
本文是Warning: DOMDocument::loadHTML()的解决办法介绍:带你了解在 DOMDocument 中使用 HTML5 标签时如何处理 PHP 中的这个乏味异常。
DOM Document 是一个 PHP 类,它表示整个 HTML 或 XML 文档并充当文档树的根。它用于轻松创建或加载 HTML 或 XML,并根据你的意愿对其进行修改、搜索元素等。在过去的日子里,我需要检索加载在 HTML 文档中的图像的源 (URL),并决定在 PHP 中使用提到的类和 DomXPath 轻松实现这一点。不幸的是,在加载非常基本和标准的 HTML 5 时,我奇怪地发现了以下问题,尽管这会触发异常,但该消息明确提及警告:
Warning: DOMDocument::loadHTML(): Tag 'figure, nav, section' invalid
那么我们如何解决异常Warning: DOMDocument::loadHTML()呢?下面我们先介绍异常出现的情况,然后介绍解决这个问题的两个方法。
为什么会出现这个异常
执行以下 PHP 代码将触发上述“警告”,从而使你的代码出错:
<?php
// An example HTML document:
$html = <<<'HTML'
<!DOCTYPE html>
<html>
<head>
<title>Testing</title>
</head>
<body id='foo'>
<h1>Hello World</h1>
<figure class="image">
<img src="https://ourcodeworld.com/public-media/articles/cookielessdomain-5fa35742d669f.png" alt="解决PHP 7异常:Warning: DOMDocument::loadHTML(): Tag 'figure, nav, section' invalid" />
<figcaption>Caption</figcaption>
</figure>
</body>
</html>
HTML;
$domDocument = new \DOMDocument();
$domDocument->loadHTML($html);
$xpath = new \DOMXPath($domDocument);
foreach($xpath->query("//img/@src") as $item){
echo "<br> Image: ". basename($item->value);
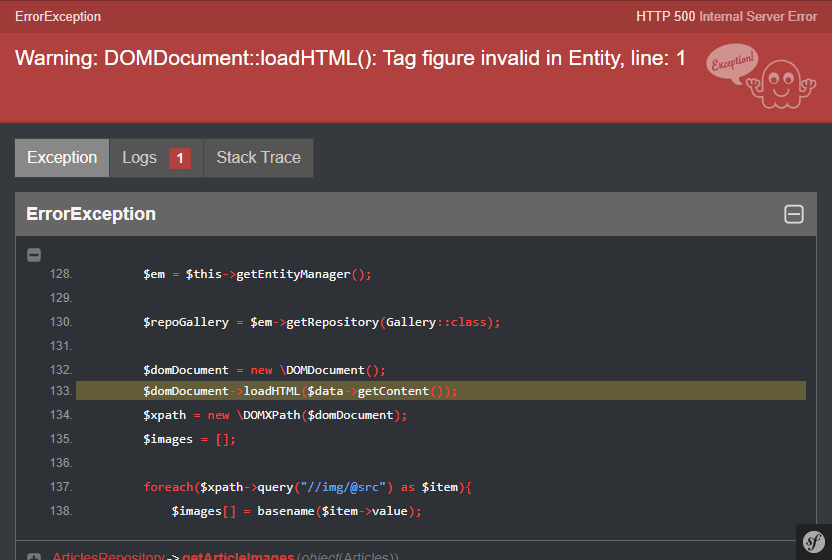
}然后,在浏览器上会出现以下错误:
Warning: DOMDocument::loadHTML(): Tag figure invalid in Entity, line: 7 in \demo.php on line 27
Warning: DOMDocument::loadHTML(): Tag figcaption invalid in Entity, line: 9 in \demo.php on line 27
Image: cookielessdomain-5fa35742d669f.png我在尝试搜索 HTML 结构中的图像 URL 以获取每个图像的 src 属性值时发现了这个错误。失败是由 DOMDocument 类本身造成的。在我们的 HTML 中,我们确实有 2 个 HTML5 实体(<figure>和<figcaption>),它们无法被 PHP 的旧 DOMDocument 解析器识别。
解决方案
此问题有两种可能的解决方案:
A. 忽略警告
Warning: DOMDocument::loadHTML()的解决办法:你可以尝试的第一件事是简单地忽略这些抑制它们的警告,强制 libxml 在内部处理错误libxml_use_internal_errors(你可以使用一些代码检索它们),然后按照以下示例中的指定清除它们:
// 1. Create document
$domDocument = new \DOMDocument();
// 2. Handle errors internally
libxml_use_internal_errors(true);
// 3. Load your HTML 5
$domDocument->loadHTML($html);
// 4. Do what you need to do without the warning ...
// 5. Clear errors
libxml_clear_errors();由于错误本身是由底层 libxml 库引起的,理论上,如果我们忽略提到的异常,你的整个代码(或至少其中的很大一部分)无论如何都可以工作。如果你的代码仍然按预期工作,那么你无需尝试第二种可能的解决方案。如果你需要了解错误或警告,你可以获取它们并使用它们执行你需要的操作:
// 1. Create document
$domDocument = new \DOMDocument();
// 2. Handle errors internally
libxml_use_internal_errors(true);
// 3. Load your HTML 5
$domDocument->loadHTML($html);
// 4. Do what you need to do without the warning ...
$xpath = new \DOMXPath($domDocument);
foreach($xpath->query("//img/@src") as $item){
echo "<br> Image: ". basename($item->value);
}
// 5. Clear errors
$errors = libxml_get_errors();
// 6. If you need to know about the errors or warnings
foreach ($errors as $error)
{
/* @var $error LibXMLError */
/*
each $error variable contains a LibXMLError object with the following properties
array(
'level' => 2,
'code' => 801,
'column' => 28,
'message' => 'Tag figcaption invalid',
'file' => '',
'line' => 10,
)
*/
}但是,如果由于某种原因,在忽略警告后,你的代码没有按预期运行,那么你可以尝试我们针对此问题的第二种可能的解决方案。
B. 使用另一个解析器(DomCrawler)
如何解决异常Warning: DOMDocument::loadHTML()?在这个问题的最后,你需要用 DOM 实现一些东西,可能是在它内部搜索而不是修改它,所以如果你依赖一个支持 HTML5 的 DOM 解析器,你的问题很有可能得到解决,那就是Symfony 的 DomCrawler 库出现了。DomCrawler 组件简化了 HTML 和 XML 文档的 DOM 导航。
要使用此库,请使用 Composer 继续安装:
composer require symfony/dom-crawler有关该库的更多信息,请访问此处的官方 Github 存储库或此处的官方网站。
安装后,你应该能够在代码中包含该库。下面的代码片段显示了我们在原始代码中使用 DOMXPath 搜索提供的 HTML 5 上的图像的基本相同的操作:
<?php
require 'vendor/autoload.php';
use Symfony\Component\DomCrawler\Crawler;
// An example HTML document:
$html = <<<'HTML'
<!DOCTYPE html>
<html>
<head>
<title>Testing</title>
</head>
<body id='foo'>
<h1>Hello World</h1>
<figure class="image">
<img src="https://ourcodeworld.com/public-media/articles/cookielessdomain-5fa35742d669f.png" alt="解决PHP 7异常:Warning: DOMDocument::loadHTML(): Tag 'figure, nav, section' invalid" />
<figcaption>Caption</figcaption>
</figure>
</body>
</html>
HTML;
// 1. Create an instance of the crawler with our HTML
$crawler = new Crawler($html);
// 2. Search for the images and src attribute using the XPath filter and store them into an array
$images = $crawler->filterXPath('//img/@src')->each(function (Crawler $node, $i) {
return $node;
});
// 3. Iterate over the found images and obtain what we want
foreach($images as $image){
echo "Image: "$image->text();
}应该在浏览器中输出:
Image: https://ourcodeworld.com/public-media/articles/cookielessdomain-5fa35742d669f.png如你所见,我们的要求已解决,并且在爬虫中加载 HTML 时没有出现未知实体的警告。
快乐编码❤️!

