
Python怎么删除标点符号?如果你曾经处理过大量文本数据,你就会知道从文本中查找和删除不相关的单词或字符的痛苦。
手动完成这项工作,即使在现代文字处理器的帮助下,也可能既耗时又令人沮丧。
幸运的是,Python 等编程语言支持强大的文本处理库,本文讨论Python删除标点符号的方法,这可帮助我们高效地完成此类清理工作。
那么Python如何删除标点符号呢?在本教程中,我们将研究在 Python 中从文本中删除标点符号的各种方法以及相关的Python删除标点符号代码例子。
目录
- 为什么要去掉标点符号?
- 使用替换方法
- 使用 maketrans 和翻译
- 使用正则表达式
- 使用 nltk
- 仅从开头和结尾删除标点符号
- 删除标点符号和多余的空格
- 从文本文件中删除标点符号
- 删除除撇号以外的所有标点符号
- 性能比较
- 结论
为什么要去掉标点符号?
删除标点符号是许多数据分析和机器学习任务中常见的预处理步骤。
例如,如果你正在构建文本分类模型,或从给定的文本语料库构建词云,标点符号在此类任务中没有用处,因此我们在预处理步骤中将其删除。
如果你正在处理用户生成的文本数据,例如社交媒体帖子,你会在句子中遇到太多标点符号,这可能对手头的任务没有用,因此删除所有这些标点符号成为必不可少的预处理任务。
使用替换方法
Python 字符串带有许多有用的方法。一种这样的方法是替换方法。
使用此方法,你可以用另一个字符或子字符串替换给定字符串中的特定字符或子字符串。
让我们看一个例子。
s = "Hello World, Welcome to my blog."
print(s)
s1 = s.replace('W', 'V')
print(s1)输出:

默认情况下,此方法会从给定字符串中删除所有出现的给定字符或子字符串。
我们可以通过将“count”值作为第三个参数传递给 replace 方法来限制要替换的出现次数。
这是一个示例,我们首先使用 count(-1) 的默认值,然后为其传递自定义值。
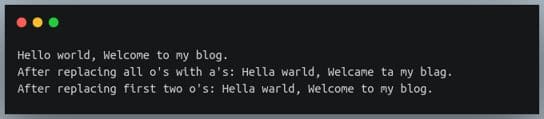
s = "Hello world, Welcome to my blog."
print(s)
s1 = s.replace('o', 'a')
print(f"After replacing all o's with a's: {s1}")
# replace only first 2 o's
s2 = s.replace('o', 'a', 2)
print(f"After replacing first two o's: {s2}")输出:
需要注意的是,在我们对 replace 方法的所有使用中,我们都将结果字符串存储在一个新变量中。
这是因为字符串是不可变的。与列表不同,我们不能就地修改它们。
因此,所有字符串修改方法都返回一个新的、修改过的字符串,我们将其存储在一个新变量中。
现在让我们弄清楚我们应该如何使用这个Python删除标点符号的方法来替换字符串中所有出现的标点符号。
我们必须首先定义一个列表,列出我们不感兴趣并想要摆脱的所有标点符号。
然后我们遍历这些标点符号中的每一个,并将其传递给对输入字符串调用的 replace 方法。
此外,由于我们要删除标点符号,因此我们传递一个空字符串作为第二个参数来替换它,Python删除标点符号代码例子:
user_comment = "NGL, i just loved the moviee...... excellent work !!!"
print(f"input string: {user_comment}")
clean_comment = user_comment #copy the string in new variable, we'll store the result in this variable
# define list of punctuation to be removed
punctuation = ['.','.','!']
# iteratively remove all occurrences of each punctuation in the input
for p in punctuation:
clean_comment = clean_comment.replace(p,'') #not specifying 3rd param, since we want to remove all occurrences
print(f"clean string: {clean_comment}")输出:

由于它是一个简短的文本,我们可以预见我们会遇到什么样的标点符号。
但是现实世界的输入可能跨越数千行文本,并且很难确定存在哪些标点符号并且需要删除。
但是,如果我们知道在英文文本中可能遇到的所有标点符号,我们的任务就会变得容易。
Python 的字符串类确实在属性 string.punctuation 中提供了所有标点符号。这是一串标点符号。
import string
all_punctuation = string.punctuation
print(f"All punctuation: {all_punctuation}")输出:

一旦我们将所有标点符号作为一个字符序列,我们就可以在任何文本输入上运行前面的 for 循环,无论文本输入多大,并且输出将没有标点符号。
使用 maketrans 和翻译
Python怎么删除标点符号?在 Python 中还有另一种方法,我们可以使用它根据需要将字符串中所有出现的字符替换为相应的等价物。
在这种方法中,我们首先使用 str.translate 创建一个“翻译表”。该表指定了字符之间的一对一映射。
然后我们将此转换表传递给对输入字符串调用的 translate 方法。
此方法返回一个修改后的字符串,其中原始字符被替换为翻译表中定义的替换字符。
让我们通过一个简单的例子来理解这一点。我们将所有出现的 'a' 替换为 'e','o' 替换为 'u','i' 替换为 'y'。
tr_table = str.maketrans('aoi', 'euy') #defining the translation table: a=>e, o=>u, i=>y
s = "i absolutely love the american ice-cream!"
print(f"Original string: {s}")
s1 = s.translate(tr_table) #or str.translate(s, tr_table)
print(f"Translated string: {s1}")输出:

在 maketrans 方法中,前两个字符串的长度需要相等,因为第一个字符串中的每个字符都对应于它在第二个字符串中的替换/翻译。
该方法接受一个可选的第三个字符串参数,指定需要映射到 None 的字符,这意味着它们没有替换,因此将被删除(这是我们需要删除标点符号的功能)。
我们还可以使用映射字典而不是两个字符串参数来创建转换表。
这还允许我们创建字符到字符串的映射,这有助于我们用字符串替换单个字符(这对于字符串参数是不可能的)。
字典方法还帮助我们明确地将任何字符映射到 None,指示需要删除这些字符。
让我们使用前面的示例并使用字典创建映射。
现在,我们还将映射 '!' 到无,这将导致从输入字符串中删除标点符号。
mappings = {
'a':'e',
'o':'u',
'i':'eye',
'!': None
}
tr_table = str.maketrans(mappings)
s = "i absolutely love the american ice-cream!"
print(f"Original string: {s}")
print(f"translation table: {tr_table}")
s1 = s.translate(tr_table) #or str.translate(s, tr_table)
print(f"Translated string: {s1}")输出:
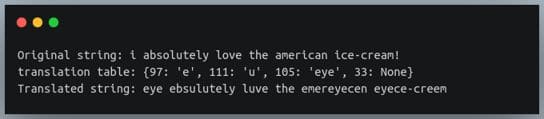
请注意,当我们打印转换表时,键是整数而不是字符。这些是我们在创建表时定义的字符的 Unicode 值。
最后,让我们使用这种Python删除标点符号的方法从给定的输入文本中删除所有出现的标点符号。
import string
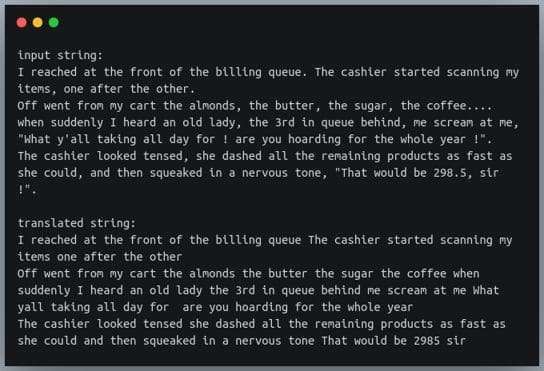
s = """I reached at the front of the billing queue. The cashier started scanning my items, one after the other.
Off went from my cart the almonds, the butter, the sugar, the coffee.... when suddenly I heard an old lady, the 3rd in queue behind me, scream at me, "What y'all taking all day for ! are you hoarding for the whole year !".
The cashier looked tensed, she dashed all the remaining products as fast as she could, and then squeaked in a nervous tone, "That would be 298.5, sir !"."""
print(f"input string:\n{s}\n")
tr_table = str.maketrans("","", string.punctuation)
s1 = s.translate(tr_table)
print(f"translated string:\n{s1}\n")输出:
使用正则表达式
Python如何删除标点符号?RegEx 或正则表达式是表示字符串模式的字符序列。
在文本处理中,它用于查找、替换或删除与正则表达式定义的模式匹配的所有此类子字符串。
Python删除标点符号代码例子。正则表达式“\d{10}”用于表示10位数字,或者正则表达式“[AZ]{3}”用于表示任何3个字母(大写)的代码。让我们用它从一个句子中找出国家代码。
import re
# define regex pattern for 3-lettered country codes.
c_pattern = re.compile("[A-Z]{3}")
s = "At the Olympics, the code for Japan is JPN, and that of Brazil is BRA. RSA stands for the 'Republic of South Africa' while ARG for Argentina."
print(f"Input: {s}")
# find all substrings matching the above regex
countries = re.findall(c_pattern, s)
print(f"Countries fetched: {countries}")输出:
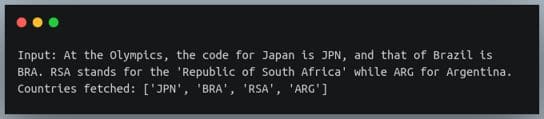
在我们定义的正则表达式的帮助下,所有出现的 3 字母大写代码都已被识别。
如果我们想用某些东西替换字符串中所有匹配的模式,我们可以使用 re.sub 方法来实现。
让我们尝试用前面示例中的默认代码“DEF”替换所有出现的国家/地区代码。
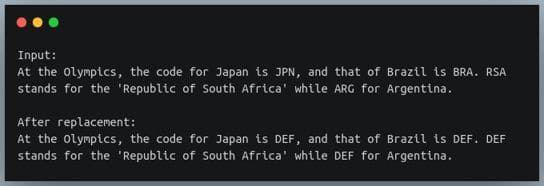
c_pattern = re.compile("[A-Z]{3}")
s = "At the Olympics, the code for Japan is JPN, and that of Brazil is BRA. RSA stands for the 'Republic of South Africa' while ARG for Argentina.\n"
print(f"Input:\n{s}")
new_s = re.sub(c_pattern, "DEF", s)
print(f"After replacement:\n{new_s}")输出:
我们可以使用相同的方法用空字符串替换所有出现的标点符号。这将有效地从输入字符串中删除所有标点符号。
但首先,我们需要定义一个代表所有标点符号的正则表达式模式。
虽然标点符号不存在任何特殊字符,比如数字 \d,但我们可以明确定义我们想要替换的所有标点符号,
或者我们可以定义一个正则表达式来排除我们想要的所有字符保留。
例如,如果我们知道我们只能期待英文字母、数字和空格,那么我们可以使用插入符号 ^ 在我们的正则表达式中排除它们。
默认情况下,其他所有内容都将被匹配和替换。
让我们以两种方式定义它。
import string, re
p_punct1 = re.compile(f"[{string.punctuation}]") #trivial way of regex for punctuation
print(f"regex 1 for punctuation: {p_punct1}")
p_punct2 = re.compile("[^\w\s]") #definition by exclusion
print(f"regex 2 for punctuation: {p_punct2}")输出:

现在让我们使用它们来替换句子中的所有标点符号。我们将使用包含各种标点符号的较早的句子。
import string
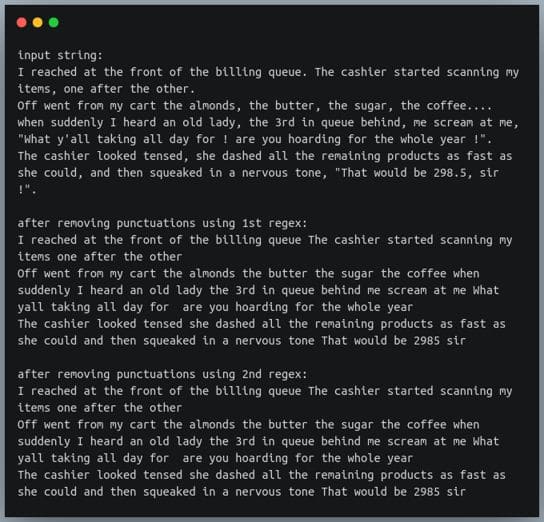
s = """I reached at the front of the billing queue. The cashier started scanning my items, one after the other.
Off went from my cart the almonds, the butter, the sugar, the coffee.... when suddenly I heard an old lady, the 3rd in queue behind me, scream at me, "What y'all taking all day for ! are you hoarding for the whole year !".
The cashier looked tensed, she dashed all the remaining products as fast as she could, and then squeaked in a nervous tone, "That would be 298.5, sir !"."""
print(f"input string:\n{s}\n")
s1 = re.sub(p_punct1, "", s)
print(f"after removing punctuation using 1st regex:\n{s1}\n")
s2 = re.sub(p_punct2, "", s)
print(f"after removing punctuation using 2nd regex:\n{s2}\n")输出:
它们都产生了彼此相同的结果,并且与我们之前使用的 maketrans 方法相同。
使用 nltk
Python 的 nltk是一个流行的开源 NLP 库。它提供了大量的语言数据集、文本处理模块以及 NLP 所需的许多其他功能。
nltk 有一个叫做 word_tokenize 的方法,用于将输入的句子分解为单词列表。这是任何 NLP 管道的第一步。
让我们看一个Python删除标点符号代码例子。
import nltk
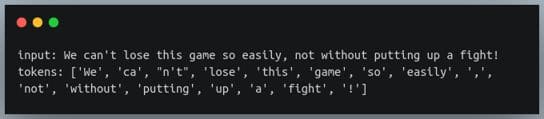
s = "We can't lose this game so easily, not without putting up a fight!"
tokens = nltk.word_tokenize(s)
print(f"input: {s}")
print(f"tokens: {tokens}")输出:
nltk 使用的默认标记器保留标点符号并根据空格和标点符号拆分标记。
我们可以使用 nltk 的 RegexpTokenizer 来指定使用正则表达式的令牌模式。
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("\w+") #\w+ matches alphanumeric characters a-z,A-Z,0-9 and _
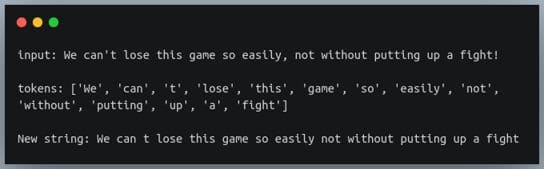
s = "We can't lose this game so easily, not without putting up a fight!"
tokens = tokenizer.tokenize(s)
print(f"input: {s}\n")
print(f"tokens: {tokens}\n")
new_s = " ".join(tokens)
print(f"New string: {new_s}\n")输出:
仅从开头和结尾删除标点符号
Python怎么删除标点符号?如果我们只想删除句子开头和结尾的标点符号,而不是中间的标点符号,我们可以定义一个表示这种模式的正则表达式,并使用它来删除开头和结尾的标点符号。
让我们首先在示例中使用一个这样的正则表达式,然后我们将深入研究该正则表达式。
import re
pattern = re.compile("(^[^\w\s]+)|([^\w\s]+$)")
sentence = '"I am going to be the best player in history!"'
print(sentence)
print(re.sub(pattern,"", sentence))输出:
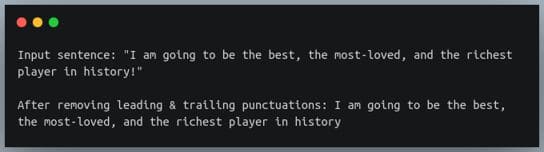
输出显示开头和结尾的引号 (") 以及倒数第二个位置的感叹号 (!) 已被删除。
另一方面,单词之间出现的标点符号被保留。
用于实现此目的的正则表达式是 (^[^\w\s]+)|([^\w\s]+$)
Python删除标点符号的方法:此正则表达式中有两种不同的模式,每种模式都用括号括起来并用 OR 符号 (|) 分隔。这意味着,如果字符串中存在两种模式中的任何一种,它将由给定的正则表达式标识。
正则表达式的第一部分是“^[^\w\s]+”。这里有两个脱字符 (^),一个在方括号内,另一个在方括号外。
第一个脱字符,即方括号前面的那个,告诉正则表达式编译器“匹配出现在句子开头的任何子字符串并匹配以下模式”。
方括号定义了一组要匹配的字符。
方括号内的插入符号告诉编译器“匹配除 \w 和 \s 之外的所有内容”。\w 代表字母数字字符,\s 代表空格。
因此,除了字母数字字符和空格(本质上是标点符号)之外,开头的所有内容都将由正则表达式的第一部分表示。
第二个组件与第一个组件几乎相似,不同之处在于它匹配出现在字符串末尾的指定字符集。这由尾随字符 $ 表示。
删除标点符号和多余的空格
除了去除标点符号,去除多余的空格也是一个常见的预处理步骤。
删除多余的空格不需要使用任何正则表达式或 nltk 方法。Python 字符串的 strip 方法用于删除任何前导或尾随空白字符。
s = " I have an idea! \t "
print(f"input string with white spaces = {s}, length = {len(s)}\n")
s1 = s.strip()
print(f"after removing spaces from both ends: {s1}, length = {len(s1)}")输出:
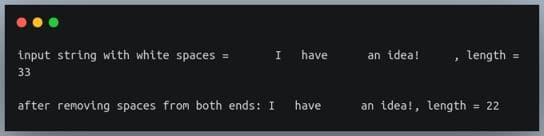
strip 方法仅删除字符串开头和结尾的空格。
我们还想删除单词之间的多余空格。
这两种方法都可以通过使用 split 方法拆分字符串,然后使用单个空格“”连接它们来实现。
让我们在一个Python删除标点符号代码例子中结合去除标点符号和额外空格。
import string
tr_table = str.maketrans("","", string.punctuation) # for removing punctuation
s = ' " I am going to be the best,\t the most-loved, and... the richest player in history! " '
print(f"Original string:\n{s},length = {len(s)}\n")
s = s.translate(tr_table)
print(f"After removing punctuation:\n{s},length = {len(s)}\n")
s = " ".join(s.split())
print(f"After removing extra spaces:\n{s},length = {len(s)}")输出:
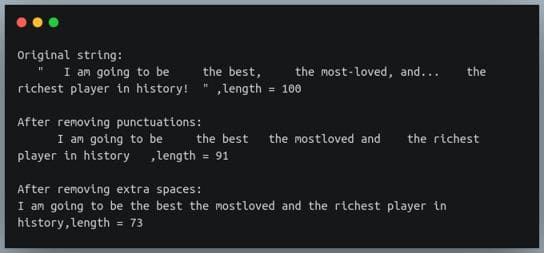
从文本文件中删除标点符号
Python如何删除标点符号?到目前为止,我们一直在研究存储在 str 类型变量中并且不超过 2-3 个句子的短字符串。
但在现实世界中,实际数据可能存储在磁盘上的大文件中。
在本节中,我们将研究如何从文本文件中删除标点符号。
首先,让我们在字符串变量中读取文件的全部内容,并在将其写入新文件之前使用我们之前的方法之一从该内容字符串中删除标点符号。
import re
punct = re.compile("[^\w\s]")
input_file = "short_sample.txt"
output_file = "short_sample_processed.txt"
f = open(input_file)
file_content = f.read() #reading entire file content as string
print(f"File content: {file_content}\n")
new_file_content = re.sub(punct, "", file_content)
print(f"New file content: {new_file_content}\n")
# writing it to new file
with open(output_file, "w") as fw:
fw.write(new_file_content)输出:
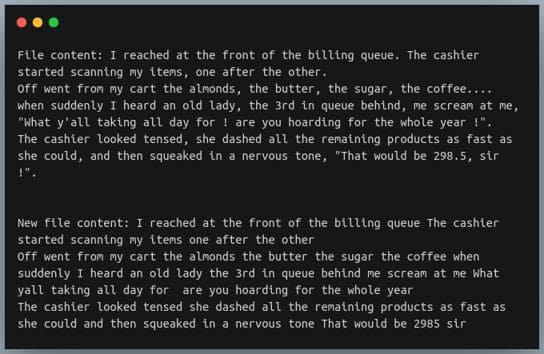
Python怎么删除标点符号?在上面的例子中,我们一次读取了整个文件。然而,文本文件也可能跨越数百万行的内容,达到几百 MB 或几 GB。
在这种情况下,一次读取整个文件没有意义,因为这可能导致潜在的内存过载错误。
因此,我们将一次一行读取文本文件,对其进行处理,然后将其写入新文件。
迭代地执行此操作不会导致内存过载,但是,它可能会增加一些开销,因为重复的输入/输出操作成本更高。
在下面的删除标点符号代码例子中,我们将从一个文本文件(在这里找到)中删除标点符号,这是一个关于“三头金毛的魔鬼”的故事!
import re
punct = re.compile("[^\w\s]")
input_file = "the devil with three golden hairs.txt"
output_file = "the devil with three golden hairs_processed.txt"
f_reader = open(input_file)
# writing it to new file
with open(output_file, "w") as f_writer:
for line in f_reader:
line = line.strip() #removing whitespace at ends
line = re.sub(punct, "",line) #removing punctuation
line += "\n"
f_writer.write(line)
print(f"First 10 lines of original file:")
with open(input_file) as f:
i = 0
for line in f:
print(line,end="")
i+=1
if i==10:
break
print(f"\nFirst 10 lines of output file:")
with open(output_file) as f:
i = 0
for line in f:
print(line,end="")
i+=1
if i==10:
break输出:
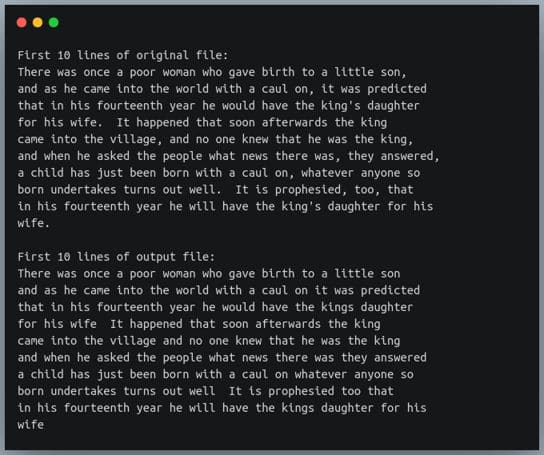
从前 10 行可以看出,标点符号已从输入文件中删除,结果存储在输出文件中。
删除除撇号以外的所有标点符号
撇号在英语中具有语义含义。它们用于显示所有格名词,通过省略字母来缩短单词(例如,不能=不能,不会=不会)等。
因此在处理文本时保留撇号字符以避免丢失这些语义含义变得很重要。
让我们从文本中删除除撇号之外的所有标点符号。
s=""""I should like to have three golden hairs from the devil's head",
answered he, "else I cannot keep my wife".
No sooner had he entered than he noticed that the air was not pure. "I smell man's
flesh", said he, "all is not right here".
The queen, when she had received the letter and read it, did as was written in it, and had a splendid wedding-feast
prepared, and the king's daughter was married to the child of good fortune, and as the youth was handsome and friendly she lived
with him in joy and contentment."""
print(f"Input text:\n{s}\n")
tr_table = str.maketrans("","", string.punctuation)
del tr_table[ord("'")] #deleting ' from translation table
print(f"Removing punctuation except apostrophe:\n{s.translate(tr_table)}\n")输出:
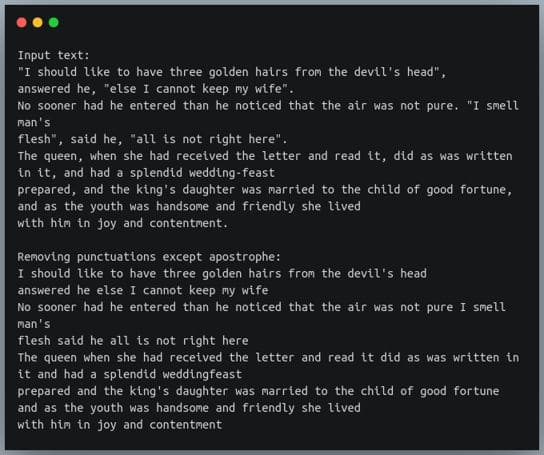
转换表是一个字典,其键是整数值。它们是字符的 Unicode 等价物。
ord 方法返回任何字符的 Unicode。我们使用它从翻译表中删除撇号字符的 Unicode。
性能比较
既然我们已经看到了在 Python 中去除标点符号的许多不同方法,让我们从它们的时间消耗方面来比较它们。
我们将比较 replace、maketrans、regex 和 nltk 的性能。
我们将使用 tqdm 模块来衡量每种方法的性能。
我们将每个方法运行 100000 次。
每次,我们都会生成一个包含 1000 个字符(az、AZ、0-9 和标点符号)的随机字符串,并使用我们的方法从中删除标点符号。
输出:
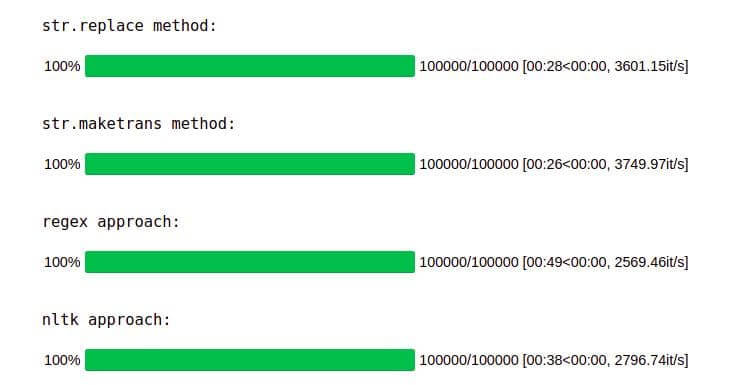
str.maketrans 方法与 str.translate 结合使用是最快的方法,完成 100000 次迭代需要 26 秒。
str.replace 紧随其后,耗时 28 秒完成任务。
最慢的方法是使用 nltk 的标记器。
Python删除标点符号代码总结
Python如何删除标点符号?在本教程中,我们查看并分析了从文本数据中删除标点符号的各种Python删除标点符号的方法。
我们首先查看 str.replace 方法。然后,我们看到了使用转换表将某些字符替换为其他字符或 None。
然后我们使用强大的正则表达式来匹配字符串中的所有标点并删除它们。
接下来,我们查看了一个名为 nltk 的流行 NLP 库,并使用其一种名为 word_tokenize 的文本预处理方法和默认标记器从输入字符串中获取标记。我们还为我们的特定用例使用了 RegexpTokenizer。
Python怎么删除标点符号?我们还看到了如何仅从字符串的开头和结尾删除标点符号。
我们不仅删除了标点符号,还删除了两端以及给定文本中单词之间的额外空格。
我们还看到了如何在从输入文本中删除所有其他标点符号的同时保留撇号。
我们看到了如何从存储在外部文本文件中的任意长度的文本中删除标点符号,并将处理后的文本写入另一个文本文件中。
最后,我们比较了从字符串中删除标点符号的 4 种突出方法的性能。

