
要在你的 shell 脚本中成功使用Linux sed编辑器和awk 命令,你必须了解正则表达式或简称为正则表达式。由于 regex 有很多引擎,我们将使用 shell regex 并查看 bash 使用 regex 的能力。
Linix Shell如何使用正则表达式?首先,我们需要了解什么是正则表达式;然后我们将看到很多Linux Sed和AWK示例,了解如何使用它。
Linix Shell正则表达式教程目录
- 什么是正则表达式
- 正则表达式的类型
- 定义 BRE 模式
- 特殊的角色
- 锚角色
- 点字符
- 字符类
- 否定字符类
- 使用范围
- 特殊字符类
- 星号
- 扩展正则表达式
- 问号
- 加号
- 大括号
- 管道符号
- 分组表达式
- 实际例子
- 计算目录文件
- 验证电子邮件地址
什么是正则表达式
有的人第一次看到正则表达式就说这些ASCII码是什么!!
嗯,一般来说,正则表达式或正则表达式是你定义的一种文本模式,像 sed 或 awk 这样的 Linux 程序使用它来过滤文本。
我们在介绍基本 Linux 命令时看到了其中的一些模式,并看到了ls 命令如何使用通配符来过滤输出。
正则表达式的类型
许多不同的应用程序在 Linux 中使用不同类型的正则表达式,例如包含在编程语言(Java、Perl、Python)和 Linux 程序(如 (sed、awk、grep ))和许多其他应用程序中的正则表达式。
正则表达式模式使用转换这些模式的正则表达式引擎。
Linux 有两个正则表达式引擎:
- 在基本正则表达式(BRE)引擎。
- 在扩展正则表达式(ERE)引擎。
大多数 Linux 程序都能很好地与 BRE 引擎规范配合使用,但一些工具(如 sed)了解一些 BRE 引擎规则。
POSIX ERE 引擎带有一些编程语言。它提供了更多的模式,比如匹配数字和单词。awk 命令使用 ERE 引擎来处理其正则表达式模式。
由于有许多正则表达式实现,因此很难编写适用于所有引擎的模式。因此,我们将专注于最常见的正则表达式并演示如何在 sed 和 awk 中使用它。
定义 BRE 模式
你可以定义一个模式来匹配这样的文本,Linix Shell正则表达式用法实例:
$ echo "Testing regex using sed" | sed -n '/regex/p'$ echo "Testing regex using awk" | awk '/regex/{print $0}'
你可能会注意到,正则表达式并不关心模式在何处出现或在数据流中出现了多少次。
要知道的第一条规则是正则表达式模式区分大小写。
$ echo "Welcome to LikeGeeks" | awk '/Geeks/{print $0}'$ echo "Welcome to Likegeeks" | awk '/Geeks/{print $0}'
第一个正则表达式成功是因为“Geeks”这个词以大写形式存在,而第二行失败是因为它使用了小写字母。
你可以在模式中使用空格或数字,如下所示:
$ echo "Testing regex 2 again" | awk '/regex 2/{print $0}'
特殊的字符
Linix Shell如何使用正则表达式?正则表达式模式使用一些特殊字符。而且你不能将它们包含在你的模式中,如果你这样做,你将无法获得预期的结果。
这些特殊字符被正则表达式识别:
.*[]^${}\+?|()你需要使用反斜杠字符 (\) 对这些特殊字符进行转义。
例如,如果要匹配美元符号 ($),请使用反斜杠字符对其进行转义,如下所示:
$ cat myfile
There is 10$ on my pocket$ awk '/\$/{print $0}' myfile
如果你需要匹配反斜杠 (\) 本身,你需要像这样转义它:
$ echo "\ is a special character" | awk '/\\/{print $0}'
尽管正斜杠不是特殊字符,但如果直接使用它仍然会出错。
$ echo "3 / 2" | awk '///{print $0}'
所以你需要像这样逃避它:
$ echo "3 / 2" | awk '/\//{print $0}'
锚字符
要定位文本中一行的开头,请使用插入字符 (^)。
你可以这样使用它:
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}'$ echo "likegeeks website" | awk '/^likegeeks/{print $0}'
插入符号 (^) 匹配文本的开头:
$ awk '/^this/{print $0}' myfile如果你在文本中间使用它怎么办?
$ echo "This ^ caret is printed as it is" | sed -n '/s ^/p'它像普通字符一样打印。
使用 awk 时,你必须像这样转义它:
$ echo "This ^ is a test" | awk '/s \^/{print $0}'这是看正文的开头,看结尾呢?
美元符号 ($) 检查一行的结尾:
$ echo "Testing regex again" | awk '/again$/{print $0}'
你可以在同一行中同时使用插入符号和美元符号,如下所示:
$ cat myfile
this is a test
This is another test
And this is one more$ awk '/^this is a test$/{print $0}' myfile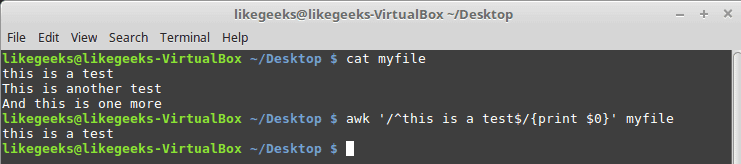
如你所见,它仅打印仅具有匹配模式的行。
你可以使用以下模式过滤空行:
$ awk '!/^$/{print $0}' myfile这里我们介绍一下你可以用感叹号做的否定!
该模式搜索行首和行尾之间没有任何内容的空行,并否定仅打印行有文本的空行。
点字符
我们使用点字符来匹配除换行符 (\n) 之外的任何字符。
查看以下示例以获取想法:
$ cat myfile
this is a test
This is another test
And this is one more
start with this$ awk '/.st/{print $0}' myfile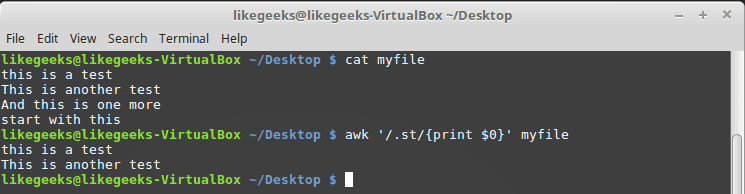
你可以从结果中看到它只打印前两行,因为它们包含 st 模式,而第三行没有该模式,而第四行以 st 开头,因此也与我们的模式不匹配。
字符类
Linix Shell正则表达式教程:你可以用点特殊字符匹配任何字符,但是如果你只匹配一组字符,你可以使用字符类。
字符类匹配一组字符,如果找到任何字符,则模式匹配。
我们可以像这样使用方括号 [] 定义字符类:
$ awk '/[oi]th/{print $0}' myfile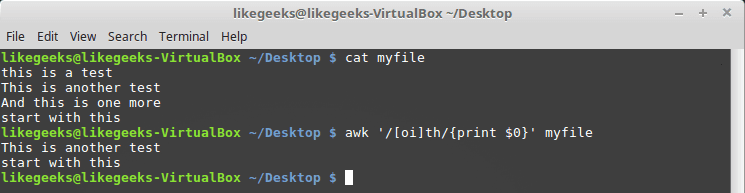
在这里,我们搜索任何前面有 o 字符或 i 的字符。
当你搜索可能包含大写或小写的单词并且你对此不确定时,这会很方便,Linux Sed和AWK示例:
$ echo "testing regex" | awk '/[Tt]esting regex/{print $0}'$ echo "Testing regex" | awk '/[Tt]esting regex/{print $0}'
当然,不限于字符;你可以使用数字或任何你想要的。只要你有这个想法,你就可以随心所欲地使用它。
否定字符类
搜索一个不在字符类中的字符怎么样?
要实现这一点,请在字符类范围之前添加一个像这样的插入符号:
$ awk '/[^oi]th/{print $0}' myfile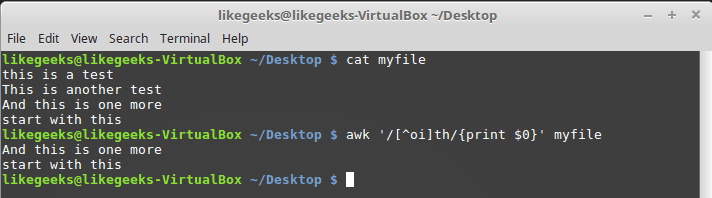
所以除了 o 和 i 之外,任何东西都是可以接受的。
使用范围
要指定一个字符范围,你可以使用 (-) 符号,如下所示:
$ awk '/[e-p]st/{print $0}' myfile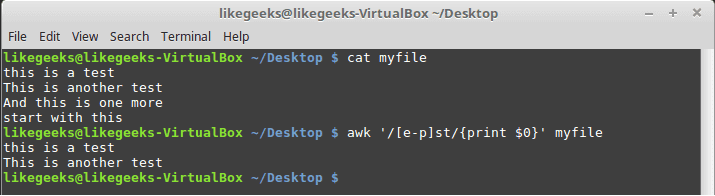
这匹配 e 和 p 之间的所有字符,然后是 st,如图所示。
你还可以使用数字范围:
$ echo "123" | awk '/[0-9][0-9][0-9]/'$ echo "12a" | awk '/[0-9][0-9][0-9]/'
你可以像这样使用多个和分隔的范围:
$ awk '/[a-fm-z]st/{print $0}' myfile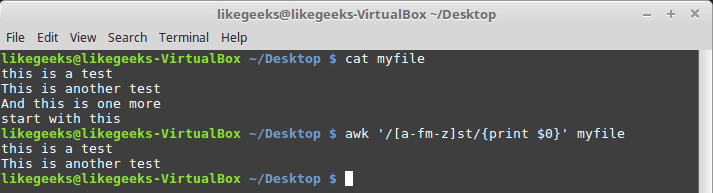
这里的模式表示从 a 到 f,而 m 到 z 必须出现在 st 文本之前。
特殊字符类
以下列表包括你可以使用它们的特殊字符类:
| [[:alpha:]] | 任何字母字符的模式,大写或小写。 |
| [[:alnum:]] | 0–9、A–Z 或 a–z 的模式。 |
| [[:blank:]] | 仅用于空格或制表符的模式。 |
| [[:digit:]] | 0 到 9 的模式。 |
| [[:lower:]] | 仅适用于 a-z 小写字母的模式。 |
| [[:print:]] | 任何可打印字符的模式。 |
| [[:punct:]] | 任何标点符号的模式。 |
| [[:space:]] | 任何空白字符的模式:空格、制表符、NL、FF、VT、CR。 |
| [[:upper:]] | 仅适用于 A–Z 大写的模式。 |
你可以像这样使用它们,Linix Shell正则表达式用法实例:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}'$ echo "abc" | awk '/[[:digit:]]/{print $0}'$ echo "abc123" | awk '/[[:digit:]]/{print $0}'
星号
星号表示该字符必须出现零次或多次。
$ echo "test" | awk '/tes*t/{print $0}'$ echo "tessst" | awk '/tes*t/{print $0}'
此模式符号可用于检查拼写错误或语言变体。
$ echo "I like green color" | awk '/colou*r/{print $0}'$ echo "I like green colour " | awk '/colou*r/{print $0}'
Linix Shell如何使用正则表达式?在这些示例中,无论你键入颜色还是颜色,它都会匹配,因为星号表示“u”字符是否存在多次或零次匹配。
要匹配任意数量的任何字符,你可以使用带星号的点,如下所示:
$ awk '/this.*test/{print $0}' myfile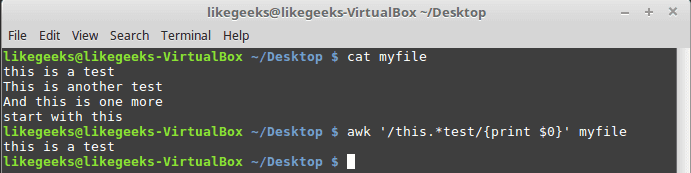
无论“this”和“test”之间有多少个单词,任何匹配的行都将被打印出来。
你可以在字符类中使用星号字符。
$ echo "st" | awk '/s[ae]*t/{print $0}'$ echo "sat" | awk '/s[ae]*t/{print $0}'$ echo "set" | awk '/s[ae]*t/{print $0}'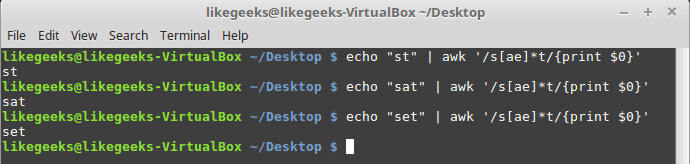
所有三个示例都匹配,因为星号表示如果你找到零次或多次任何“a”字符或“e”,则将其打印出来。
Linix Shell正则表达式教程:扩展正则表达式
以下是属于 Posix ERE 的一些模式:
问号
问号表示前一个字符可以存在一次或不存在。
$ echo "tet" | awk '/tes?t/{print $0}'$ echo "test" | awk '/tes?t/{print $0}'$ echo "tesst" | awk '/tes?t/{print $0}'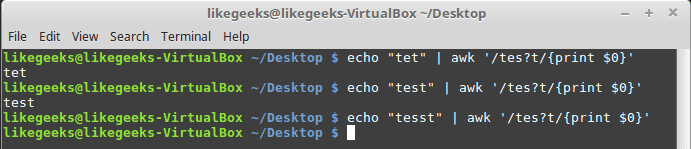
我们可以将问号与字符类结合使用:
$ echo "tst" | awk '/t[ae]?st/{print $0}'$ echo "test" | awk '/t[ae]?st/{print $0}'$ echo "tast" | awk '/t[ae]?st/{print $0}'$ echo "taest" | awk '/t[ae]?st/{print $0}'$ echo "teest" | awk '/t[ae]?st/{print $0}'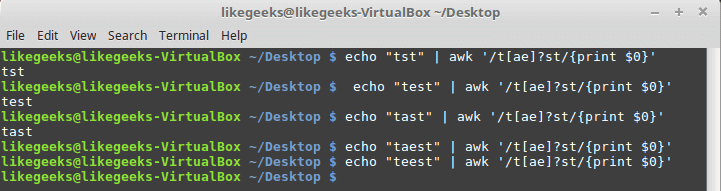
如果存在任何字符类项,则模式匹配通过。否则,模式将失败。
加号
加号表示加号之前的字符应该出现一次或多次,但必须至少出现一次。
$ echo "test" | awk '/te+st/{print $0}'$ echo "teest" | awk '/te+st/{print $0}'$ echo "tst" | awk '/te+st/{print $0}'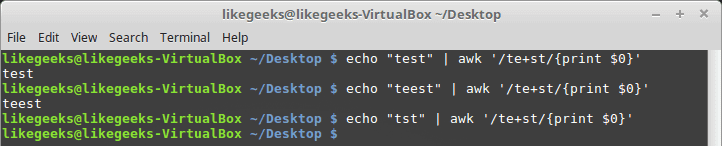
如果未找到“e”字符,则失败。
你可以将它与这样的字符类一起使用, Linux Sed和AWK示例:
$ echo "tst" | awk '/t[ae]+st/{print $0}'$ echo "test" | awk '/t[ae]+st/{print $0}'$ echo "teast" | awk '/t[ae]+st/{print $0}'$ echo "teeast" | awk '/t[ae]+st/{print $0}'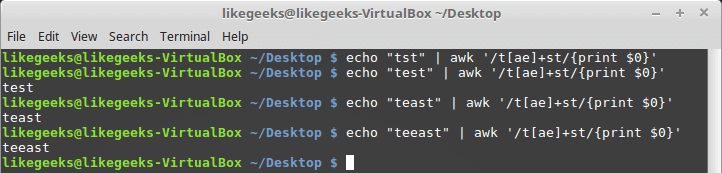
如果存在字符类中的任何字符,则成功。
大括号
花括号使你可以指定模式的存在数量,它有两种格式:
n:正则表达式正好出现 n 次。
n,m:正则表达式至少出现 n 次,但不超过 m 次。
$ echo "tst" | awk '/te{1}st/{print $0}'$ echo "test" | awk '/te{1}st/{print $0}'
在旧版本的 awk 中,你应该对 awk 命令使用 –re-interval 选项以使其读取花括号,但在新版本中,你不需要它。
$ echo "tst" | awk '/te{1,2}st/{print $0}'$ echo "test" | awk '/te{1,2}st/{print $0}'$ echo "teest" | awk '/te{1,2}st/{print $0}'$ echo "teeest" | awk '/te{1,2}st/{print $0}'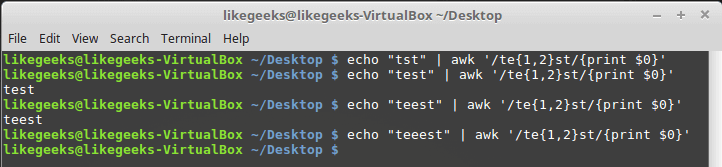
在这个例子中,如果“e”字符存在一两次,则成功;否则,它将失败。
你可以将它与这样的字符类一起使用:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}'$ echo "test" | awk '/t[ae]{1,2}st/{print $0}'$ echo "teest" | awk '/t[ae]{1,2}st/{print $0}'$ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'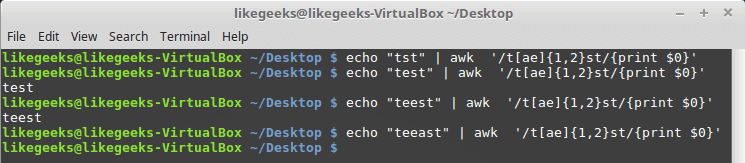
如果有一个或两个字母“a”或“e”的实例,则模式通过;否则,它将失败。
管道符号
管道符号在 2 个模式之间进行逻辑 OR。如果其中一种模式存在,则成功;否则,它会失败,这是一个例子:
$ echo "Testing regex" | awk '/regex|regular expressions/{print $0}'$ echo "Testing regular expressions" | awk '/regex|regular expressions/{print $0}'$ echo "This is something else" | awk '/regex|regular expressions/{print $0}'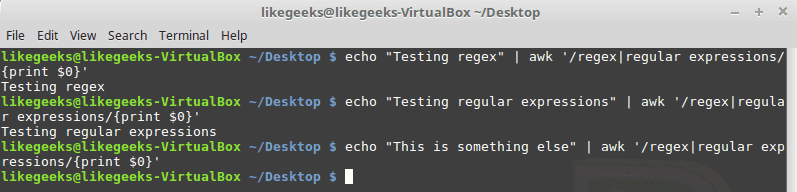
不要在模式和管道符号之间键入任何空格。
分组表达式
你可以对表达式进行分组,以便正则表达式引擎将它们视为一个整体。
$ echo "Like" | awk '/Like(Geeks)?/{print $0}'$ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
“Geeks”的分组使得正则表达式引擎将其视为一个整体,因此如果“LikeGeeks”或“Like”一词存在,则它成功。
Linix Shell正则表达式教程:实际例子
我们看到了一些使用正则表达式模式的简单演示。是时候付诸行动了,只是为了练习。
计算目录文件
让我们看一个 bash 脚本,它从 PATH环境变量中计算文件夹中的可执行文件。
$ echo $PATH要获得目录列表,你必须用空格替换每个冒号。
$ echo $PATH | sed 's/:/ /g'现在让我们使用 for 循环遍历每个目录,如下所示:
mypath=$(echo $PATH | sed 's/:/ /g')
for directory in $mypath; do
done你可以使用ls 命令获取每个目录上的文件并将其保存在变量中。
#!/bin/bash
path_dir=$(echo $PATH | sed 's/:/ /g')
total=0
for folder in $path_dir; do
files=$(ls $folder)
for file in $files; do
total=$(($total + 1))
done
echo "$folder - $total"
total=0
done你可能会注意到一些目录不存在,这没有问题,没关系。
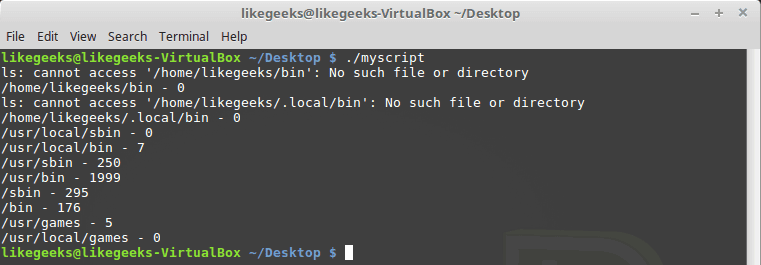
凉爽的!!这就是正则表达式的强大之处——这几行代码计算了所有目录中的所有文件。当然,有一个 Linux 命令可以很容易地做到这一点,但在这里我们讨论如何在你可以使用的东西上使用正则表达式。你可以提出一些更有用的想法。
Linix Shell如何使用正则表达式?验证电子邮件地址
有大量网站提供随时可用的正则表达式模式,包括电子邮件、电话号码等等,这很方便,但我们想了解它是如何工作的。
username@hostname.com
Linix Shell正则表达式用法实例:用户名可以使用任何字母数字字符与点、破折号、加号、下划线组合。
主机名可以使用与点和下划线组合的任何字母数字字符。
对于用户名,以下模式适合所有用户名:
^([a-zA-Z0-9_\-\.\+]+)@加号表示必须存在一个或多个字符,后跟 @ 符号。
那么主机名模式应该是这样的:
([a-zA-Z0-9_\-\.]+)TLD 或顶级域有特殊规则,它们必须不少于 2 和 5 个字符。以下是顶级域的正则表达式模式。
\.([a-zA-Z]{2,5})$现在我们把它们放在一起:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5 })$让我们针对电子邮件测试该正则表达式,Linux Sed和AWK示例:
$ echo " name@host.com " | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{ 2,5})$/{打印 $0}'$ echo " name@host.com.us " | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{ 2,5})$/{打印 $0}'
惊人的!!
这只是永无止境的正则表达式世界的开始。我希望你理解这些 ASCII 呕吐 🙂 并更专业地使用它。
我希望你喜欢这篇Linix Shell正则表达式教程,若有任何问题,请在下方评论和分享。
谢谢你。

