需要获取Pandas DataFrame的描述性统计数据吗?Pandas DataFrame如何获取描述性统计量?
如果是这样,你可以使用以下模板获取DataFrame 中特定列的描述性统计信息:
df['DataFrame Column'].describe()或者,你可以使用此模板获取整个DataFrame的描述性统计信息:
df.describe(include='all')在下一节中,我将通过一个示例向你展示导出描述性统计量的步骤。
获取Pandas DataFrame描述性统计数据的步骤
第 1 步:收集数据
首先,你需要为 DataFrame 收集数据。例如,我收集了以下有关汽车的数据:
| Brand | Price | Year |
| Honda Civic | 22000 | 2014 |
| Ford Focus | 27000 | 2015 |
| Toyota Corolla | 25000 | 2016 |
| Toyota Corolla | 29000 | 2017 |
| Audi A4 | 35000 | 2018 |
第 2 步:创建数据帧
接下来,你需要根据收集的数据创建 DataFrame。
对于我们的示例,创建 DataFrame 的代码是:
from pandas import DataFrame
Cars = {'Brand': ['Honda Civic','Ford Focus','Toyota Corolla','Toyota Corolla','Audi A4'],
'Price': [22000,27000,25000,29000,35000],
'Year': [2014,2015,2016,2017,2018]
}
df = DataFrame(Cars, columns= ['Brand', 'Price','Year'])
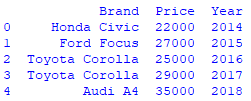
print (df)用 Python 运行代码,你会得到这个 DataFrame:
第 3 步:获取Pandas DataFrame的描述性统计信息
准备好 DataFrame 后,你将能够使用你在本指南开头看到的模板获取描述性统计信息:
df['DataFrame Column'].describe()假设你想要获取包含数字数据的“价格”字段的描述性统计数据。 在这种情况下,你需要应用的语法是:
df['Price'].describe()所以完整的 Python 代码如下Pandas DataFrame获取描述性统计量示例:
from pandas import DataFrame
Cars = {'Brand': ['Honda Civic','Ford Focus','Toyota Corolla','Toyota Corolla','Audi A4'],
'Price': [22000,27000,25000,29000,35000],
'Year': [2014,2015,2016,2017,2018]
}
df = DataFrame(Cars, columns= ['Brand', 'Price','Year'])
stats_numeric = df['Price'].describe()
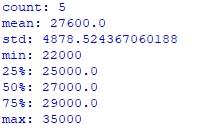
print (stats_numeric)运行代码后,你将获得“价格”字段的描述性统计信息:

你会注意到输出包含 6 个小数位。然后,你可以将astype (int)的语法添加 到代码中以获取整数值。
这是代码的样子:
from pandas import DataFrame
Cars = {'Brand': ['Honda Civic','Ford Focus','Toyota Corolla','Toyota Corolla','Audi A4'],
'Price': [22000,27000,25000,29000,35000],
'Year': [2014,2015,2016,2017,2018]
}
df = DataFrame(Cars, columns= ['Brand', 'Price','Year'])
stats_numeric = df['Price'].describe().astype (int)
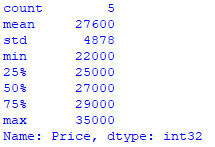
print (stats_numeric)运行代码,你只会得到整数:
分类数据的描述性统计
Pandas DataFrame如何获取描述性统计量?到目前为止,你已经了解了如何获取数值数据的描述性统计量。“价格”字段用于此目的。
但是,你还可以获得分类数据的描述性统计数据。
例如,你可以使用以下代码获取“品牌”字段的一些描述性统计信息:
from pandas import DataFrame
Cars = {'Brand': ['Honda Civic','Ford Focus','Toyota Corolla','Toyota Corolla','Audi A4'],
'Price': [22000,27000,25000,29000,35000],
'Year': [2014,2015,2016,2017,2018]
}
df = DataFrame(Cars, columns= ['Brand', 'Price','Year'])
stats_categorical = df['Brand'].describe()
print (stats_categorical)这是你会得到的结果:

获取整 Pandas DataFrame的描述性统计信息
最后,你可以应用以下模板来获取整个DataFrame的描述性统计信息:
df.describe(include='all')所以完整的 Python 代码如下所示:
from pandas import DataFrame
Cars = {'Brand': ['Honda Civic','Ford Focus','Toyota Corolla','Toyota Corolla','Audi A4'],
'Price': [22000,27000,25000,29000,35000],
'Year': [2014,2015,2016,2017,2018]
}
df = DataFrame(Cars, columns= ['Brand', 'Price','Year'])
stats = df.describe(include='all')
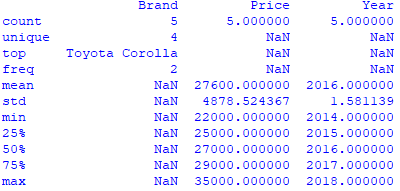
print (stats)运行代码,你会得到如下结果:
Pandas DataFrame的描述性统计量:分解描述性统计数据
你可以将描述性统计进一步细分为以下内容:
计数:
df['DataFrame Column'].count()平均数:
df['DataFrame Column'].mean()标准偏差:
df['DataFrame Column'].std()最小值:
df['DataFrame Column'].min()0.25 分位数:
df['DataFrame Column'].quantile(q=0.25)0.50 分位数(中位数):
df['DataFrame Column'].quantile(q=0.50)0.75 分位数:
df['DataFrame Column'].quantile(q=0.75)最大值:
df['DataFrame Column'].max()Pandas DataFrame如何获取描述性统计量?对于我们的示例, df['DataFrame Column'] 是df['Price']。
因此,我们示例的完整 Python 代码如下Pandas DataFrame获取描述性统计量示例:
from pandas import DataFrame
Cars = {'Brand': ['Honda Civic','Ford Focus','Toyota Corolla','Toyota Corolla','Audi A4'],
'Price': [22000,27000,25000,29000,35000],
'Year': [2014,2015,2016,2017,2018]
}
df = DataFrame(Cars, columns= ['Brand', 'Price','Year'])
count1 = df['Price'].count()
print('count: ' + str(count1))
mean1 = df['Price'].mean()
print('mean: ' + str(mean1))
std1 = df['Price'].std()
print('std: ' + str(std1))
min1 = df['Price'].min()
print('min: ' + str(min1))
quantile1 = df['Price'].quantile(q=0.25)
print('25%: ' + str(quantile1))
quantile2 = df['Price'].quantile(q=0.50)
print('50%: ' + str(quantile2))
quantile3 = df['Price'].quantile(q=0.75)
print('75%: ' + str(quantile3))
max1 = df['Price'].max()
print('max: ' + str(max1))在 Python 中运行代码后,你将获得以下统计信息: