
在本指南中,我将向你展示如何使用pandas在 Python 中创建数据透视表。特别是,我将演示如何在 5 个简单场景中创建数据透视表。
使用 Pandas 在 Python 中创建数据透视表
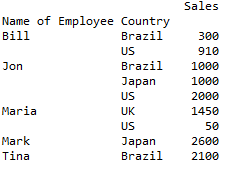
如何使用Pandas创建数据透视表?首先,这是用于在 Python 中创建数据透视表的数据集:
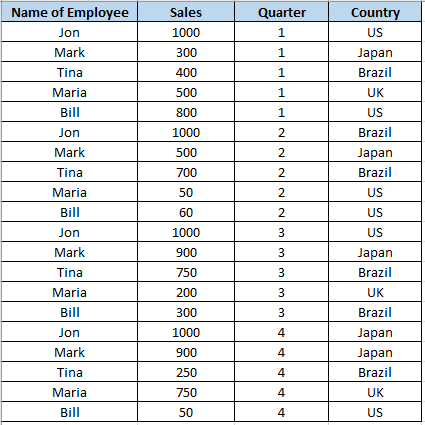
首先,你需要在 Python 中捕获上述数据。
但是你会怎么做呢?
Pandas创建数据透视表的方法 - 你可以使用pandas DataFrame完成此任务:
import pandas as pd
employees = {'Name of Employee': ['Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill'],
'Sales': [1000,300,400,500,800,1000,500,700,50,60,1000,900,750,200,300,1000,900,250,750,50],
'Quarter': [1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4],
'Country': ['US','Japan','Brazil','UK','US','Brazil','Japan','Brazil','US','US','US','Japan','Brazil','UK','Brazil','Japan','Japan','Brazil','UK','US']
}
df = pd.DataFrame(employees, columns= ['Name of Employee','Sales','Quarter','Country'])
print (df)在 Python 中运行上面的代码,你会得到这个 DataFrame:
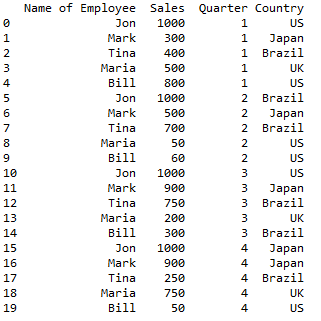
准备好 DataFrame 后,你就可以对数据进行透视了。
假设你的目标是确定:
- 每位员工的总销售额
- 按国家/地区的总销售额
- 员工和国家/地区的销售额
- 按国家/地区的最大单笔销售额
- 按国家/地区划分的平均、中位数和最低销售额
接下来,你将看到如何根据这 5 个场景来透视数据。
使用 Pandas 的 Python 数据透视表的 5 个场景
场景 1:每位员工的总销售额
要获得每位员工的总销售额,你需要将以下语法添加到 Python 代码中:
pivot = df.pivot_table(index=['Name of Employee'], values=['Sales'], aggfunc='sum')这将允许你总结 通过每名员工的销售(横跨四个季度)aggfunc =“sum”操作。
完整的 Python 代码如下所示:
import pandas as pd
employees = {'Name of Employee': ['Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill'],
'Sales': [1000,300,400,500,800,1000,500,700,50,60,1000,900,750,200,300,1000,900,250,750,50],
'Quarter': [1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4],
'Country': ['US','Japan','Brazil','UK','US','Brazil','Japan','Brazil','US','US','US','Japan','Brazil','UK','Brazil','Japan','Japan','Brazil','UK','US']
}
df = pd.DataFrame(employees, columns= ['Name of Employee','Sales','Quarter','Country'])
pivot = df.pivot_table(index=['Name of Employee'], values=['Sales'], aggfunc='sum')
print (pivot)运行代码后,你将获得员工的总销售额:
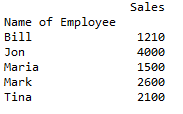
场景 2:按国家/地区划分的总销售额
如何使用Pandas创建数据透视表?现在,你将看到如何按县对总销售额进行分组。
Pandas创建数据透视表的方法:在这里,你需要按“国家/地区”字段聚合结果,而不是按照你在第一个场景中看到的“员工姓名”。
然后,你可以在 Python 中运行以下Pandas创建数据透视表示例代码:
import pandas as pd
employees = {'Name of Employee': ['Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill'],
'Sales': [1000,300,400,500,800,1000,500,700,50,60,1000,900,750,200,300,1000,900,250,750,50],
'Quarter': [1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4],
'Country': ['US','Japan','Brazil','UK','US','Brazil','Japan','Brazil','US','US','US','Japan','Brazil','UK','Brazil','Japan','Japan','Brazil','UK','US']
}
df = pd.DataFrame(employees, columns= ['Name of Employee','Sales','Quarter','Country'])
pivot = df.pivot_table(index=['Country'], values=['Sales'], aggfunc='sum')
print (pivot)然后你将获得按县划分的总销售额:
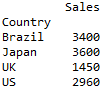
但是如果你想绘制这些结果呢?
为此,你需要将以下 3 个组件添加到代码中:
- 在代码顶部导入 matplotlib.pyplot 作为 plt
- 'pivot' 变量末尾的plot()
- 代码底部的plt.show()
在运行下面的代码之前,请确保 matplotlib 包已安装在 Python 中。
import matplotlib.pyplot as plt
import pandas as pd
employees = {'Name of Employee': ['Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill'],
'Sales': [1000,300,400,500,800,1000,500,700,50,60,1000,900,750,200,300,1000,900,250,750,50],
'Quarter': [1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4],
'Country': ['US','Japan','Brazil','UK','US','Brazil','Japan','Brazil','US','US','US','Japan','Brazil','UK','Brazil','Japan','Japan','Brazil','UK','US']
}
df = pd.DataFrame(employees, columns= ['Name of Employee','Sales','Quarter','Country'])
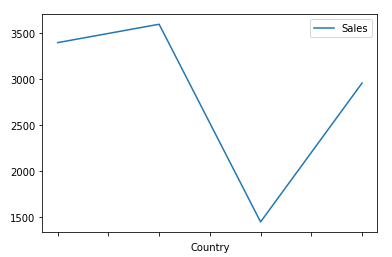
pivot = df.pivot_table(index=['Country'], values=['Sales'], aggfunc='sum').plot()
plt.show()当你运行代码时,你会得到这个图:
场景 3:员工和国家/地区的销售额
你可以按多个字段聚合结果(与基于单个字段聚合结果的前两种情况不同)。
例如,你可以使用以下两个字段来获取以下两个方面的销售额:
- 员工姓名;和
- 国家
import pandas as pd
employees = {'Name of Employee': ['Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill'],
'Sales': [1000,300,400,500,800,1000,500,700,50,60,1000,900,750,200,300,1000,900,250,750,50],
'Quarter': [1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4],
'Country': ['US','Japan','Brazil','UK','US','Brazil','Japan','Brazil','US','US','US','Japan','Brazil','UK','Brazil','Japan','Japan','Brazil','UK','US']
}
df = pd.DataFrame(employees, columns= ['Name of Employee','Sales','Quarter','Country'])
pivot = df.pivot_table(index=['Name of Employee','Country'], values=['Sales'], aggfunc='sum')
print (pivot)运行代码,你将看到员工和国家/地区的销售额:
场景 4:按国家/地区的最大个人销售额
到目前为止,你使用 sum 操作(即 aggfunc='sum')对结果进行分组,但你不仅限于该操作。
如何使用Pandas创建数据透视表?在这种情况下,你将使用aggfunc='max'按县找到最大的个人销售额,Pandas创建数据透视表示例代码:
import pandas as pd
employees = {'Name of Employee': ['Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill'],
'Sales': [1000,300,400,500,800,1000,500,700,50,60,1000,900,750,200,300,1000,900,250,750,50],
'Quarter': [1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4],
'Country': ['US','Japan','Brazil','UK','US','Brazil','Japan','Brazil','US','US','US','Japan','Brazil','UK','Brazil','Japan','Japan','Brazil','UK','US']
}
df = pd.DataFrame(employees, columns= ['Name of Employee','Sales','Quarter','Country'])
pivot = df.pivot_table(index=['Country'], values=['Sales'], aggfunc='max')
print (pivot)结果:
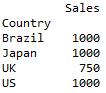
场景 5:按国家/地区划分的平均、中值和最低销售额
你可以在aggfunc参数中使用多个操作 。例如,要按国家/地区查找平均值、中位数和最低销售额,你可以使用:
aggfunc={'median','mean','min'}这是完整的 Python 代码:
import pandas as pd
employees = {'Name of Employee': ['Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill'],
'Sales': [1000,300,400,500,800,1000,500,700,50,60,1000,900,750,200,300,1000,900,250,750,50],
'Quarter': [1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4],
'Country': ['US','Japan','Brazil','UK','US','Brazil','Japan','Brazil','US','US','US','Japan','Brazil','UK','Brazil','Japan','Japan','Brazil','UK','US']
}
df = pd.DataFrame(employees, columns= ['Name of Employee','Sales','Quarter','Country'])
pivot = df.pivot_table(index=['Country'], values=['Sales'], aggfunc={'median','mean','min'})
print (pivot)然后你会得到以下结果:
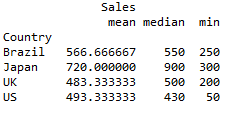
想要绘制结果?
Pandas创建数据透视表的方法 - 没问题,只需应用以下Pandas创建数据透视表示例代码:
import matplotlib.pyplot as plt
import pandas as pd
employees = {'Name of Employee': ['Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill','Jon','Mark','Tina','Maria','Bill'],
'Sales': [1000,300,400,500,800,1000,500,700,50,60,1000,900,750,200,300,1000,900,250,750,50],
'Quarter': [1,1,1,1,1,2,2,2,2,2,3,3,3,3,3,4,4,4,4,4],
'Country': ['US','Japan','Brazil','UK','US','Brazil','Japan','Brazil','US','US','US','Japan','Brazil','UK','Brazil','Japan','Japan','Brazil','UK','US']
}
df = pd.DataFrame(employees, columns= ['Name of Employee','Sales','Quarter','Country'])
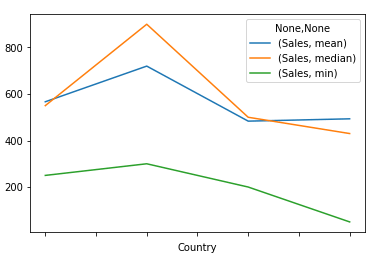
pivot = df.pivot_table(index=['Country'], values=['Sales'], aggfunc={'median','mean','min'}).plot()
plt.show()然后你会得到这个情节:
结论 – 在 Python 中使用 Pandas 数据透视表
如何使用Pandas创建数据透视表?数据透视表传统上与MS Excel相关联。但是,你可以使用Pandas在 Python 中轻松创建数据透视表。
你刚刚看到了如何在 5 个简单场景中创建数据透视表。但是这里回顾的概念可以应用于大量不同的场景。
你可以通过访问pandas 文档找到有关数据透视表的其他信息。

