
Python连接hive教程:Apache Hive 是 Hadoop 分布式文件系统 (HDFS) 之上的数据库框架,用于查询结构化和半结构化数据。就像你的常规 RDBMS 一样,你以表格的形式访问 hdfs 文件。你可以在 Apache Hive 中创建表、视图等。你可以使用类似于结构查询语言 (SQL) 的 HiveQL 语言分析结构化数据。Python如何连接hive数据库?在本文中,我们将检查从 python程序访问 Hive 表的不同方法。我们将在此处讨论Python连接hive的方法将帮助你连接 Hive 表并获取分析所需的数据。
从 Python连接Hive数据库的方法
以下是从python程序连接到Hive的常用方法:
- 从 Python 执行 Beeline 命令。
- 使用 PyHive 连接到 Hive。
- 使用 Hive JDBC 驱动程序连接到远程 Hiveserver2。
现在,让我们详细检查这些方法;
从 Python 执行Beeline命令
Beeline 是连接 Hive 的最新命令行界面。你可以使用 beeline 连接到嵌入式(本地)Hive 或远程 Hive。Beeline 命令适用于 Kerberos 身份验证的 Hive 集群。
你可以在Beeline shell 中运行特定于配置单元的命令,例如Apache Hive 命令选项。就像在 Hive 命令选项中一样,你可以使用“;”终止 Hive 命令 (分号)。在本文中,我们将 通过一些示例检查Beeline Hive 命令选项。
Python连接hive数据库:Beeline Hive 命令选项
以下是 Beeline 支持的 Hive 命令选项:
| 命令 | 描述 |
| set <key>=<value> | 设置配置变量(键)的值。 |
| set -v | 此命令打印所有使用的 Hadoop 和 Hive 配置变量。 |
| set | 此命令打印由用户或 Hive 覆盖的配置变量列表。 |
| reset | 此命令将系统配置重置为默认值。 |
| reload | 这使 Hiveserver2 知道 hive.reloadable.aux.jars.path 中指定的 jar 文件更改(添加、删除或更新)。此选项在 Hive 0.14.0 以后可用。 |
| list FILE[S] list JAR[S] list ARCHIVE[S] | 使用它来列出已经添加到分布式缓存中的资源。 |
| list FILE[S] * list JAR[S] * list ARCHIVE[S] * | 使用它来检查给定的资源是否已经添加到分布式缓存中。 |
| dfs <dfs command> | 执行 dfs 命令。 |
| delete FILE[S] * delete JAR[S] * delete ARCHIVE[S] * | 从分布式缓存中移除使用 <ivyurl> 添加的资源。 |
| delete FILE[S] * delete JAR[S] * delete ARCHIVE[S] * | 从分布式缓存中移除资源。 |
| add FILE[S] * add JAR[S] * add ARCHIVE[S] * | 使用 ivy://group:module:version?query_string 形式的 Ivy URL 将文件、jar 或存档添加到分布式缓存中的资源列表。 |
| add FILE[S] * add JAR[S] * add ARCHIVE[S] * | 将一个或多个文件、jar 或存档添加到分布式缓存中的资源列表中。 |
| <query string> | 执行 Hive 查询并将结果打印到标准输出。 |
Python连接hive教程:Beeline Hive 命令选项示例
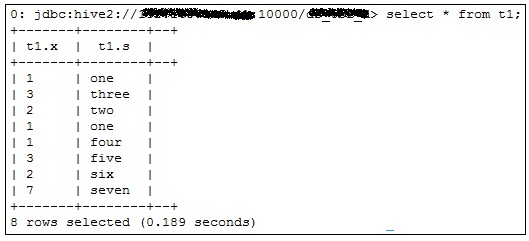
在 Beeline shell 上执行 Hive 查询:
https://gist.github.com/19a89e43ff56e093dfa930f352b6f9b4
你可以按照以下帖子中给出的步骤从 Python 程序执行Beeline命令:
要执行任何分析,你需要准备好数据。要收集数据,你可能必须将应用程序连接到不同的数据源。在本文中,我们将讨论从 Python应用程序执行 Hive Beeline JDBC 字符串命令的一种方法。这是使用 Beeline shell 连接到 Kerberos HiveServer2 的一种简单易行的方法。
我正在从事机器学习项目之一,以预测 Hadoop Hive 集群上的查询执行时间。我们从 HiveQL 查询计划中收集了各种功能。为了获得计划,我们有使用 beeline JDBC 连接字符串连接到 Hive 的应用程序,并获取该查询所需的解释计划并将该字符串存储到 Python 变量中。我们再次在预处理步骤中使用该字符串。
在详细介绍之前,让我们先了解一下 Hive Beeline 是什么?
什么是Beeline命令?
Hive Beeline是一个基于SQLLine CL的JDBC 客户端。该客户端用于连接 HiveServer2。Beeline shell 可以在嵌入模式和远程模式下工作。在嵌入式模式下,它运行嵌入式 Hive,而远程模式用于连接到单独的 HiveServer2 进程。你甚至可以连接到具有 Kerberos 身份验证机制的 HiveServer2。
从 Python 执行 Hive Beeline JDBC 字符串命令
Python如何连接hive?现在,我们知道 Hive Beeline 是什么,现在让我们尝试将该 Beeline 连接到 Kerberized Hive 集群,而无需任何外部软件包,例如Pyhs2、impyla 或Pyhive。
Python连接hive的方法:以下是你要查找的脚本示例:
import commands
import re
query = 'explain select * from date_dim limit 1'
host=str('192.168.0.100')
port=str('10000')
authMechanism=str('KERBEROS')
database=str('store')
principal=str('hive/system1.example.co.in@EXAMPLE.CO.IN')
result_string= 'beeline -u "jdbc:hive2://"'+host +'":"'+port+'"/"'+database+'";principal="'+principal+'"" ' \
'--fastConnect=true --showHeader=false --verbose=false --showWarnings=false --silent=true -n user1 -p ' \
'passwd -e "' + query + ';"'
status, output = commands.getstatusoutput(result_string)
if status == 0:
return output
else:
print "Error encountered while executing HiveQL queries."该脚本使用 Python 命令模块来执行命令并将结果放入 Python 变量中。
Python如何连接hive?使用 PyHive 连接到 Hive
还有许多其他 Python 包可用于连接到远程 Hive。Pyhive 软件包是当今可用的简单、维护良好且受支持的软件包之一。Pyhive 主要是为了连接到远程 HiveServer2 而创建的。
数据在每个决策过程中都发挥着重要作用。你可能必须连接到各种远程服务器才能获取应用程序所需的数据。本文解释了如何使用常用的 Python 包 Pyhive连接运行在远程主机(HiveSever2)上的 Hive。在本Python连接hive数据库教程中,我们将查看使用 Python Pyhive 连接 HiveServer2 的分步指南。
还有许多其他 Python 包可用于连接到远程 Hive,但 Pyhive 包是简单且维护良好且受支持的包之一。
有一个选项可以连接到 Hive 直线,而无需任何包,例如 Pyhive、Pyhs2 或 imyla。在 从 Python 执行 Hive Beeline JDBC 字符串命令中阅读更多信息。
请注意,所有步骤和代码段都在 Ubuntu 14.04 上进行了测试。
什么是 Pyhive?
在详细介绍如何使用 Pyhive 包访问 HiveServer2 之前,让我们了解什么是 Pyhive?
PyHive 是使用 Python DB-API 和 SQLAlchemy 接口的集合编写 的 Presto 和 Hive。你可以使用此包执行基本的 Hive 操作,例如从表中读取数据、执行 Hive 查询。
你可以关注官方Pyhive页面以获取更多信息。
Python连接hive教程:安装 Pyhive 的分步指南
以下是在 Ubuntu 机器上安装 Pyhive 的步骤:
第一步:安装依赖模块
在尝试安装 Pyhive 之前,你必须安装 Pyhive 所依赖的软件包。
以下是 Pyhive 所需的软件包:
安装 gcc
sudo apt-get install gcc安装thrift
pip install thrift+安装 SASL
pip install sasl如果在安装 sasl 时出现错误,请按照下面的Pyhive sasl 错误部分安装依赖项。
安装 thrift sasl
pip install thrift_sasl安装 Pyhive
成功安装上述所有软件包后,你可以继续使用 pip 安装 Pyhive:
pip install pyhivePyhive sasl 错误——致命错误:sasl/sasl.h
如果你是第一次配置,那么在安装 sasl 模块时很可能会出现 sasl.h 错误。安装libsasl2-dev模块以消除错误。
sudo apt-get install libsasl2-dev第二步:使用Python Pyhive连接HiveServer2
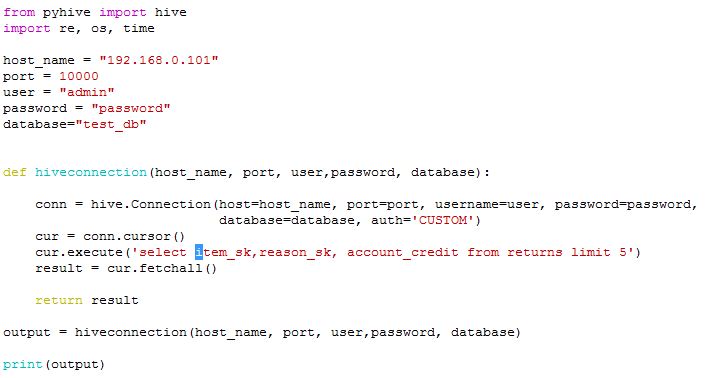
Python如何连接hive?现在你已准备好使用 Pyhive 模块连接到 HiveServer2。以下是你可以使用的示例代码:
从 pyhive 导入配置单元
host_name = "192.168.0.38"
port = 10000
user = "admin"
password = "password"
database="test_db"
def hiveconnection(host_name, port, user,password, database):
conn = hive.Connection(host=host_name, port=port, username=user, password=password,
database=database, auth='CUSTOM')
cur = conn.cursor()
cur.execute('select item_sk,reason_sk, account_credit from returns limit 5')
result = cur.fetchall()
return result
# Call above function
output = hiveconnection(host_name, port, user,password, database)
print(output)第 3 步:执行 Python 脚本以从远程 Hive 服务器获取结果
如果一切正常,你将看到如下结果。
$ python hivePython.py
[(1119, 27, '827.06'), (5, None, '50.12'), (907, 5, '231.12'), (21, None, '134.18'), (579, 12, '5.58')]Python连接hive的方法:使用 Hive JDBC 驱动程序连接到远程 Hiveserver2
Python连接hive数据库 - HiveServer2 有一个 JDBC 驱动程序,它支持对 HiveServer2 的嵌入式和远程访问。使用 Python Jaydebeapi 包从 Python 程序连接到远程 HiveServer2。
请注意,有两个版本的 Jaydebeapi 可用:用于 Python 2 的 Jaydebeapi 和用于 Python3 的 Jaydebeapi3。
Python如何连接hive?按照以下帖子中给出的步骤将 Hive JDBC 驱动程序与 Python 程序一起使用:
HiveServer2 有一个 JDBC 驱动程序,它支持对 HiveServer2 的嵌入式和远程访问。通常,建议将远程 HiveServer2 用于生产环境,因为它不需要为 Hive 用户提供直接的 Metastore 或 HDFS 访问权限。在本文中,我们将检查使用 Hive JDBC Drivers 从 Python 连接 HiveServer2 的步骤 。
使用 Hive JDBC 驱动程序从 Python 连接 HiveServer2 的步骤
Python连接hive教程:Hive JDBC 驱动程序是连接到 HiveServer2 的广泛使用的方法之一。你可以将 Hive JDBC 与 Python Jaydebeapi 开源模块一起使用。
请注意,本文仅关注连接到启用了KERBEROS 身份验证的HiveServer2 。
还有各种其他方法可以从 Python 连接到 HiveServer2。
例如,
- 你可以从 Python 执行 Hive Beeline JDBC string 命令。
- 你可以使用 Python Pyhive 包连接到 HiveServer2。
安装 Jaydebeapi
该JayDeBeApi模块可让你从Python代码连接到使用Java JDBC数据库。它为该数据库提供了 Python DB-API v2.0。
你可以使用 pip 安装它:
pip install Jaydebeapi将 CLASSPATH 设置为驱动程序位置
Hive JDBC 驱动程序依赖于许多其他 jar。你可以下载它们或简单地将 Hadoop-client 和 Hive-client 路径设置为 CLASSPATH shell 环境变量。
export CLASSPATH=$CLASSPATH:$(hadoop classpath):/usr/hdp/current/hadoop-client/*:/usr/hdp/current/hive-client/lib/*:/usr/hdp/current/hadoop-client/client/*从你的 Linux 边缘节点执行上述命令。如果你尝试执行窗体窗口,那么你可能需要设置用户特定的环境变量。
请注意,如果你没有所有必需的 jar 文件,jaydebeapi 模块将无法工作。
创建 Kerberos 票证
在连接到 Hive 服务器之前,你必须创建 Kerberos 票证。你可以使用knit 命令和 keytab 文件来创建票证。你当地的 Hadoop 管理员可以在这方面为你提供帮助。
Python连接hive的方法:使用 JDBC 驱动程序连接 HiveServer 2
现在你已准备好连接到 Hivesever2。使用klist 命令验证是否已创建票证。
Python连接hive数据库:下面是你可以使用 Hive JDBC 驱动程序从 Python 连接 HiveServer2 的代码:
import jaydebeapi
database='testtdb'
driver='org.apache.hive.jdbc.HiveDriver'
server='192.168.200.100'
principal='hive/example.domain.com@DOMAIN.COM.'
port=10000
# JDBC connection string
url=("jdbc:hive2://" + server + ":" + str(port)
+ "/"+ database +";principal=" + principal + ";")
#Connect to HiveServer2
conn=jaydebeapi.connect("org.apache.hive.jdbc.HiveDriver", url)
cursor = conn.cursor()
# Execute SQL query
sql="select * from item limit 10"
cursor.execute(sql)
results = cursor.fetchall()
print results下面是输出:
$ python hive_jdbc_conn.py
18/09/21 12:41:25 INFO jdbc.Utils: Supplied authorities: 192.168.200.100:10000
18/09/21 12:41:25 INFO jdbc.Utils: Resolved authority: 192.168.200.100:10000
18/09/21 12:41:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[(1537513919L,)]希望这可以帮助。如果你找到更好的方法,请告诉我
Python如何连接hive?使用 Pyhs2 包连接到 HiveServer2
pyHS2 是用于连接到 hive 服务器 2 的 python 客户端驱动程序
请注意,不维护 Pyhs2 包。最后一个版本是在 2014 年发布的。
pyHS2 是用于连接到 hive 服务器 2 的 python 客户端驱动程序。
更多详情请参考官方文档:Pyhs2
希望这个Python连接hive教程可以帮助到你。如果你使用任何其他方法,请告诉我。

