
先决条件: 决策树分类器
极随机树分类器(额外树分类器)是一种整体学习技术, 可将在"森林"中收集的多个不相关的决策树的结果进行汇总, 以输出其分类结果。从概念上讲, 它与随机森林分类器非常相似, 唯一的区别在于森林中决策树的构建方式。
Extra Trees Forest中的每个决策树都是根据原始训练样本构建的。然后, 在每个测试节点处, 为每棵树提供来自特征集中的k个特征的随机样本, 每个决策树都必须从该样本中选择最佳特征以基于一些数学标准(通常是基尼系数)分割数据。特征的这种随机样本导致创建多个不相关的决策树。
为了使用上述森林结构执行特征选择, 在森林的构建过程中, 对于每个特征, 在决定分割特征时使用的数学标准的归一化总缩减量(如果在构建时使用基尼指数, 则使用基尼指数)森林)。此值称为功能的基尼重要性。为了执行特征选择, 每个特征根据每个特征的基尼重要性按降序排列, 并且用户根据他/她的选择选择前k个特征。
考虑以下数据:
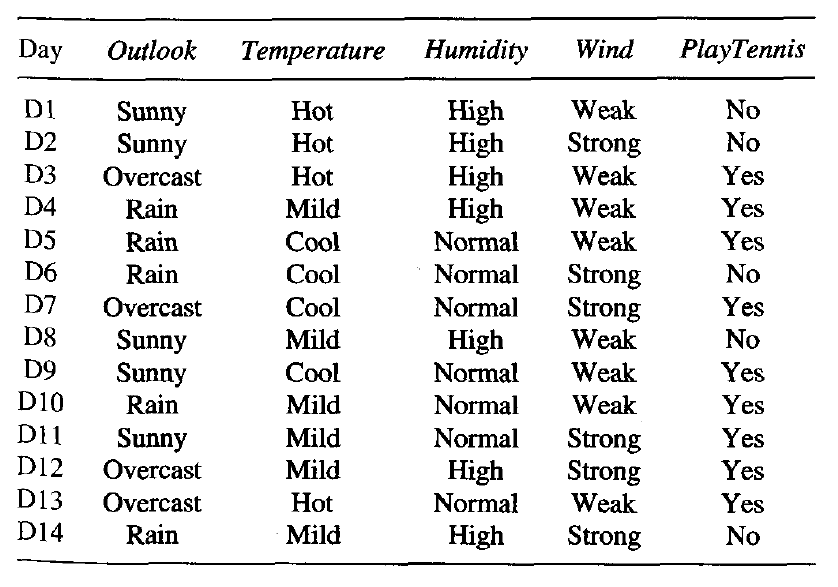
让我们为上面的数据建立一个假设的Extra Trees Forest五棵决策树决定特征随机样本中特征数量的k值为二。这里使用的决策标准将是信息增益。首先, 我们计算数据的熵。请注意, 用于计算熵的公式为:
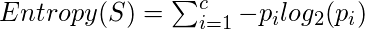
其中c是唯一类标签的数量, 而
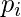
是带有输出标签的行的比例是i。
因此, 对于给定的数据, 熵是:-
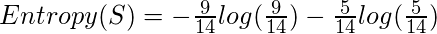
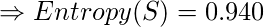
让决策树的结构如下:
1st Decision Tree获取具有Outlook和Temperature功能的数据:
请注意, 信息增益的公式为:
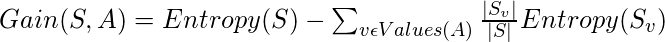
从而,
类似地:
第二决策树获取具有温度和风特征的数据:
使用上述公式:
strong>第三决策树获取具有Outlook和Humidity功能的数据:
4th决策树获取具有温度和湿度特征的数据:
5th决策树获取具有以下特征的数据:风和湿:
计算每个功能的总信息增益:
Total Info Gain for Outlook = 0.246+0.246 = 0.492
Total Info Gain for Temperature = 0.029+0.029+0.029 = 0.087
Total Info Gain for Humidity = 0.151+0.151+0.151 = 0.453
Total Info Gain for Wind = 0.048+0.048 = 0.096因此, 根据上述构造的Extra Trees Forest确定输出标签的最重要变量是" Outlook"要素。
下面给出的代码将演示如何使用Extra Trees Classifiers进行特征选择。
步骤1:导入所需的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import ExtraTreesClassifier步骤2:加载和清理数据
# Changing the working location to the location of the file
cd C:\Users\Dev\Desktop\Kaggle
# Loading the data
df = pd.read_csv( 'data.csv' )
# Separating the dependent and independent variables
y = df[ 'Play Tennis' ]
X = df.drop( 'Play Tennis' , axis = 1 )
X.head()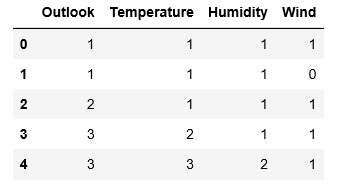
步骤3:建立Extra Trees Forest并计算个别功能的重要性
# Building the model
extra_tree_forest = ExtraTreesClassifier(n_estimators = 5 , criterion = 'entropy' , max_features = 2 )
# Training the model
extra_tree_forest.fit(X, y)
# Computing the importance of each feature
feature_importance = extra_tree_forest.feature_importances_
# Normalizing the individual importances
feature_importance_normalized = np.std([tree.feature_importances_ for tree in
extra_tree_forest.estimators_], axis = 0 )步骤4:可视化和比较结果
# Plotting a Bar Graph to compare the models
plt.bar(X.columns, feature_importance_normalized)
plt.xlabel( 'Feature Labels' )
plt.ylabel( 'Feature Importances' )
plt.title( 'Comparison of different Feature Importances' )
plt.show()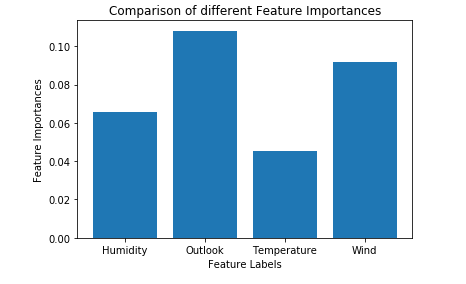
因此, 上述输出验证了我们使用Extra Trees Classifier进行特征选择的理论。由于特征样本的随机性, 特征的重要性可能具有不同的值。
首先, 你的面试准备可通过以下方式增强你的数据结构概念:Python DS课程。

