
Hibernate 是一个基于 Java 的持久性框架和一个对象关系映射 (ORM)框架,它基本上允许开发人员将 POJO(普通的旧 Java 对象)映射到关系数据库表。
Hibernate 框架的目标是将开发人员从与常见数据持久化相关的复杂配置和任务中解放出来。它通过将 POJO 对象有效地映射到数据库表来实现这一点,最重要的是以一种抽象的方式。
开发人员不需要知道所涉及的潜在复杂性。与抽象一起,查询可以以非常有效的方式执行。所有这些都有助于开发人员节省大量参与开发的时间。
Top 我们将引导你完成最重要的问题,让你为 Hibernate 面试做好准备。本文将涵盖基本、中级和高级问题。
基本的Hibernate常见面试题和答案合集
1. Hibernate 中的 ORM 是什么?
Hibernate面试题解析:Hibernate ORM代表对象关系映射。这是一种映射工具模式,主要用于将存储在关系数据库中的数据转换为面向对象编程构造中使用的对象。该工具还极大地有助于简化数据检索、创建和操作。
2、Hibernate常见的面试题有哪些:Hibernate相比JDBC有什么优势?
- Hibernate 相对于 JDBC 的优点如下:
- 清晰可读的代码:使用 hibernate 有助于消除大量基于 JDBC API 的样板代码,从而使代码看起来更清晰可读。
- HQL(Hibernate Query Language): Hibernate 提供的 HQL 更接近 Java,本质上是面向对象的。这有助于减轻开发人员编写独立于数据库的查询的负担。在 JDBC 中,情况并非如此。开发人员必须知道特定于数据库的代码。
- 事务管理: JDBC 不支持隐式事务管理。开发人员可以使用提交和回滚方法编写事务管理代码。而 Hibernate 隐式提供了此功能。
- 异常处理: Hibernate 包装 JDBC 异常并抛出未经检查的异常,如 JDBCException 或 HibernateException。这与内置的事务管理系统一起帮助开发人员避免编写多个 try-catch 块来处理异常。在 JDBC 的情况下,它抛出一个名为 SQLException 的已检查异常,从而要求开发人员编写 try-catch 块来在编译时处理此异常。
- 特殊功能: Hibernate 支持 OOP 功能,如继承、关联,还支持集合。这些在 JDBC 中不可用。
3、Hibernate框架有哪些重要的接口?
Hibernate 的核心接口是:
- Configuration
- SessionFactory
- Session
- Criteria
- Query
- Transaction
4. Hibernate 中的会话是什么?
会话是维护 Java 对象应用程序和数据库之间连接的对象。Session 还具有使用persist()、load()、get()、update()、delete() 等方法从数据库中存储、检索、修改或删除数据的方法。此外,它还具有返回Query 的工厂方法,标准和交易对象。
5. 什么是会话工厂?
SessionFactory 提供了一个Session的实例。它是一个工厂类,它根据配置参数给出 Session对象,以便建立与数据库的连接。
作为一种好的做法,应用程序通常只有一个 SessionFactory 实例。包含有关 ORM 元数据的 SessionFactory 的内部状态是不可变的,即一旦实例被创建,它就不能被更改。
这也提供了获取与类、查询执行等相关的统计信息和元数据等信息的工具。如果启用,它还保存二级缓存数据。
6. 你如何看待“session is a thread-safe object”这句话?
不,Session 不是线程安全对象,这意味着任意数量的线程都可以同时访问它的数据。
7.你能解释一下什么是hibernate中的延迟加载吗?
延迟加载主要用于通过帮助按需加载子对象来提高应用程序性能。
需要注意的是,从Hibernate 3 版本开始,这个功能已经默认开启了。这表示在加载父对象之前不会加载子对象。
8. 一级缓存和二级缓存有什么区别?
Hibernate 有 2 种缓存类型。一级缓存和二级缓存的区别如下:
| 一级缓存 | 二级缓存 |
|---|---|
| 这是 Session 对象的本地对象,不能在多个会话之间共享。 | 此缓存在 SessionFactory 级别维护并在 Hibernate 中的所有会话之间共享。 |
| 默认情况下启用此缓存,并且无法禁用它。 | 默认情况下这是禁用的,但我们可以通过配置启用它。 |
| 一级缓存仅在会话打开前可用,一旦会话关闭,一级缓存将被销毁。 | 二级缓存在应用程序的整个生命周期中都是可用的,它只会在应用程序重新启动时被销毁和重新创建。 |
如果通过调用 get() 方法加载了实体或对象,则 Hibernate 首先检查一级缓存,如果未找到该对象,则在配置后转到二级缓存。如果未找到该对象,则它最终会转到数据库并返回该对象,如果表中没有相应的行,则它返回 null。
9. 你能谈谈 Hibernate 配置文件吗?
Hibernate 配置文件或hibernate.cfg.xml是 Hibernate 中最需要的配置文件之一。默认情况下,此文件位于 src/main/resource 文件夹下。
该文件包含数据库相关配置和会话相关配置。
Hibernate 有助于在 XML 文件(如 hibernate.cfg.xml)或属性文件(如 hibernate.properties)中提供配置。
该文件用于定义以下信息:
- 数据库连接详细信息:驱动程序类、URL、用户名和密码。
- 应用程序中使用的每个数据库必须有一个配置文件,假设我们要连接2个数据库,那么我们必须创建2个不同名称的配置文件。
- Hibernate 属性:方言、show_sql、second_level_cache 和映射文件名。
10.你如何在hibernate中创建一个不可变的类?
Hibernate创建中的不可变类可以采用以下方式。如果我们使用 XML 形式的配置,那么可以通过标记mutable=false 使类不可变。默认值为 true ,表示该类不是默认创建的。
在使用注解的情况下,也可以使用@Immutable注解来创建hibernate中的不可变类。
11. 你能解释一下 Hibernate 继承映射背后的概念吗?
Java 是一种面向对象的编程语言,继承是面向对象原则最重要的支柱之一。为了在 Java 中表示任何模型,继承最常用于简化和简化关系。但是有一个问题。关系数据库不支持继承。它们具有扁平结构。
Hibernate 的继承映射策略解决了如何在 ORM 中Hibernate的问题,试图在 Java 的继承和数据库的平面结构之间映射这个问题。
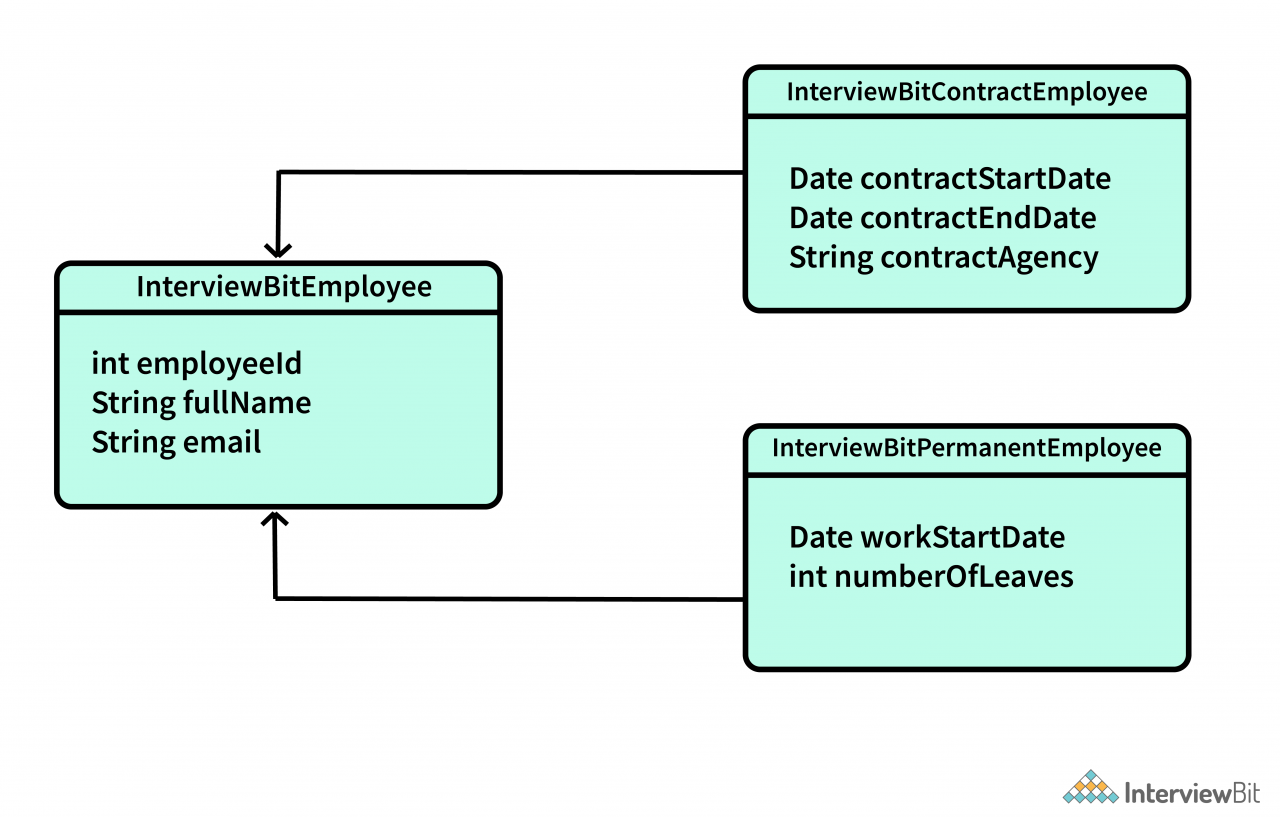
考虑我们必须将InterviewBitEmployee 划分为分别由IBContractEmployee 和IBPermanentEmployee 类表示的Contract 和Permanent 雇员的示例。现在 hibernate 的任务是通过考虑以下限制来表示这 2 种员工类型:
一般员工详细信息在父InterviewBitEmployee 类中定义。
合同和永久雇员特定的详细信息分别存储在 IBContractEmployee 和 IBPermanentEmployee 类中
本系统的类图如下所示:
有不同的继承映射策略可用:
- 单表策略
- 每类一个表策略
- 映射超类策略
- 连接表策略
12、hibernate是否容易受到SQL注入攻击?
SQL 注入 攻击是 Web 安全方面的一个严重漏洞,攻击者可以干扰应用程序/网站对其数据库的查询,从而允许攻击者查看通常无法恢复的敏感数据。它还可以让攻击者修改/删除数据,从而对应用程序行为造成损害。
Hibernate 不提供对 SQL 注入的免疫力。但是,遵循良好做法可以避免 SQL 注入攻击。始终建议遵循以下任何选项:
- 合并使用参数化查询的准备好的语句。
- 使用存储过程。
- 通过进行输入验证来确保数据的完整性。
中级Hibernate常见面试题和答案合集
13.解释hibernate映射文件
Hibernate 映射文件是一个 XML 文件,用于定义实体 bean 字段和相应的数据库列映射。
当项目使用第三方类而无法使用Hibernate提供的 JPA 注释时,这些文件很有用。
在前面的示例中,我们在配置文件中将映射资源定义为“InterviewBitEmployee.hbm.xml”。让我们看看示例 hbm.xml 文件是什么样的:
<?xml version = "1.0" encoding = "utf-8"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<!-- What class is mapped to what database table-->
<class name = "InterviewBitEmployee" table = "InterviewBitEmployee">
<meta attribute = "class-description">
This class contains the details of employees of InterviewBit.
</meta>
<id name = "id" type = "int" column = "employee_id">
<generator class="native"/>
</id>
<property name = "fullName" column = "full_name" type = "string"/>
<property name = "email" column = "email" type = "string"/>
</class>
</hibernate-mapping>14. 支持Hibernate映射的最常用注解有哪些?
Hibernate面试题解析:Hibernate 框架为 org.hibernate.annotations 包中的 JPA 注释和其他有用的注释提供支持。其中一些如下:
- javax.persistence.Entity:这个注解通过使用“@Entity”在模型类上使用,并告诉这些类是实体bean。
- javax.persistence.Table:这个注解用在模型类上,使用“@Table”,告诉类映射到数据库中的表名。
- javax.persistence.Access:用作“@Access”,用于定义字段或属性的访问类型。当未指定任何内容时,采用的默认值是“字段”。
- javax.persistence.Id:这用作“@Id”并用于类中的属性,以指示该属性是 bean 实体中的主键。
- javax.persistence.EmbeddedId:在属性上用作“@EmbeddedId”,表示它是bean实体的复合主键。
- javax.persistence.Column:“@Column”用于定义数据库表中的列名。
- javax.persistence.GeneratedValue:“@GeneratedValue”用于定义用于主键生成的策略。此注释与 javax.persistence.GenerationType 枚举一起使用。
- javax.persistence.OneToOne:“@OneToOne”用于定义两个bean实体之间的一对一映射。类似地,hibernate 提供了 OneToMany、ManyToOne 和 ManyToMany 注释来定义不同的映射类型。
org.hibernate.annotations.Cascade:“@Cascade”注解用于定义两个 bean 实体之间的级联操作。它与 org.hibernate.annotations.CascadeType 枚举一起使用来定义级联的类型。
以下是我们使用了上面列出的注释的示例类:
package com.dev.interviewbit.model;
import javax.persistence.Access;
import javax.persistence.AccessType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.OneToOne;
import javax.persistence.Table;
import org.hibernate.annotations.Cascade;
@Entity
@Table(name = "InterviewBitEmployee")
@Access(value=AccessType.FIELD)
public class InterviewBitEmployee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "employee_id")
private long id;
@Column(name = "full_name")
private String fullName;
@Column(name = "email")
private String email;
@OneToOne(mappedBy = "employee")
@Cascade(value = org.hibernate.annotations.CascadeType.ALL)
private Address address;
//getters and setters methods
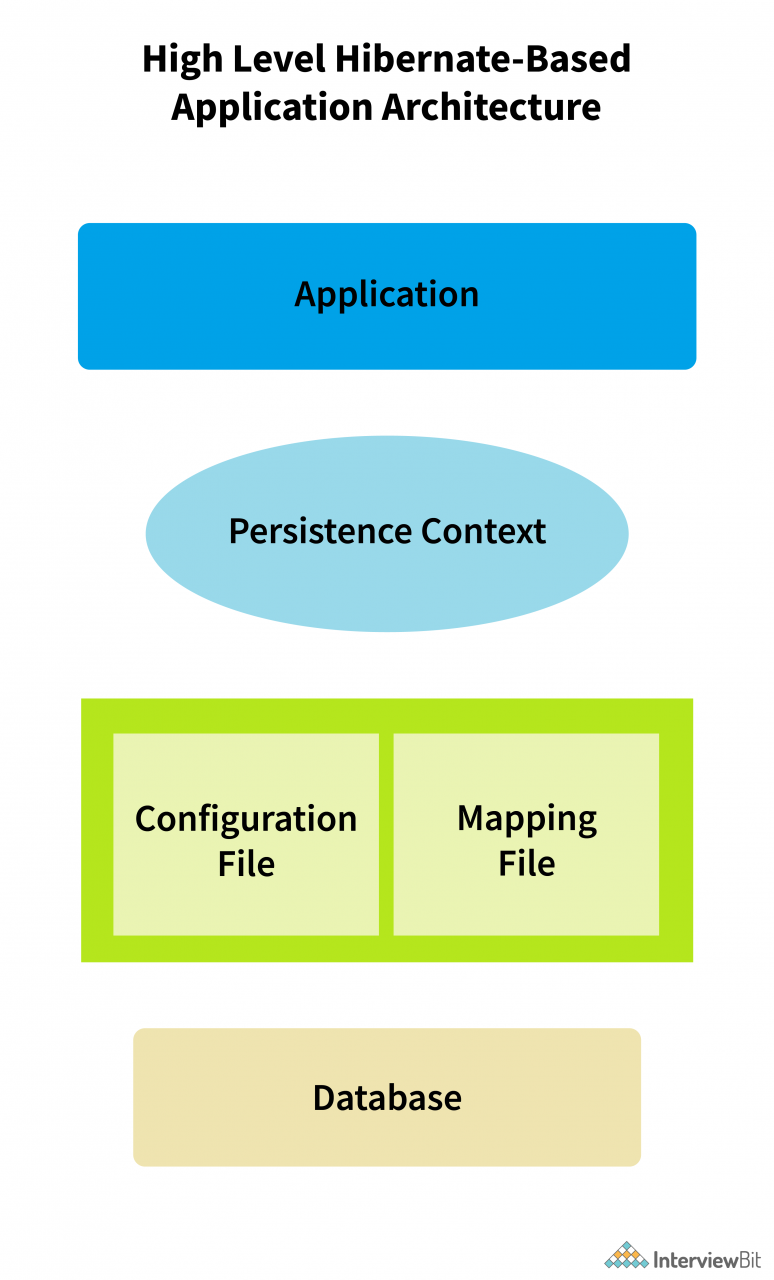
}15.解释Hibernate架构
Hibernate 架构由许多对象组成,例如持久对象、会话工厂、会话、查询、事务等。使用 Hibernate 开发的应用程序主要分为 4 个部分:
- Java应用程序
- Hibernate 框架 - 配置和映射文件
- 内部 API -
- JDBC(Java 数据库连接)
- JTA(Java 事务 API)
- JNDI(Java 命名目录接口)。
- 数据库 - MySQL、PostGreSQL、Oracle 等
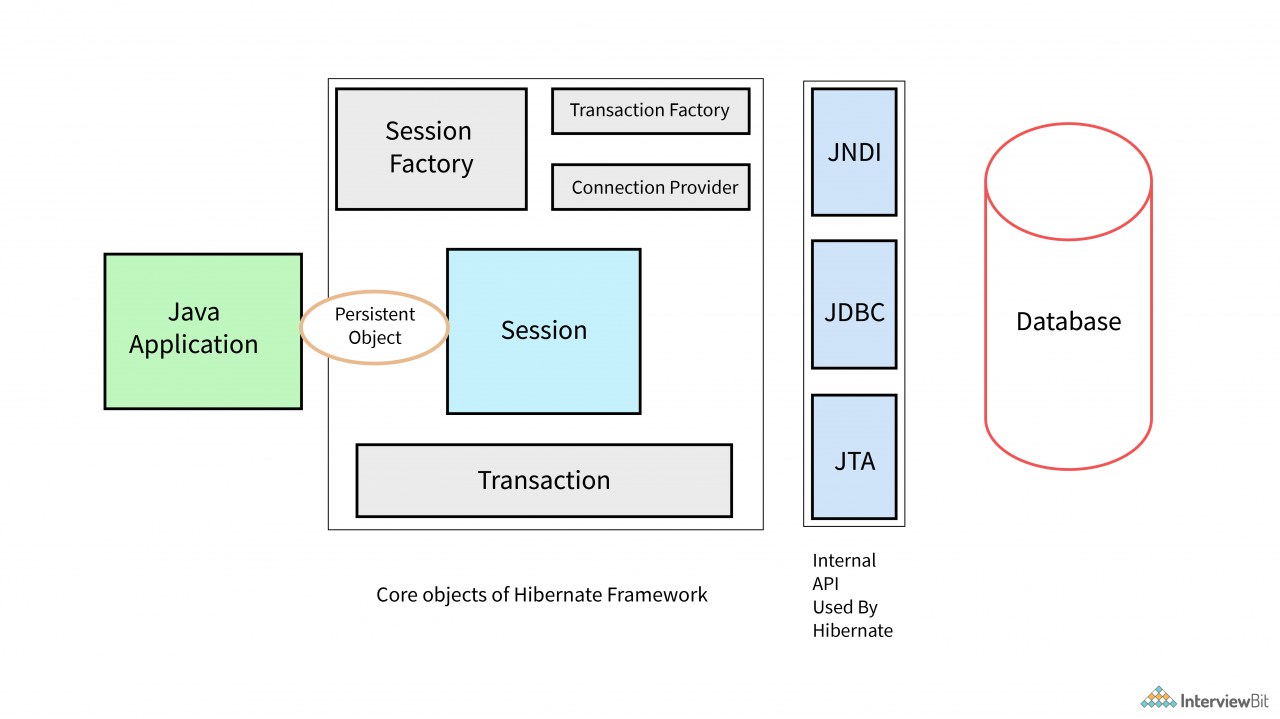
Hibernate 框架的主要元素是:
- SessionFactory:这提供了一个工厂方法来获取会话对象和 ConnectionProvider 的客户端。它保存数据的二级缓存(可选)。
- 会话:这是一个短期对象,充当 java 应用程序对象和数据库数据之间的接口。
- 会话可用于生成事务、查询和条件对象。
- 它还具有强制性的一级数据缓存。
- 事务:此对象指定工作的原子单元并具有对事务管理有用的方法。这是可选的。
- ConnectionProvider:这是 JDBC 连接对象的工厂,它从 DriverManager 提供对应用程序的抽象。这是可选的。
- TransactionFactory:这是 Transaction 对象的工厂。它是可选的。
16. 你能说出getCurrentSession 和openSession 方法的区别吗?
这两种方法都由会话工厂提供。主要区别如下:
| getCurrentSession() | openSession() |
|---|---|
| 此方法返回绑定到上下文的会话。 | 此方法始终打开一个新会话。 |
| 这个会话对象范围属于Hibernate上下文,为了使这个工作Hibernate配置文件必须通过添加<property name = "hibernate.current_session_context_class"> 线程 </property> 来修改。如果没有添加,那么使用该方法会抛出一个 HibernateException。 | 在多线程环境中,必须为每个请求创建一个新的会话对象。因此,你无需配置任何属性即可调用此方法。 |
| 一旦会话工厂关闭,这个会话对象就会关闭。 | 完成所有数据库操作后,开发人员有责任关闭此对象。 |
| 在单线程环境中,此方法比 openSession() 更快。 | 在单线程环境下,比 getCurrentSession()single-threadeda 慢 |
除了这两个方法,还有一个方法 openStatelessSession() ,这个方法返回一个无状态的会话对象。
17. Hibernate常见的面试题有哪些:区分Hibernate会话中的 save() 和 saveOrUpdate() 方法。
这两种方法都将记录保存到数据库中的表中,以防表中没有主键记录。但是,下面列出了这两者之间的主要区别:
| save() | saveOrUpdate() |
|---|---|
| save() 生成一个新的标识符和 INSERT 记录到数据库中 | Session.saveOrUpdate() 可以根据记录的存在插入或更新。 |
| 如果表中已存在主键,则插入失败。 | 如果主键已经存在,则更新记录。 |
| 返回类型是 Serializable,它是新生成的标识符 id 值作为 Serializable 对象。 | saveOrUpdate() 方法的返回类型为 void。 |
| 此方法用于仅将瞬态对象带入持久状态。 | 此方法可以将瞬态(新)和分离(现有)对象都带入持久状态。它通常用于将分离的对象重新附加到会话中 |
显然,saveOrUpdate() 在使用方面更灵活,但它涉及额外的处理,以确定表中是否已存在记录。
18. Hibernate session中get()和load()的区别
这些是从数据库中获取数据的方法。Hibernate 中 get 和 load 的主要区别如下:
| get() | load() |
|---|---|
| 该方法一被调用就从数据库中获取数据。 | 此方法返回一个代理对象并仅在需要时加载数据。 |
| 每次调用该方法时都会命中数据库。 | 只有在真正需要时才会命中数据库,这称为延迟加载,这使该方法更好。 |
| 如果未找到该对象,该方法将返回 null。 | 如果未找到对象,该方法将抛出 ObjectNotFoundException。 |
| 如果我们不确定数据库中是否存在数据,则应使用此方法。 | 当我们确定数据存在于数据库中时,将使用此方法。 |
19. hibernate 中的标准 API 是什么?
Hibernate 中的 Criteria API 帮助开发人员在持久性数据库上构建动态标准查询。Criteria API 是 HQL(Hibernate Query Language)查询的更强大和灵活的替代方案,用于创建动态查询。
此 API 允许以编程方式开发标准查询对象。org.hibernate.Criteria 接口用于这些目的。hibernate 框架的 Session 接口有 createCriteria() 方法,该方法以持久对象的类或其实体名称为参数,并返回执行标准查询的持久对象实例。
它还使合并限制以从数据库中选择性地检索数据变得非常容易。它可以通过使用 add() 方法来实现,该方法接受代表个体限制的 org.hibernate.criterion.Criterion 对象。
用法示例:
返回InterviewBitEmployee实体类的所有数据。
Criteria criteria = session.createCriteria(InterviewBitEmployee.class);
List<InterviewBitEmployee> results = criteria.list();要检索其属性值等于限制的对象,我们使用 Restrictions.eq() 方法。例如,要获取名称为“Hibernate”的所有记录:
Criteria criteria= session.createCriteria(InterviewBitEmployee.class);
criteria.add(Restrictions.eq("fullName","Hibernate"));
List<InterviewBitEmployee> results = criteria.list();要获取属性值为“不等于”限制的对象,我们使用 Restrictions.ne() 方法。例如,要获取所有员工姓名不是 Hibernate 的记录:
Criteria criteria= session.createCriteria(InterviewBitEmployee.class);
criteria.add(Restrictions.ne("fullName","Hibernate"));
List<Employee> results = criteria.list()要检索属性与给定模式匹配的所有对象,我们使用 Restrictions.like()(区分大小写)和 Restrictions.ilike()(区分大小写)
Criteria criteria= session.createCriteria(InterviewBitEmployee.class);
criteria.add(Restrictions.like("fullName","Hib%",MatchMode.ANYWHERE));
List<InterviewBitEmployee> results = criteria.list();同样,它还有其他方法,如 isNull()、isNotNull()、gt()、ge()、lt()、le() 等,用于添加更多种类的限制。必须注意的是,从 Hibernate 5 开始,不推荐使用返回 typeCriteria 对象的函数。Hibernate 5 版本提供了 CriteriaBuilder 和 CriteriaQuery 等接口来达到目的:
javax.persistence.criteria.CriteriaBuilder
javax.persistence.criteria.CriteriaQuery
// Create CriteriaBuilder
CriteriaBuilder builder = session.getCriteriaBuilder();
// Create CriteriaQuery
CriteriaQuery<YourClass> criteria = builder.createQuery(YourClass.class);为了在 CriteriaQuery 中引入限制,我们可以使用 CriteriaQuery.where 方法,它类似于在 JPQL 查询中使用 WHERE 子句。
20.什么是HQL?
Hibernate 查询语言 (HQL)用作SQL的扩展。无需编写复杂的查询即可对关系数据库执行复杂的操作,非常简单、高效且非常灵活。HQL 是查询语言的面向对象表示,即我们不使用表名,而是使用类名,这使得该语言独立于任何数据库。
这利用了 Hibernate 提供的 Query 接口。Query 对象是通过调用hibernate Session 接口的createQuery() 方法获得的。
以下是查询接口最常用的方法:
- public int executeUpdate() :此方法用于运行更新/删除查询。
- public List list():此方法将结果作为列表返回。
- public Query setFirstResult(int rowNumber):此方法接受行号作为参数,使用该参数将检索该行号的记录。
- public Query setMaxResult(int rowsCount):此方法在从数据库中检索时返回最大值,直到指定的 rowCount。
- public Query setParameter(int position, Object value):此方法将值设置为特定位置的属性/列。此方法遵循查询参数的 JDBC 样式。
- public Query setParameter(String name, Object value):此方法将值设置为命名查询参数。
示例:要从 InterviewBitEmployee 表中获取所有记录的列表:
Query query=session.createQuery("from InterviewBitEmployee");
List<InterviewBitEmployee> list=query.list();
System.out.println(list.get(0));21. 你能谈谈一对多关联吗?我们如何在 Hibernate 中使用它们?
在一个一对多关联是最常用的,其指示一个对象被链接/与多个对象相关联。
例如,一个人可以拥有多辆汽车。
在 Hibernate 中,我们可以通过在模型类中使用 @OnetoMany 的 JPA 注释来实现这一点。考虑上面有多个汽车的人的例子,如下所示:
@Entity
@Table(name="Person")
public class Person {
//...
@OneToMany(mappedBy="owner")
private Set<Car> cars;
// getters and setters
}在 Person 类中,我们将汽车的属性定义为具有 @OneToMany 关联。Car 类将拥有由 Person 类中的 mappingBy 变量使用的属性。Car类如下图所示:
@Entity
@Table(name="Car")
public class Car {
// Other Properties
@ManyToOne
@JoinColumn(name="person_id", nullable=false)
private Person owner;
public Car() {}
// getters and setters
}@ManyToOne 注释表明一个实体的许多实例被映射到另一个实体的一个实例——一个人的许多汽车。
22. 什么是多对多关联?
多对多关联表示两个实体的实例之间存在多重关系。我们可以举多个学生参加多门课程的例子,反之亦然。
由于学生和课程实体都通过外键相互引用,我们通过创建一个单独的表来保存这些外键,从而在技术上表示这种关系。
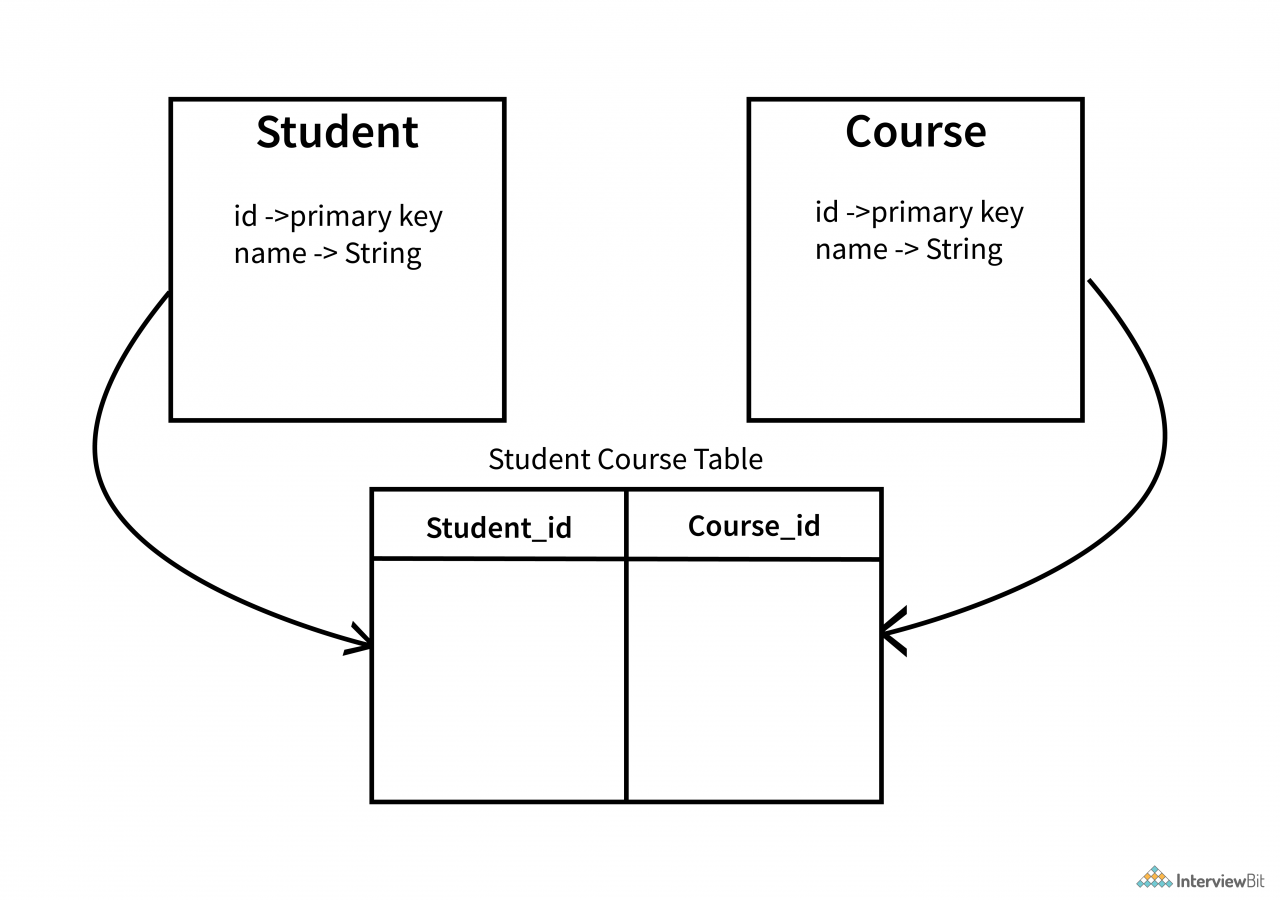
在这里,Student-Course 表称为连接表,其中 student_id 和 course_id 将构成复合主键。
23. hibernate 中的 session.lock() 方法是做什么的?
Hibernate面试题解析:session.lock()方法用于将分离的对象重新附加到会话。session.lock()方法不会检查数据库和持久化上下文中的对象之间的任何数据同步,因此这种重新附加可能会导致数据同步丢失。
24.什么是hibernate缓存?
Hibernate 缓存是一种通过在缓存中池化对象来提高应用程序性能的策略,以便更快地执行查询。在获取多次执行的相同数据时,Hibernate 缓存特别有用。我们可以从缓存中访问数据,而不是访问数据库。这导致应用程序的吞吐量时间减少。
Hibernate缓存的类型
一级缓存:
- 默认情况下启用此级别。
- 第一级缓存驻留在Hibernate会话对象中。
- 由于它属于会话对象,因此存储在此处的数据范围不会对整个应用程序可用,因为一个应用程序可以使用多个会话对象。
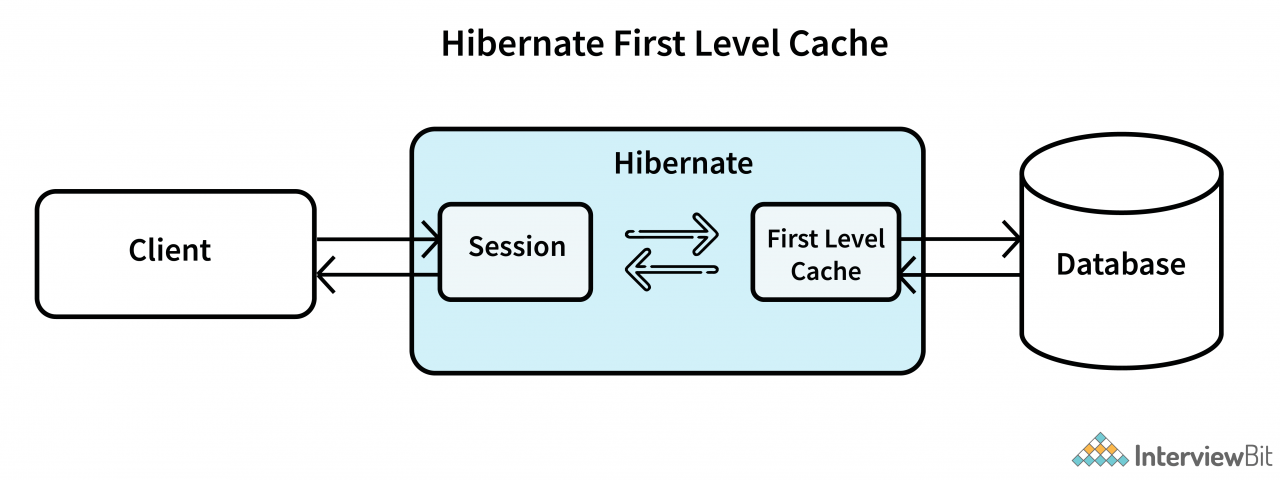
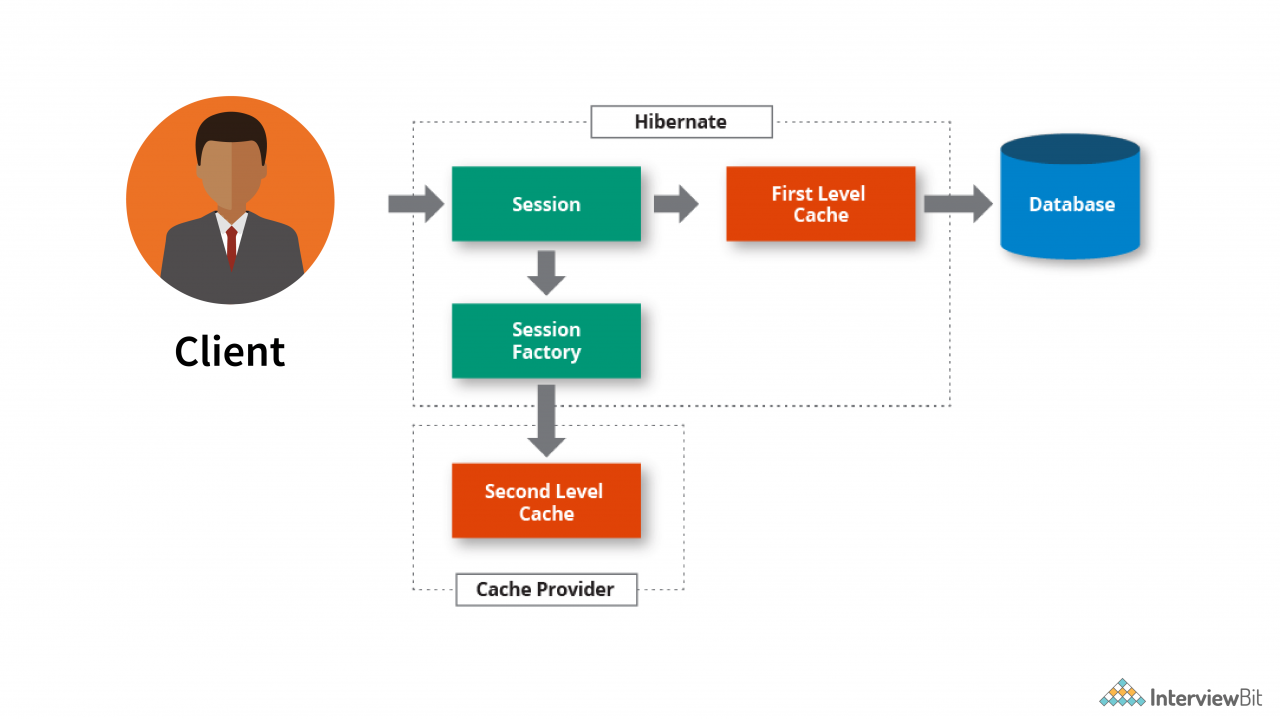
二级缓存:
- 二级缓存驻留在 SessionFactory 对象中,因此,整个应用程序都可以访问数据。
- 这在默认情况下不可用。它必须显式启用。
- EH(Easy Hibernate)缓存、Swarm 缓存、OS 缓存、JBoss 缓存是一些示例缓存提供程序。
25、hibernate session的merge()方法什么时候有用?
Merge() 方法可用于更新现有值。该方法的特殊之处在于,一旦现有值被更新,该方法就会从实体对象创建一个副本并返回它。此结果对象进入持久上下文,然后跟踪任何更改。最初使用的对象不被跟踪。
26. 集合映射可以使用一对一和多对一关联来完成。你怎么认为?
错误,集合映射仅适用于一对多和多对多关联。
27、你能说出Query的setMaxResults()和setFetchSize()的区别吗?
setMaxResults() 函数的工作方式类似于 SQL 中的 LIMIT。在这里,我们设置了我们想要返回的最大行数。此方法由所有数据库驱动程序实现。
setFetchSize() 用于优化 Hibernate 将结果发送给调用者的方式,例如:结果是否被缓冲,它们是否以不同大小的块发送等。并非所有数据库驱动程序都实现了此方法。
28. Hibernate 是否支持原生 SQL 查询?
是的,它确实。Hibernate 提供了 createSQLQuery() 方法让开发者直接调用原生 SQL 语句并返回一个 Query 对象。
考虑你想要获取全名为“Hibernate”的员工数据的示例。我们不想使用基于 HQL 的功能,而是想编写自己的 SQL 查询。在这种情况下,代码将是:
Query query = session.createSQLQuery( "select * from interviewbit_employee ibe where ibe.fullName = :fullName")
.addEntity(InterviewBitEmployee.class)
.setParameter("fullName", "Hibernate"); //named parameters
List result = query.list();或者,使用 NamedQueries 时也可以支持本机查询。
有经验的Hibernate常见面试题和答案合集
29. 当实体 bean 中没有 no-args 构造函数时会发生什么?
当调用 get() 或 load() 方法时,Hibernate 框架在内部使用反射 API 来创建实体 bean 实例。使用了 Class.newInstance() 方法,该方法需要存在无参数构造函数。当我们在实体 bean 中没有这个构造函数时,hibernate 无法实例化 bean,因此它抛出 HibernateException。
30. 我们可以将 Entity 类声明为 final 吗?
不,我们不应该定义实体类 final,因为 hibernate 使用代理类和对象来延迟加载数据,并且仅在绝对需要时才访问数据库。这是通过扩展实体 bean 来实现的。如果实体类(或 bean)是最终的,那么它就不能被扩展,因此不能支持延迟加载。
31. 持久化实体的状态是什么?
持久实体可以存在于以下任何一种状态:
短暂的:
- 这个状态是任何实体对象的初始状态。
- 一旦创建了实体类的实例,则称该对象已进入瞬态。这些对象存在于堆内存中。
- 在此状态下,对象未链接到任何会话。因此,它与任何数据库无关,因为数据对象的任何更改都不会影响数据库中的数据。
InterviewBitEmployee employee=new InterviewBitEmployee(); //The object is in the transient state.
employee.setId(101);
employee.setFullName("Hibernate");
employee.setEmail("hibernate@interviewbit.com");执着的:
- 每当对象与会话链接或关联时,就会进入此状态。
- 每当我们在数据库中保存或持久化对象时,就称该对象处于持久化状态。每个对象对应于数据库表中的行。在此状态下对数据的任何修改都会导致数据库中的记录发生更改。
可以对持久化对象使用以下方法:
session.save(record);
session.persist(record);
session.update(record);
session.saveOrUpdate(record);
session.lock(record);
session.merge(record);独立:
- 只要会话关闭或缓存被清除,对象就会进入此状态。
- 由于对象不再是会话的一部分,对象中的任何更改都不会反映在数据库的相应行中。但是,它仍然会在数据库中具有其表示形式。
- 如果开发人员想要保留此对象的更改,则必须将其重新附加到Hibernate会话。
- 为了实现重新附加,我们可以通过使用分离对象的引用在新会话上使用方法 load()、merge()、refresh()、update() 或 save() 方法。
每当调用以下任何方法时,对象都会进入此状态:
session.close();
session.clear();
session.detach(record);
session.evict(record);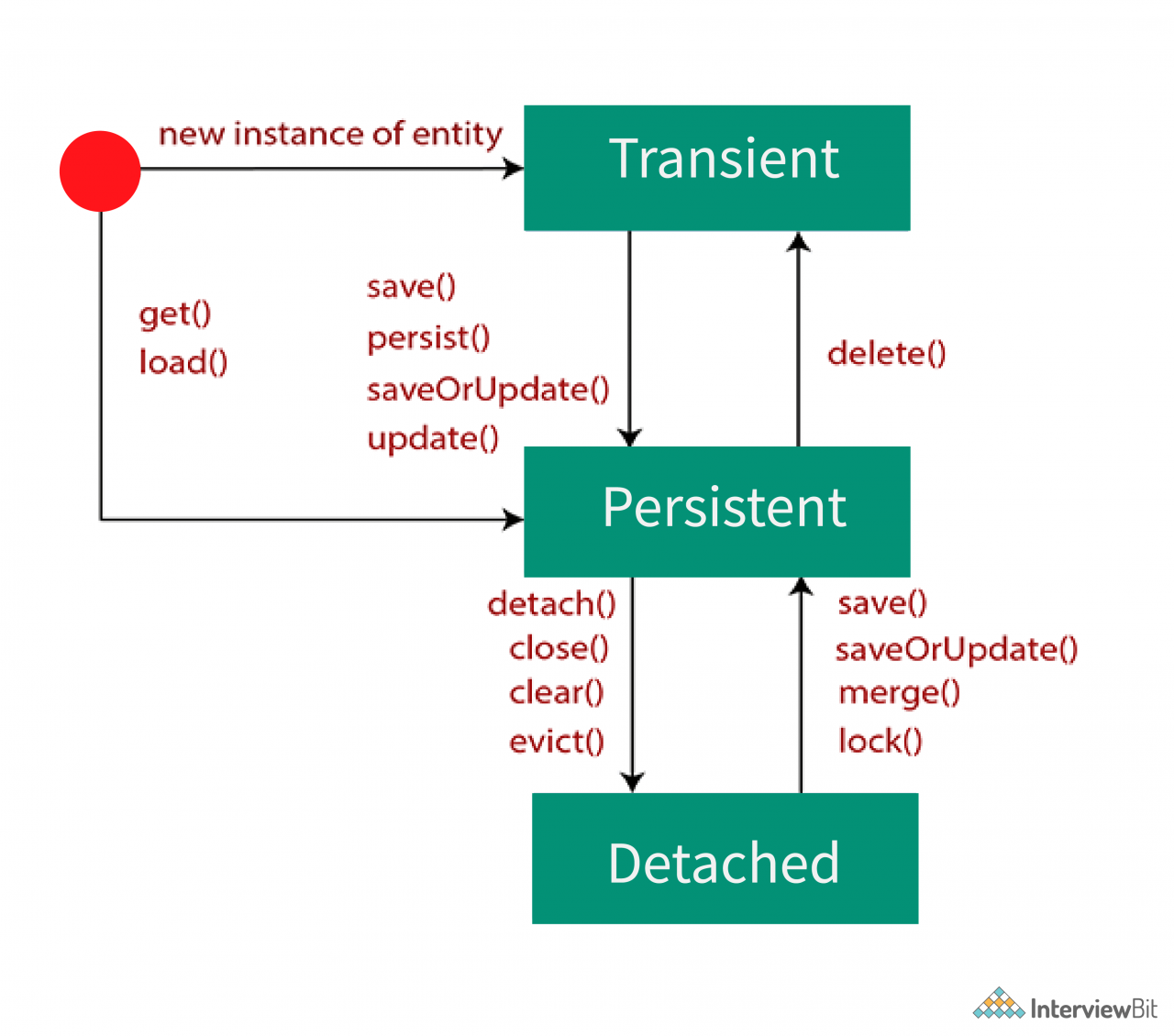
32. 解释查询缓存
Hibernate 框架为查询的结果集提供了一个称为缓存区域的可选功能。必须在代码中完成其他配置才能启用此功能。查询缓存对于那些最常使用相同参数调用的查询很有用。这提高了数据检索的速度,并大大提高了常见重复查询的性能。
这不会缓存结果集中实际实体的状态,而只会存储标识符值和值类型的结果。因此,查询缓存应始终与二级缓存结合使用。
配置:
在 hibernate 配置 XML 文件中,将 use_query_cache 属性设置为 true,如下所示:
<property name="hibernate.cache.use_query_cache">true</property>
In the code, we need to do the below changes for the query object:
Query query = session.createQuery("from InterviewBitEmployee");
query.setCacheable(true);
query.setCacheRegion("IB_EMP");33. Hibernate常见的面试题有哪些:你能谈谈 Hibernate 中的 N+1 SELECT 问题吗?
N+1 SELECT 问题是由于使用了延迟加载和按需获取策略的结果。让我们举个例子。如果你有一个 N 项列表,并且列表中的每个项都依赖于另一个对象的集合,例如出价。为了在使用延迟加载策略时找到每个项目的最高出价,hibernate 必须首先触发 1 次查询以加载所有项目,然后再触发 N 次查询以加载每个项目的大项。因此,hibernate 实际上最终会执行 N+1 个查询。
34. 如何解决Hibernate中的N+1 SELECT问题?
解决 N+1 SELECT 问题所遵循的一些策略是:
- 分批预取记录,这有助于我们将 N+1 的问题减少到 (N/K) + 1,其中 K 是指批次的大小。
- 子选择获取策略
- 作为最后的手段,尽量避免或完全禁用延迟加载。
35、hibernate有哪些并发策略?
并发策略是负责从缓存中存储和检索项目的中介。在启用二级缓存的同时,开发人员有责任提供要实现的策略来决定每个持久类和集合。
以下是使用的并发策略:
- 事务性:这用于更新最有可能导致陈旧数据的数据,并且这种预防对应用程序最重要。
- 只读:当我们不希望数据被修改时使用,只能用于参考数据。
- 读写:在这里,数据主要是读取,并且在防止陈旧数据至关重要时使用。
- 非严格读写:使用此策略将确保数据库和缓存之间不会有任何一致性。当可以修改数据并且陈旧数据不是关键问题时,可以使用此策略。
36. 什么是单表策略?
单表策略是执行继承映射的Hibernate策略。该策略被认为是所有其他现有策略中最好的。在这里,继承数据层次结构通过使用确定记录属于哪个类的鉴别器列存储在单个表中。
对于上面 Hibernate 继承映射问题中定义的示例,如果我们遵循这种单表策略,那么所有永久和合同员工的详细信息都存储在数据库中的一个名为 InterviewBitEmployee 的表中,并且员工将通过使用名为employee_type 的鉴别器列。
Hibernate 提供了以策略为参数的@Inheritance 注解。这用于定义我们将使用的策略。通过赋予它们值,InheritanceType.SINGLE_TABLE 表示我们正在使用单表策略进行映射。
- @DiscriminatorColumn 用于指定实体对应的数据库中表的鉴别器列是什么。
- @DiscriminatorValue 用于指定什么值区分两种类型的记录。
代码片段将是这样的:
InterviewBitEmployee 类:
@Entity
@Table(name = "InterviewBitEmployee")
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "employee_type")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitEmployee {
@Id
@Column(name = "employee_id")
private String employeeId;
private String fullName;
private String email;
}InterviewBitContractEmployee 类:
@Entity
@DiscriminatorValue("contract")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitContractEmployee extends InterviewBitEmployee {
private LocalDate contractStartDate;
private LocalDate contractEndDate;
private String agencyName;
}InterviewBitPermanentEmployee 类:
@Entity
@DiscriminatorValue("permanent")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitPermanentEmployee extends InterviewBitEmployee {
private LocalDate workStartDate;
private int numberOfLeaves;
}37. 你能谈谈 Table Per Class 策略吗?
Hibernate面试题解析:Table Per Class Strategy 是另一种类型的继承映射策略,其中层次结构中的每个类都有一个对应的映射数据库表。例如,InterviewBitContractEmployee 类详细信息存储在interviewbit_contract_employee 表中,InterviewBitPermanentEmployee 类详细信息分别存储在interviewbit_permanent_employee 表中。由于数据存储在不同的表中,因此不需要像在单表策略中那样使用鉴别器列。
Hibernate 提供了以策略为参数的@Inheritance 注解。这用于定义我们将使用的策略。通过给它们值,InheritanceType.TABLE_PER_CLASS,它表示我们正在使用一个表每个类的映射策略。
代码片段如下所示:
InterviewBitEmployee 类:
@Entity(name = "interviewbit_employee")
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitEmployee {
@Id
@Column(name = "employee_id")
private String employeeId;
private String fullName;
private String email;
}InterviewBitContractEmployee 类:
@Entity(name = "interviewbit_contract_employee")
@Table(name = "interviewbit_contract_employee")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitContractEmployee extends InterviewBitEmployee {
private LocalDate contractStartDate;
private LocalDate contractEndDate;
private String agencyName;
}InterviewBitPermanentEmployee 类:
@Entity(name = "interviewbit_permanent_employee")
@Table(name = "interviewbit_permanent_employee")
@NoArgsConstructor
@AllArgsConstructor
public class InterviewBitPermanentEmployee extends InterviewBitEmployee {
private LocalDate workStartDate;
private int numberOfLeaves;
}缺点:
- 由于需要额外的连接来获取数据,这种类型的策略提供的性能较低。
- 并非所有 JPA 提供程序都支持此策略。
- 在某些情况下,排序很棘手,因为它是基于类完成的,然后是根据排序标准完成的。
38. Hibernate常见的面试题有哪些:你能谈谈命名 SQL 查询吗?
命名 SQL 查询是以表的形式表示的表达式。在这里,可以指定从一个或多个数据库中的一个或多个表中选择/检索行和列的 SQL 表达式。这就像对查询使用别名一样。
在Hibernate中,我们可以使用@NameQueries 和@NameQuery 注释。
- @NameQueries 注解用于定义多个命名查询。
- @NameQuery 注释用于定义单个命名查询。
代码片段:我们可以定义命名查询,如下所示
@NamedQueries(
{
@NamedQuery(
name = "findIBEmployeeByFullName",
query = "from InterviewBitEmployee e where e.fullName = :fullName"
)
}
) :fullName 指的是程序员定义的参数,可以在使用命名查询时使用 query.setParameter 方法设置。
用法:
TypedQuery query = session.getNamedQuery("findIBEmployeeByFullName");
query.setParameter("fullName","Hibernate");
List<InterviewBitEmployee> ibEmployees = query.getResultList();getNamedQuery 方法获取命名查询的名称并返回查询实例。
39. NamedQuery 有什么好处?
为了理解 NamedQuery 的好处,我们先来了解一下 HQL 和 SQL 的缺点。将 HQL 和 SQL 分散在数据访问对象中的主要缺点是它使代码不可读。因此,作为一种好的做法,建议将所有 HQL 和 SQL 代码组合在一个地方,并在实际数据访问代码中仅使用它们的引用。为了实现这一点,Hibernate 为我们提供了命名查询。
命名查询是静态定义的查询,具有预定义的不可更改的查询字符串。它们在创建会话工厂时进行验证,从而使应用程序在出现错误时快速失败。
Hibernate常见面试题和答案合集结论
Hibernate 是最强大的开源 ORM 工具,用于在运行时将 java 对象与数据库结构进行映射。由于其抽象性质,它在软件开发人员中越来越受欢迎,因为它允许开发人员通过独立于数据库并只关注应用程序业务逻辑来继续应用程序开发。

