个模型,该模型可以纯粹基于其他物理测量来预测鲍鱼的年龄。这将使研究人员能够估计鲍鱼的年龄,而无需切开鲍鱼的外壳并计算环数。
你将应用 kNN 来找到可能的最接近的预测分数。
导入鲍鱼数据集
在本教程中,你将使用鲍鱼数据集。你可以下载它并使用pandas将数据导入Python,但让pandas 直接为你导入数据会更快。
要遵循本教程中的代码,建议使用Anaconda安装 Python 。Anaconda 发行版带有许多重要的数据科学包。有关设置环境的更多帮助,你可以查看在 Windows 上设置 Python 进行机器学习。
你可以使用 Pandas 导入数据,如下所示:>>>
>>> import pandas as pd
>>> url = (
... "https://archive.ics.uci.edu/ml/machine-learning-databases"
... "/abalone/abalone.data"
... )
>>> abalone = pd.read_csv(url, header=None)
在此代码中,你首先导入pandas,然后使用它读取数据。你将路径指定为 URL,以便直接通过 Internet 获取文件。
为确保你已正确导入数据,你可以按如下方式进行快速检查:>>>
>>> abalone.head()
0 1 2 3 4 5 6 7 8
0 M 0.455 0.365 0.095 0.5140 0.2245 0.1010 0.150 15
1 M 0.350 0.265 0.090 0.2255 0.0995 0.0485 0.070 7
2 F 0.530 0.420 0.135 0.6770 0.2565 0.1415 0.210 9
3 M 0.440 0.365 0.125 0.5160 0.2155 0.1140 0.155 10
4 I 0.330 0.255 0.080 0.2050 0.0895 0.0395 0.055 7
这应该会显示鲍鱼数据集的前五行,在 Python 中作为 pandas DataFrame 导入。你可以看到列名仍然缺失。你可以abalone.names在 UCI 机器学习存储库的文件中找到这些名称。你可以将它们添加到你DataFrame的如下:>>>
>>> abalone.columns = [
... "Sex",
... "Length",
... "Diameter",
... "Height",
... "Whole weight",
... "Shucked weight",
... "Viscera weight",
... "Shell weight",
... "Rings",
... ]
导入的数据现在应该更容易理解了。但是你还应该做另一件事:你应该删除该Sex列。当前练习的目标是使用物理测量来预测鲍鱼的年龄。由于性别不是纯粹的物理测量,你应该将其从数据集中删除。你可以Sex使用.drop以下方法删除该列:>>>
>>> abalone = abalone.drop("Sex", axis=1)
使用此代码,你可以删除该Sex列,因为它在建模中没有附加值。
鲍鱼数据集的描述性统计
在进行机器学习时,你需要了解正在处理的数据。在不深入的情况下,这里是一些探索性统计数据和图表。
本练习的目标变量是Rings,因此你可以从它开始。一个柱状图会给你一个快速的和有用的概述的年龄范围,你可以期望:>>>
>>> import matplotlib.pyplot as plt
>>> abalone["Rings"].hist(bins=15)
>>> plt.show()
此代码使用Pandas 绘图功能生成包含 15 个 bin 的直方图。使用 15 个 bin 的决定是基于一些试验。在定义 bin 数量时,你通常尽量避免每个 bin 的观测值过多或过少。bin 太少会隐藏某些模式,而 bin 太多会使直方图缺乏平滑度。你可以在下图中看到直方图:
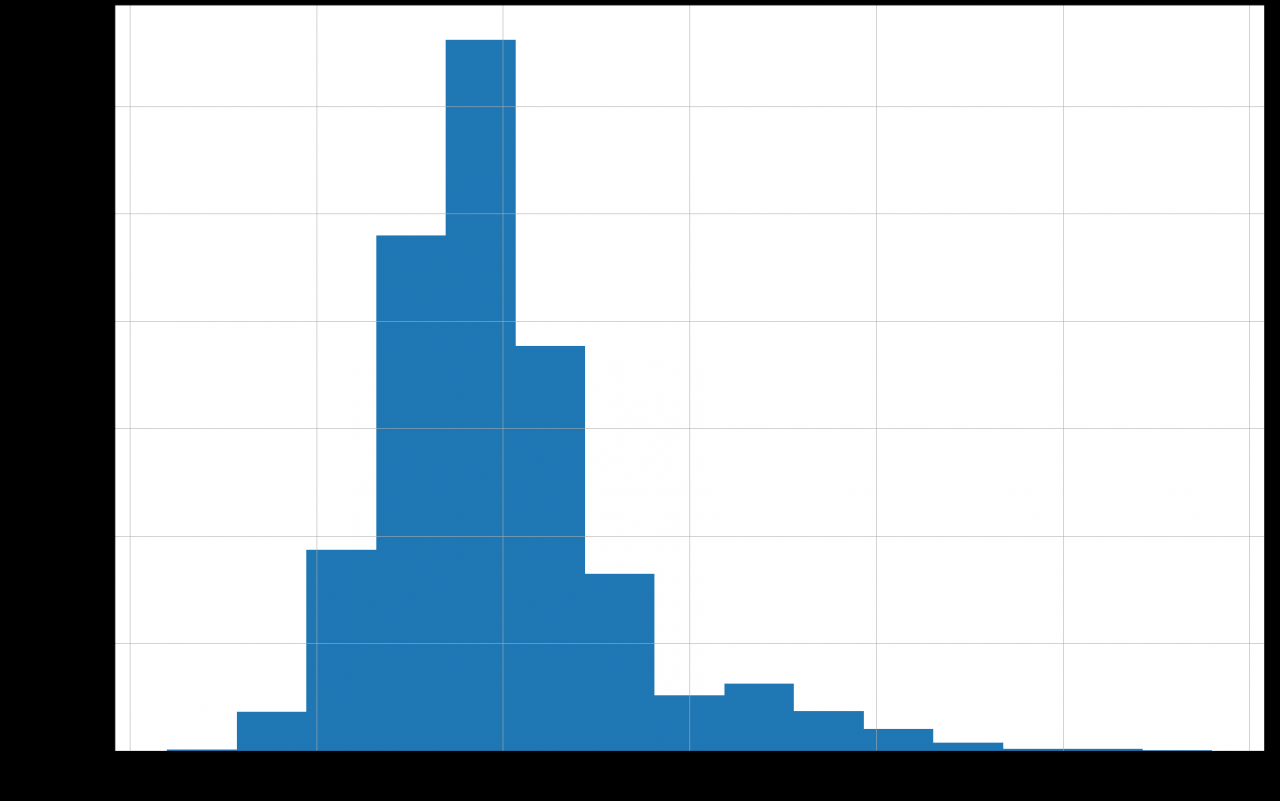
Python如何实现k-最近邻算法?直方图显示数据集中的大多数鲍鱼有 5 到 15 个环,但也有可能达到 25 个环。较老的鲍鱼在该数据集中的代表性不足。这似乎很直观,因为由于自然过程,年龄分布通常会像这样倾斜。
第二个相关探索是找出哪些变量(如果有)与年龄有很强的相关性。自变量与你的目标变量之间的强相关性将是一个好兆头,因为这将确认身体测量值和年龄相关。
你可以在 中观察完整的相关矩阵correlation_matrix。最重要的相关性是与目标变量的相关性Rings。你可以像这样获得这些相关性:>>>
>>> correlation_matrix = abalone.corr()
>>> correlation_matrix["Rings"]
Length 0.556720
Diameter 0.574660
Height 0.557467
Whole weight 0.540390
Shucked weight 0.420884
Viscera weight 0.503819
Shell weight 0.627574
Rings 1.000000
Name: Rings, dtype: float64
现在看看Rings与其他变量的相关系数。它们越接近1,相关性就越大。
你可以得出结论,成年鲍鱼的物理测量值与其年龄之间至少存在一些相关性,但也不是很高。非常高的相关性意味着你可以期待一个简单的建模过程。在这种情况下,你必须尝试看看使用 kNN 算法可以获得什么结果。
使用 Pandas 进行数据探索有更多的可能性。要了解有关使用熊猫进行数据探索的更多信息,请查看使用熊猫和 Python 探索你的数据集。
Python 中从零开始的分步 kNN
在本教程的这一部分中,你将深入了解 kNN 算法的工作原理。该算法有两个你需要了解的主要数学组成部分。为了热身,你将从 kNN 算法的简单英语演练开始。
kNN 算法的简单英语演练
kNN工作原理:与其他机器学习算法相比,kNN 算法有点不典型。正如你之前看到的,每个机器学习模型都有需要估计的特定公式。k-Nearest Neighbors 算法的特殊性在于,这个公式不是在拟合的时候计算的,而是在预测的时候计算的。大多数其他型号并非如此。
当一个新数据点到达时,kNN 算法,顾名思义,将首先找到这个新数据点的最近邻居。然后它采用这些邻居的值并将它们用作新数据点的预测。
作为一个直观的例子,想想你的邻居。你的邻居通常与你比较相似。他们可能和你属于同一个社会经济阶层。也许他们的工作和你一样,也许他们的孩子和你上同一所学校,等等。但是对于某些任务,这种方法并不那么有用。例如,通过查看邻居最喜欢的颜色来预测你的颜色是没有任何意义的。
kNN 算法基于这样一个概念,即你可以根据相邻数据点的特征来预测数据点的特征。在某些情况下,这种预测方法可能会成功,而在其他情况下可能不会。接下来,你将了解数据点“最近”的数学描述以及将多个邻居组合成一个预测的方法。
使用距离的数学定义来定义“最近”
如何理解k-最近邻算法?要找到最接近你需要预测的点的数据点,你可以使用称为欧几里德距离的距离的数学定义。
要获得这个定义,你应该首先了解两个向量的差值是什么意思。下面是一个例子:
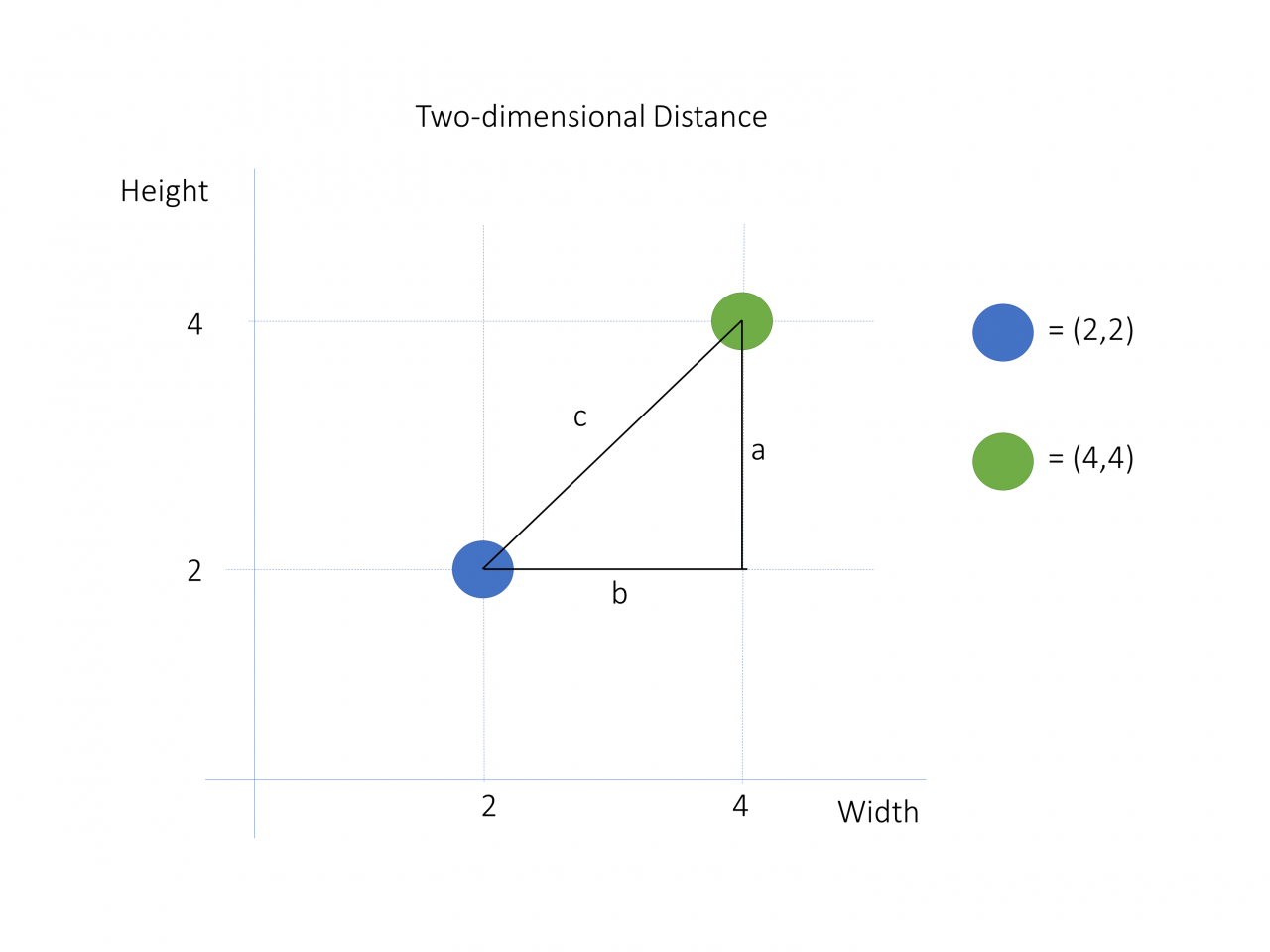
在这张图片中,你会看到两个数据点:(2,2) 处的蓝色和 (4,4) 处的绿色。要计算它们之间的距离,你可以从添加两个向量开始。向量a从点 (4,2) 到点 (4,4),向量b从点 (4,2) 到点 (2,2)。他们的头由彩色点表示。请注意,它们呈 90 度角。
这些向量之间的区别是从 vectorc的头部到 vectora的头部的 vector b。矢量的长度c表示两个数据点之间的距离。
向量的长度称为范数。范数是一个正值,表示向量的大小。你可以使用欧几里得公式计算向量的范数:
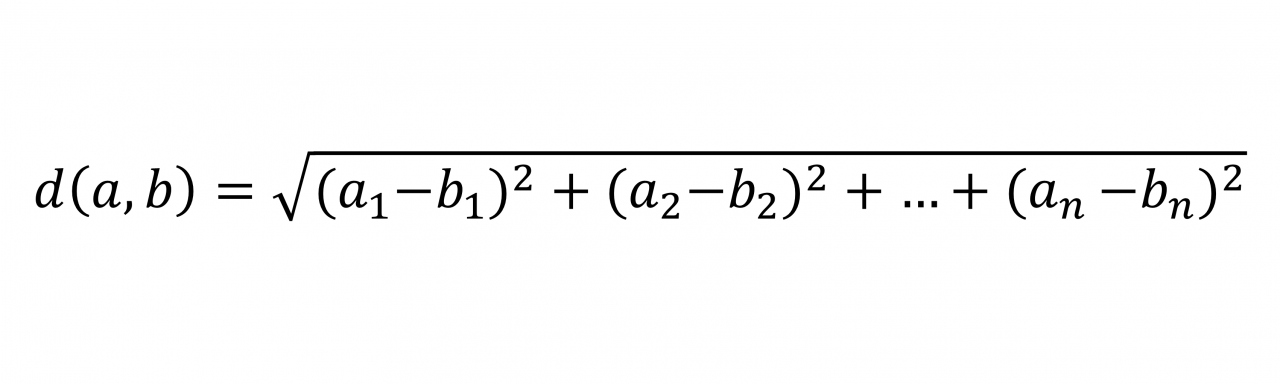
在这个公式中,距离的计算方法是求每个维度的平方差,然后求这些值之和的平方根。在这种情况下,你应该计算差分向量的范数c以获得数据点之间的距离。
现在,要将其应用于你的数据,你必须了解你的数据点实际上是向量。然后,你可以通过计算差异向量的范数来计算它们之间的距离。
你可以使用linalg.norm()NumPy在 Python 中进行计算。下面是一个例子:>>>
>>> import numpy as np
>>> a = np.array([2, 2])
>>> b = np.array([4, 4])
>>> np.linalg.norm(a - b)
2.8284271247461903
在此代码块中,你将数据点定义为向量。然后计算norm()两个数据点之间的差异。这样,你可以直接获得两个多维点之间的距离。即使这些点是多维的,它们之间的距离仍然是一个标量,或者一个单一的值。
如果你想获得有关数学的更多详细信息,可以查看勾股定理以了解欧几里得距离公式是如何推导出来的。
Python k-最近邻算法:寻找k最近的邻居
既然你有一种方法可以计算从任何点到任何点的距离,你可以使用它来查找要对其进行预测的点的最近邻点。
你需要找到许多邻居,该数量由 给出k。的最小值k为1。这意味着仅使用一个邻居进行预测。最大值是你拥有的数据点数。这意味着使用所有邻居。的值k是用户定义的。正如你将在本教程的最后一部分中看到的那样,优化工具可以帮助你解决这个问题。
现在,要在 NumPy 中找到最近的邻居,请返回鲍鱼数据集。如你所见,你需要定义自变量向量的距离,因此你应该首先使用以下.values属性将你的 Pandas DataFrame 放入一个 NumPy 数组中:>>>
>>> X = abalone.drop("Rings", axis=1)
>>> X = X.values
>>> y = abalone["Rings"]
>>> y = y.values
此代码块生成两个现在包含你的数据的对象:X和y. X是自变量,y是模型的因变量。请注意,你使用大写字母表示,X但使用小写字母表示y。这通常在机器学习代码中完成,因为数学符号通常对矩阵使用大写字母,对向量使用小写字母。
现在,你可以k在具有以下物理测量值的新鲍鱼上应用= 3的 kNN :
| 多变的 | 价值 |
|---|---|
| 长度 | 0.569552 |
| 直径 | 0.446407 |
| 高度 | 0.154437 |
| 整体重量 | 1.016849 |
| 去壳重量 | 0.439051 |
| 内脏重量 | 0.222526 |
| 外壳重量 | 0.291208 |
你可以为该数据点创建 NumPy 数组,如下所示:>>>
>>> new_data_point = np.array([
... 0.569552,
... 0.446407,
... 0.154437,
... 1.016849,
... 0.439051,
... 0.222526,
... 0.291208,
... ])
下一步是使用以下代码计算这个新数据点与鲍鱼数据集中每个数据点之间的距离:>>>
>>> distances = np.linalg.norm(X - new_data_point, axis=1)
你现在有一个距离向量,你需要找出三个最近的邻居。为此,你需要找到最小距离的 ID。你可以使用称为.argsort()从低到高对数组进行排序的方法,并可以取第一个k元素来获取k最近邻居的索引:>>>
>>> k = 3
>>> nearest_neighbor_ids = distances.argsort()[:k]
>>> nearest_neighbor_ids
array([4045, 1902, 1644], dtype=int32)
这会告诉你哪三个邻居与你的new_data_point. 在下一段中,你将看到如何在估计中转换这些邻居。
多个邻居的投票或平均
确定了未知年龄鲍鱼的三个最近邻居的索引后,你现在需要将这些邻居合并到新数据点的预测中。
作为第一步,你需要找到这三个邻居的基本事实:>>>
>>> nearest_neighbor_rings = y[nearest_neighbor_ids]
>>> nearest_neighbor_rings
array([ 9, 11, 10])
现在你有了这三个邻居的值,你将把它们组合成新数据点的预测。将邻居组合成一个预测对于回归和分类的工作方式不同。
回归平均值
在回归问题中,目标变量是数字。你可以通过取目标变量值的平均值将多个邻居合并为一个预测。你可以按如下方式执行此操作:>>>
>>> prediction = nearest_neighbor_rings.mean()
你会得到一个10for的值prediction。这意味着新数据点的 3-Nearest Neighbor 预测为10。你可以对任意数量的新鲍鱼做同样的处理。
分类模式
在分类问题中,目标变量是分类的。如前所述,你不能对分类变量取平均值。例如,三个预测的汽车品牌的平均值是多少?那是不可能的。你不能对类预测应用平均值。
相反,在分类的情况下,你采用模式。众数是最常出现的值。这意味着你计算所有邻居的类,并保留最常见的类。预测值是在邻居中最常出现的值。
如果有多种模式,就有多种可能的解决方案。你可以从获胜者中随机选择最终获胜者。你还可以根据邻居的距离做出最终决定,在这种情况下,将保留最近邻居的众数。
你可以使用SciPy mode()函数计算模式。由于鲍鱼示例不是分类案例,以下代码显示了如何计算玩具示例的众数:>>>
>>> import scipy.stats
>>> class_neighbors = np.array(["A", "B", "B", "C"])
>>> scipy.stats.mode(class_neighbors)
ModeResult(mode=array(['B'], dtype='<U1'), count=array([2]))
如你所见,此示例中的模式是"B"因为它是输入数据中最常出现的值。
使用 scikit-learn 在 Python 中拟合 kNN
虽然从头开始编写算法非常适合学习目的,但在处理机器学习任务时通常不太实用。在本节中,你将探索 scikit-learn 中使用的 kNN 算法的实现,scikit-learn 是 Python 中最全面的机器学习包之一。
将数据拆分为训练集和测试集以进行模型评估
在本节中,你将评估鲍鱼 kNN 模型的质量。在前面的部分中,你专注于技术,但现在你将拥有更务实和以结果为导向的观点。
有多种评估模型的方法,但最常见的一种是训练-测试拆分。使用训练测试拆分进行模型评估时,你将数据集拆分为两部分:
- 训练数据用于拟合模型。对于 kNN,这意味着训练数据将用作邻居。
- 测试数据用于评估模型。这意味着你将对测试数据中每个鲍鱼的环数进行预测,并将这些结果与已知的真实环数进行比较。
你可以使用scikit-learn 的内置train_test_split()将数据拆分为 Python 中的训练集和测试集:>>>
>>> from sklearn.model_selection import train_test_split
>>> X_train, X_test, y_train, y_test = train_test_split(
... X, y, test_size=0.2, random_state=12345
... )
该test_size指的是要放在训练数据和测试数据的观测次数。如果指定 a test_sizeof 0.2,test_size则将是原始数据的 20%,因此将其他 80% 保留为训练数据。
该random_state是一个参数,使你可以得到相同的结果每次代码运行的时间。train_test_split()在数据中进行随机拆分,这对于再现结果是有问题的。因此,通常使用random_state. in 值的选择random_state是任意的。
在上面的代码中,你将数据分为训练数据和测试数据。这是客观模型评估所必需的。你现在可以继续使用 scikit-learn 在训练数据上拟合 kNN 模型。
将 scikit-learn 中的 kNN 回归拟合到鲍鱼数据集
要拟合 scikit-learn 中的模型,你首先要创建一个正确类的模型。此时,你还需要为超参数选择值。对于 kNN 算法,你需要选择 的值k,该值n_neighbors在 scikit-learn 实现中调用。以下是在 Python 中执行此操作的方法:>>>
>>> from sklearn.neighbors import KNeighborsRegressor
>>> knn_model = KNeighborsRegressor(n_neighbors=3)
你创建一个未拟合的模型knn_model。该模型将使用三个最近的邻居来预测未来数据点的值。要将数据导入模型,你可以在训练数据集上拟合模型:>>>
>>> knn_model.fit(X_train, y_train)
使用.fit(),你可以让模型从数据中学习。此时,knn_model包含对新鲍鱼数据点进行预测所需的一切。这就是使用 Python 拟合 kNN 回归所需的全部代码!
如何理解k-最近邻算法?使用 scikit-learn 检查模型拟合
然而,拟合模型是不够的。在本节中,你将了解一些可用于评估拟合的函数。
有许多可用于回归的评估指标,但你将使用最常见的指标之一,均方根误差 (RMSE)。预测的 RMSE 计算如下:
- 计算每个数据点的实际值和预测值之间的差异。
- 对于每个差异,取这个差异的平方。
- 对所有平方差求和。
- 求和值的平方根。
Python如何实现k-最近邻算法?首先,你可以评估训练数据的预测误差。这意味着你使用训练数据进行预测,因此你知道结果应该比较好。你可以使用以下代码获取 RMSE:>>>
>>> from sklearn.metrics import mean_squared_error
>>> from math import sqrt
>>> train_preds = knn_model.predict(X_train)
>>> mse = mean_squared_error(y_train, train_preds)
>>> rmse = sqrt(mse)
>>> rmse
1.65
在此代码中,你使用knn_model在前一个代码块中拟合的来计算 RMSE 。你现在计算训练数据的 RMSE。为了获得更真实的结果,你应该评估未包含在模型中的数据的性能。这就是你现在将测试集分开的原因。你可以使用与之前相同的函数来评估测试集上的预测性能:>>>
>>> test_preds = knn_model.predict(X_test)
>>> mse = mean_squared_error(y_test, test_preds)
>>> rmse = sqrt(mse)
>>> rmse
2.37
在此代码块中,你评估模型尚不知道的数据的错误。这个更现实的 RMSE 比以前略高。RMSE 测量预测年龄的平均误差,因此你可以将其解释为平均误差为1.65年。无论是从提高2.37年1.65多年良好的情况下,具体的。至少你离正确估计年龄越来越近了。
到目前为止,你只使用了开箱即用的 scikit-learn kNN 算法。你尚未对超参数进行任何调整并随机选择k. 你可以观察到训练数据上的 RMSE 和测试数据上的 RMSE 之间存在相对较大的差异。这意味着模型在训练数据上过度拟合:它不能很好地泛化。
在这一点上,这没什么好担心的。在下一部分中,你将看到如何使用各种调整方法来优化预测误差或测试误差。
Python k-最近邻算法:绘制模型的拟合
在开始改进模型之前要查看的最后一件事是模型的实际拟合。要了解模型学到了什么,你可以使用 Matplotlib 可视化你的预测是如何进行的:>>>
>>> import seaborn as sns
>>> cmap = sns.cubehelix_palette(as_cmap=True)
>>> f, ax = plt.subplots()
>>> points = ax.scatter(
... X_test[:, 0], X_test[:, 1], c=test_preds, s=50, cmap=cmap
... )
>>> f.colorbar(points)
>>> plt.show()
在此代码块中,你使用SeabornX_test通过子集数组X_test[:,0]和来创建第一列和第二列的散点图X_test[:,1]。请记住,前两列是Length和Diameter。正如你在相关表中看到的那样,它们具有很强的相关性。
你用于c指定test_preds应将预测值 ( ) 用作颜色条。该参数s用于指定散点图中点的大小。你用于cmap指定cubehelix_palette颜色映射。要了解有关使用 Matplotlib 绘图的更多信息,请查看Python Plotting With Matplotlib。
使用上面的代码,你会得到下图:
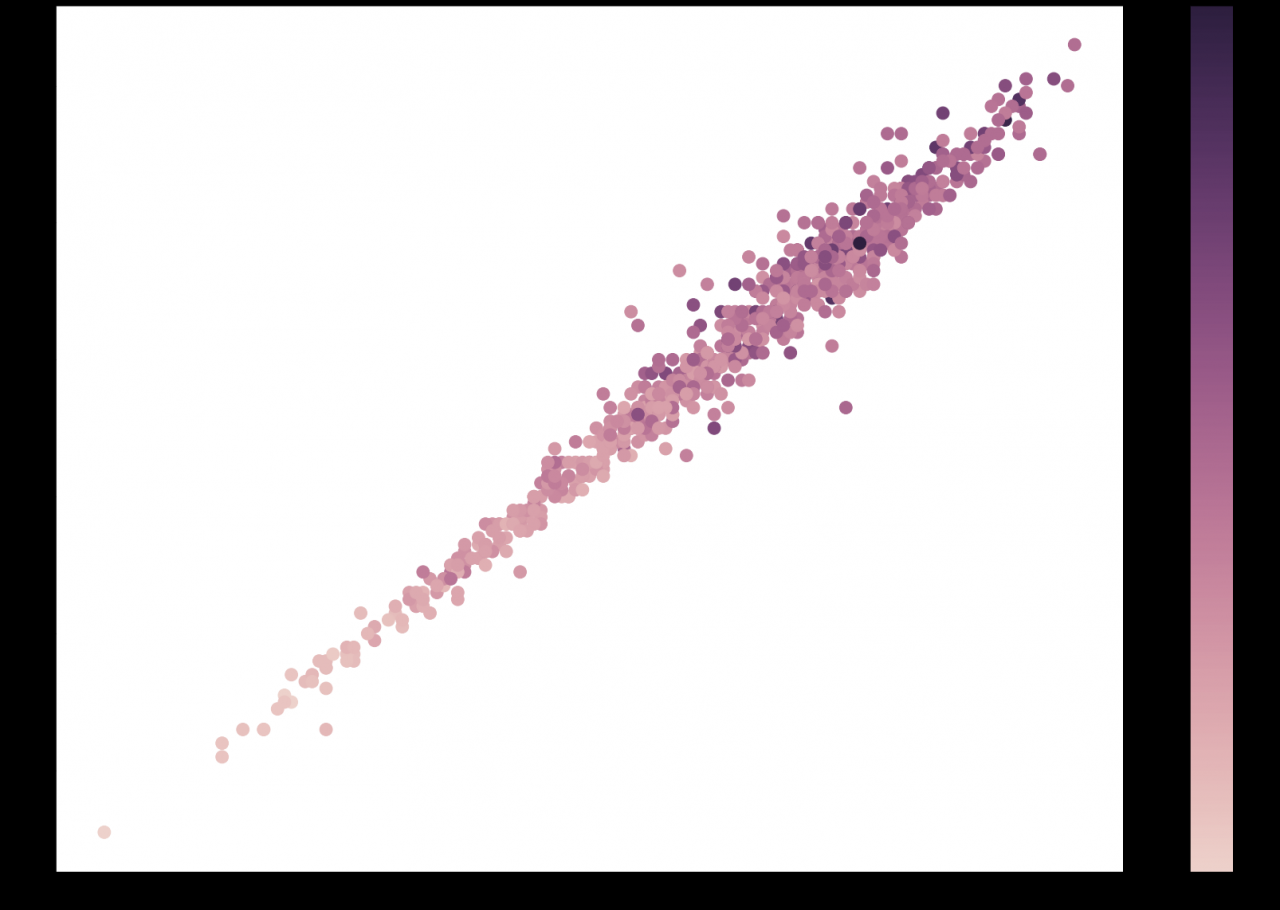
在该图中,每个点都是测试集中的一个鲍鱼,其实际长度和实际直径分别位于 X 轴和 Y 轴上。点的颜色反映了预测的年龄。你可以看到鲍鱼越长越大,其预测年龄越高。这是合乎逻辑的,这是一个积极的信号。这意味着你的模型正在学习一些看起来正确的东西。
要确认实际鲍鱼数据中是否存在这种趋势,你可以通过简单地替换用于 的变量来对实际值执行相同操作c:>>>
>>> cmap = sns.cubehelix_palette(as_cmap=True)
>>> f, ax = plt.subplots()
>>> points = ax.scatter(
... X_test[:, 0], X_test[:, 1], c=y_test, s=50, cmap=cmap
>>> )
>>> f.colorbar(points)
>>> plt.show()
此代码使用 Seaborn 创建带有颜色条的散点图。它产生以下图形:
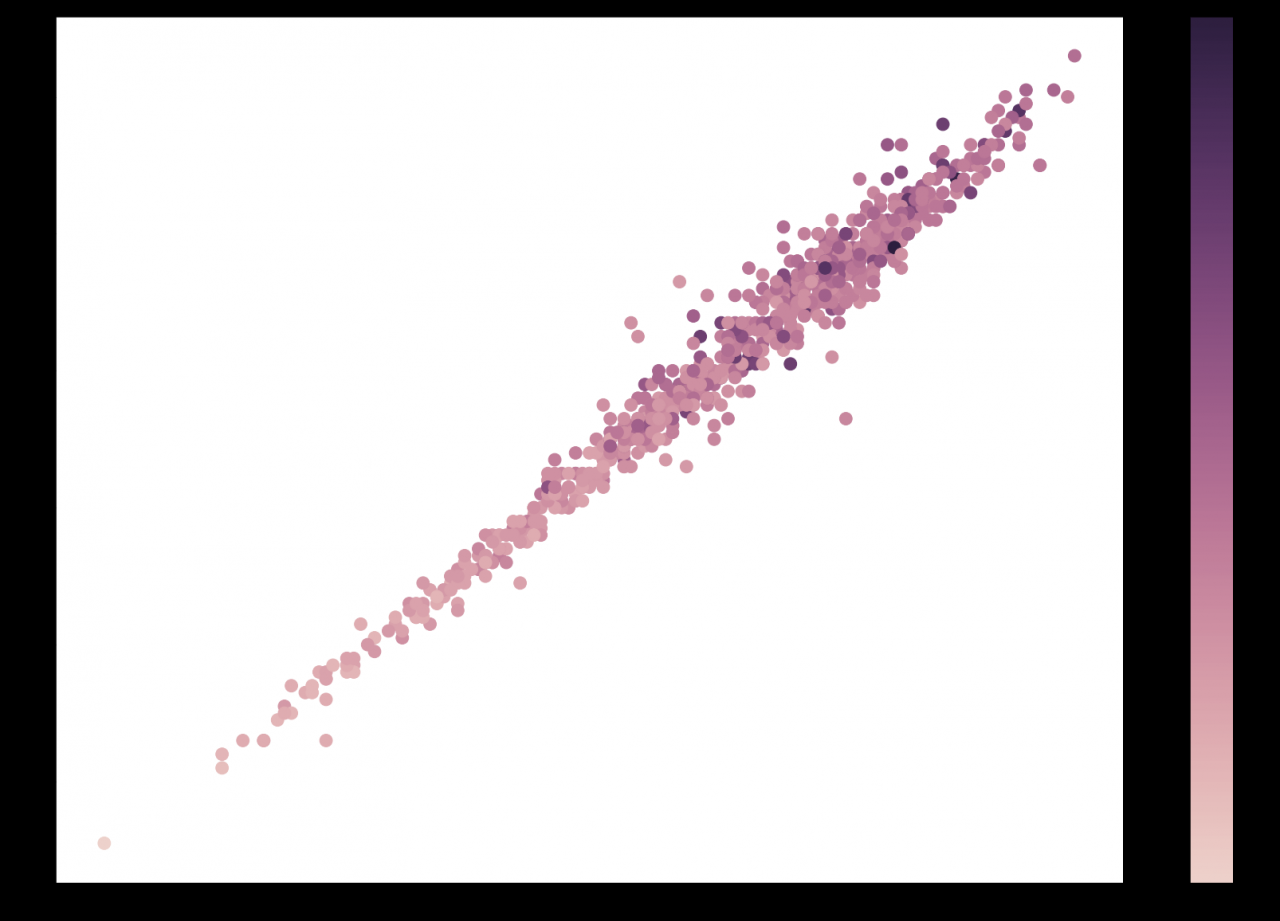
这证实了你的模型正在学习的趋势确实有意义。
你可以为七个自变量的每个组合提取可视化。对于本教程,这会太长,但不要犹豫,尝试一下。唯一需要更改的是散点图中指定的列。
这些可视化是七维数据集的二维视图。如果你和他们一起玩,它会让你很好地理解模型正在学习什么,也许,它没有学习什么或学习错误。
使用 scikit-learn 在 Python 中调整和优化 kNN
kNN工作原理:有多种方法可以提高你的预测分数。通过使用data wrangling 处理输入数据可以进行一些改进,但在本教程中,重点是 kNN 算法。接下来,你将了解改进建模管道算法部分的方法。
使用 scikit-learn 提高 kNN 性能 GridSearchCV
到目前为止,你一直在使用k=3kNN 算法,但最佳值k是你需要为每个数据集凭经验找到的值。
当你使用很少的邻居时,你的预测将比使用更多邻居时的变化大得多:
- 如果你仅使用一个邻居,则预测可能会从一个点到另一个点发生强烈变化。当你想到自己的邻居时,他们可能与其他人大不相同。如果你住在离群值旁边,那么你的 1-NN 预测将是错误的。
- 如果你有多个数据点,一个截然不同的邻居的影响将小得多。
- 如果使用太多邻居,则每个点的预测可能会非常接近。假设你使用所有邻居进行预测。在这种情况下,每个预测都是相同的。
要找到 的最佳值k,你将使用一个名为 的工具GridSearchCV。这是一种经常用于调整机器学习模型超参数的工具。在你的情况下,它将通过自动k为你的数据集找到最佳值来提供帮助。
GridSearchCV 可在 scikit-learn 中使用,它的优点是使用方式与 scikit-learn 模型几乎完全相同:>>>
>>> from sklearn.model_selection import GridSearchCV
>>> parameters = {"n_neighbors": range(1, 50)}
>>> gridsearch = GridSearchCV(KNeighborsRegressor(), parameters)
>>> gridsearch.fit(X_train, y_train)
GridSearchCV(estimator=KNeighborsRegressor(),
param_grid={'n_neighbors': range(1, 50),
'weights': ['uniform', 'distance']})
在这里,你使用GridSearchCV拟合模型。简而言之,GridSearchCV在一部分数据上反复拟合 kNN 回归器,并在数据的其余部分上测试性能。重复执行此操作将产生对每个值的预测性能的可靠估计k。在此示例中,你将测试从1到的值50。
最后,它将保留 的最佳性能值k,你可以通过以下方式访问.best_params_:>>>
>>> gridsearch.best_params_
{'n_neighbors': 25, 'weights': 'distance'}
在此代码中,你打印具有最低错误分数的参数。使用.best_params_,你可以看到选择25作为值k将产生最佳预测性能。现在你知道什么是最佳值k,你可以了解它如何影响你的训练和测试性能:>>>
>>> train_preds_grid = gridsearch.predict(X_train)
>>> train_mse = mean_squared_error(y_train, train_preds_grid)
>>> train_rmse = sqrt(train_mse)
>>> test_preds_grid = gridsearch.predict(X_test)
>>> test_mse = mean_squared_error(y_test, test_preds_grid)
>>> test_rmse = sqrt(test_mse)
>>> train_rmse
2.0731294674202143
>>> test_rmse
2.1700197339962175
使用此代码,你可以在训练数据上拟合模型并评估测试数据。可以看到训练误差比之前差,但是测试误差比之前好。这意味着你的模型与训练数据的拟合度较低。使用GridSearchCV找到 的值k减少了训练数据过度拟合的问题。
如何理解k-最近邻算法?根据距离添加邻居的加权平均值
使用GridSearchCV,你将测试 RMSE 从 减少2.37到2.17。在本节中,你将看到如何进一步提高性能。
下面,你将测试使用加权平均值而不是常规平均值进行预测时模型的性能是否会更好。这意味着距离较远的邻居对预测的影响较小。
你可以通过weights将超参数设置为 的值来做到这一点"distance"。但是,设置此加权平均值可能会对 的最佳值产生影响k。因此,你将再次使用GridSearchCV来告诉你应该使用哪种类型的平均:>>>
>>> parameters = {
... "n_neighbors": range(1, 50),
... "weights": ["uniform", "distance"],
... }
>>> gridsearch = GridSearchCV(KNeighborsRegressor(), parameters)
>>> gridsearch.fit(X_train, y_train)
GridSearchCV(estimator=KNeighborsRegressor(),
param_grid={'n_neighbors': range(1, 50),
'weights': ['uniform', 'distance']})
>>> gridsearch.best_params_
{'n_neighbors': 25, 'weights': 'distance'}
>>> test_preds_grid = gridsearch.predict(X_test)
>>> test_mse = mean_squared_error(y_test, test_preds_grid)
>>> test_rmse = sqrt(test_mse)
>>> test_rmse
2.163426558494748
在这里,你测试使用不同的称重是否有意义GridSearchCV。应用加权平均而不是常规平均已将预测误差从 降低2.17到2.1634。虽然这不是一个巨大的改进,但它仍然更好,这使它值得。
使用 Bagging 进一步改进 scikit-learn 中的 kNN
Python如何实现k-最近邻算法?作为 kNN 调优的第三步,你可以使用bagging。Bagging 是一种集成方法,或者是一种采用相对简单的机器学习模型并拟合大量这些模型的方法,每次拟合都有细微的变化。Bagging 经常使用决策树,但 kNN 也能完美运行。
集成方法通常比单个模型性能更高。一个模型可能会不时出错,但一百个模型的平均值应该不会出错。不同个体模型的误差可能会相互平均,结果预测的可变性会更小。
你可以使用 scikit-learn 使用以下步骤将装袋应用于 kNN 回归。首先,创建KNeighborsRegressor具有最佳选择的k和weights你从中获得的GridSearchCV:>>>
>>> best_k = gridsearch.best_params_["n_neighbors"]
>>> best_weights = gridsearch.best_params_["weights"]
>>> bagged_knn = KNeighborsRegressor(
... n_neighbors=best_k, weights=best_weights
... )
然后BaggingRegressor从 scikit-learn导入类并100使用bagged_knn模型创建一个带有估计器的新实例:>>>
>>> from sklearn.ensemble import BaggingRegressor
>>> bagging_model = BaggingRegressor(bagged_knn, n_estimators=100)
现在你可以进行预测并计算 RMSE 以查看它是否有所改善:>>>
>>> test_preds_grid = bagging_model.predict(X_test)
>>> test_mse = mean_squared_error(y_test, test_preds_grid)
>>> test_rmse = sqrt(test_mse)
>>> test_rmse
2.1616
袋装 kNN 上的预测误差为2.1616,略小于你之前获得的误差。执行确实需要更多时间,但对于此示例,这没有问题。
四种型号的比较
在三个增量步骤中,你已经提高了算法的预测性能。下表显示了不同型号及其性能的概述:
| 模型 | 错误 |
|---|---|
随意的 k | 2.37 |
GridSearchCV 为了 k | 2.17 |
GridSearchCV对于k和weights | 2.1634 |
装袋和 GridSearchCV | 2.1616 |
在此表中,你可以看到从最简单到最复杂的四个模型。复杂度的顺序对应于错误度量的顺序。带有随机的模型k表现最差,带有装袋的模型GridSearchCV表现最好。
鲍鱼预测可能会有更多改进。例如,可以寻找以不同方式处理数据的方法或查找其他外部数据源。
Python k-最近邻算法结论
现在你已经了解了 kNN 算法的所有知识,你已准备好开始在 Python 中构建高性能预测模型。从基本的 kNN 模型转变为完全调优的模型需要几步,但性能提升是完全值得的!
如何理解k-最近邻算法?在本教程中,你学习了如何:
- 了解kNN 算法背后的数学基础
- kNN工作原理
- 在NumPy 中从头开始编写kNN 算法
- 使用scikit-learn实现以最少的代码量拟合 kNN
- 使用
GridSearchCV找到最好的k近邻超参数 - 按k近邻到其最大性能使用装袋
模型调优工具的一个好处是,它们中的许多不仅适用于 kNN 算法,而且还适用于许多其他机器学习算法。要继续你的机器学习之旅,请查看机器学习学习路径,并随时发表评论以分享你可能有的任何问题或评论。

